According to the Uptime Institute's 2024 Global Data Center Survey, 54% of operators reported their most recent significant outage cost more than $100,000, with 20% exceeding $1 million. That's the operational reality of aging infrastructure—and it's exactly what AWS cloud migration is designed to prevent.
This guide is written for IT leaders, cloud architects, and enterprise technology teams who need a clear, operational walkthrough of how on-premise-to-AWS migration is actually planned and executed—not a conceptual overview, but a step-by-step lifecycle from initial discovery through post-migration optimization.
Key Takeaways
- On-premise to AWS migration moves servers, databases, and applications from local data centers to AWS-managed, scalable cloud infrastructure
- AWS native tools—MGN, DMS, Control Tower, and CloudWatch—automate discovery, replication, and monitoring across each migration phase
- The migration lifecycle follows: Assess → Strategize → Build Landing Zone → Migrate → Test → Cut Over → Optimize
- Choosing the right migration strategy per workload (rehost, replatform, refactor, retire) drives every downstream decision in cost, timeline, and complexity
- Most migration failures trace back to skipped discovery, poor wave planning, or no post-migration cost governance
What Is On-Premise to AWS Cloud Migration?
On-premise to AWS cloud migration is the systematic process of moving IT assets—servers, databases, applications, and data—from physical, on-site infrastructure to AWS's cloud environment, where they run on managed, scalable, and remotely accessible resources.
The intended outcome is straightforward: organizations shift from owning and maintaining hardware to consuming elastic cloud resources on a pay-as-you-go model. That shift gives organizations access to AWS-native services like EC2, RDS, S3, and Lambda without the capital overhead of procuring and operating physical hardware.
The scope is what distinguishes migration from a simple backup or file transfer. It involves:
- Moving live workloads with minimal disruption to users
- Reconfiguring application dependencies to resolve correctly in the new environment
- Establishing secure hybrid connectivity between on-premise and AWS during the transition
- Validating that applications perform correctly in cloud infrastructure before decommissioning source servers
Organizations that treat migration as "copying VMs to the cloud" consistently run into dependency failures and unplanned downtime. Treating it as a structured engineering program — with defined phases, validation checkpoints, and rollback plans — is what keeps those risks manageable.
Why Migrate from On-Premise to AWS?
The Operational Case
On-premise environments carry structural constraints that cloud removes:
- Scaling requires hardware procurement cycles measured in weeks or months
- Server refreshes, storage upgrades, and networking gear demand significant upfront capital
- Geographic failover requires a second physical data center to deliver redundancy
- Patching, hardware monitoring, and vendor support consume IT team bandwidth year-round
AWS addresses each of these through elastic infrastructure, managed services, and 32 geographic regions with multiple Availability Zones. Multi-AZ deployment delivers high availability without a second data center, managed services like RDS handle patching automatically, and compute scales in minutes.
What Goes Wrong Without It
Those operational constraints don't just slow teams down — when hardware fails, they cause extended, expensive downtime. Uptime Institute's 2024 research found that four in five respondents believed their most recent serious outage could have been prevented through better management, processes, or configuration. That's an operational discipline problem that managed cloud infrastructure largely solves.
For regulated industries—BFSI, healthcare, manufacturing—AWS also provides compliance-ready infrastructure certified for SOC 2, ISO 27001, PCI DSS, and more, which reduces the architecture burden for teams building compliant systems.
Cloud Migration Strategies: Choosing the Right Approach
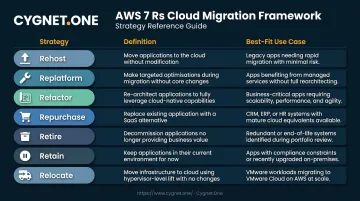
AWS documents seven migration strategies—commonly called the 7 Rs: Rehost, Replatform, Refactor, Repurchase, Retire, Retain, and Relocate. Choosing the right strategy per workload is the most consequential decision in any migration plan. No single approach works across an entire application portfolio.
| Strategy | What It Means | Best For |
|---|---|---|
| Rehost | Lift-and-shift to AWS with no code changes | Legacy apps with stable workloads |
| Replatform | Minor optimizations (e.g., self-managed DB → RDS) without redesign | Apps that can benefit from managed services quickly |
| Refactor | Redesign for cloud-native patterns (containers, microservices, serverless) | Business-critical apps where performance and cost matter most |
| Repurchase | Replace with SaaS alternative | Legacy software with a better commercial replacement |
| Retire | Decommission apps no longer needed | Redundant or unused systems |
| Retain | Keep in place (compliance, latency, or dependency constraints) | Apps not yet ready for cloud |
AWS notes that rehost and replatform are the most common strategies in large-scale migrations, while refactoring is less common at scale because it requires substantially more engineering effort and timeline.
That guidance reflects a real constraint: most enterprise migrations combine multiple strategies across the portfolio. Teams determine the allocation during the workload assessment phase—using AWS Application Discovery Service to map dependencies and performance data—not by assumption.
How to Migrate from On-Premise to AWS: A Step-by-Step Walkthrough
Step 1: Assess and Discover Your Current Environment
Before any workload moves, you need a complete inventory of what exists: all servers, VMs, databases, applications, network dependencies, and traffic patterns.
AWS Application Discovery Service automates this by deploying lightweight agents on source servers that collect system configuration, performance utilization, running processes, and TCP network connections. The Discovery Agent uses approximately 15-second polling intervals and sends data to AWS at regular intervals. For VMware environments, the Agentless Collector deploys via vCenter and collects the same data without agent installation on each VM.
The assessment output should include:
- A full server and application inventory with utilization data
- Inter-application dependency maps that reveal migration sequencing constraints
- An initial TCO comparison between on-premise and AWS (use AWS Migration Evaluator for this—it analyzes 5-minute utilization samples and produces 1-year and 3-year cost projections)
- A prioritized workload list with complexity ratings
This data drives every downstream decision: wave grouping, strategy selection, and right-sizing. Teams that skip the assessment phase routinely over-provision instances and discover hidden dependencies mid-cutover.
Step 2: Plan Your Migration Strategy and AWS Architecture
Once workloads are inventoried, assign each application a migration strategy from the 7 Rs and group workloads into migration waves—batches of related applications migrated together. AWS guidance positions migration waves at roughly 4 to 8 weeks in duration.
Wave sequencing follows a clear principle: lower-risk, non-critical workloads migrate first. Business-critical systems go last, after the team has built operational confidence and resolved early-wave surprises.
Architecture planning produces:
- Target VPC design: subnets, Availability Zones, routing tables, internet gateways
- IAM roles and permissions: defined before any workload arrives
- Security group rules: configured per application tier
- Network connectivity: AWS Direct Connect for high-volume, predictable migration traffic; Site-to-Site VPN (supporting up to 1.25 Gbps per tunnel, 5 Gbps on Transit Gateway) for faster setup or encrypted backup paths
- Disaster recovery configuration: multi-AZ deployment, backup policies, failover targets
For complex enterprise environments with SAP, Oracle ERP, or multi-system integrations, dependency mapping at this stage determines your migration sequencing. Cygnet.One's ORBIT framework handles this in the Roadmap phase, producing architecture blueprints and migration wave logic built from actual dependency data rather than estimated relationships.
Step 3: Set Up Your AWS Landing Zone and Infrastructure
No workload should migrate into an unprepared environment. The landing zone is built first.
AWS Control Tower sets up a secure, multi-account AWS environment using AWS Organizations, AWS Service Catalog, and IAM Identity Center. The default structure includes a Security OU with shared Log Archive and Audit accounts, plus separate accounts for production, staging, development, and sandbox workloads.
Core landing zone components to configure:
- VPC architecture: public and private subnets across multiple Availability Zones
- Network connectivity: Direct Connect or VPN via AWS Transit Gateway (the regional hub connecting VPCs and on-premise networks)
- Centralized logging: AWS CloudTrail and AWS Config enabled across all accounts
- Security baseline: encryption policies, IAM access controls, and compliance guardrails (preventive, detective, and proactive) via Control Tower
- Identity federation: IAM Identity Center for unified workforce access across accounts

Governance configuration is a prerequisite, not a parallel workstream. Workloads that arrive before guardrails are set create compliance gaps that take longer to remediate than to prevent.
Step 4: Migrate Servers and Databases
Server Migration with AWS MGN
Install the AWS Replication Agent on each source server. The agent performs continuous block-level replication (compressed and encrypted) to a staging area in your AWS account. Once the MGN console shows "Healthy" and "Ready for testing," configure EC2 launch templates (instance type, subnet, security group) and launch test instances to validate behavior before any cutover decision is made.
Database Migration with AWS DMS
Set up a DMS replication instance, configure source endpoints (on-premise Oracle, SQL Server, MySQL) and target endpoints (Amazon RDS or Aurora), then run a full load with Change Data Capture (CDC) enabled. CDC keeps the target synchronized with the source in near real-time, reducing cutover downtime from hours to minutes.
Key actions at this stage:
- Validate data integrity after the initial full load completes
- Run functional and performance testing against test instances
- Update application configuration files to point to new cloud endpoints
- Confirm all dependencies resolve correctly before marking servers "Ready for Cutover"
For enterprises migrating finance systems, ERPs, or complex application stacks with deep database integrations, dependency sequencing at this stage is what separates a clean cutover from an unplanned incident. Cygnet.One's migration teams bring experience across 250+ ERP integrations, where cutover sequencing decisions are grounded in mapped dependencies rather than assumptions.
Step 5: Test, Validate, and Cut Over
Testing Phase
AWS MGN supports launching up to 100 source servers in a single test operation. AWS recommends testing at least two weeks before the planned cutover window — not the day before — to give teams time to identify and resolve issues before the cutover window becomes a pressure point.
Testing should cover:
- Functional testing: application behavior matches on-premise baseline
- Performance testing: response times and throughput under expected load
- Load testing: behavior under peak traffic conditions
- Security scans: IAM roles, security group rules, encryption in transit and at rest
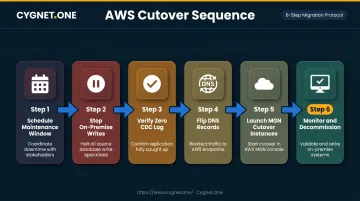
Cutover Process
The cutover sequence matters. Done incorrectly, it turns a planned migration into an emergency recovery situation.
- Schedule a low-traffic maintenance window
- Stop writes to the on-premise application
- Verify zero CDC lag in DMS
- Flip DNS records to point to AWS endpoints
- Launch cutover instances in MGN
- Monitor live on AWS for 30–60 minutes before decommissioning source servers
Pre-cutover checklist:
- ✅ Replication healthy and lag at zero
- ✅ Rollback plan documented and tested
- ✅ Monitoring dashboards live
- ✅ Stakeholders notified of maintenance window
- ✅ DNS TTLs pre-reduced to minimize propagation delay
Step 6: Monitor, Optimize, and Decommission
The first 2–4 weeks post-go-live are when performance regressions, misconfigured resources, and dependency gaps surface. Treating cutover as the finish line is how teams get caught off guard.
Monitoring Setup
Amazon CloudWatch dashboards should track CPU utilization, memory, network throughput, and application-specific metrics from day one. Configure alarms for threshold breaches and route alerts to an SNS topic or on-call system. Cygnet.One's post-migration managed services include CloudWatch dashboards, autoscaling policies, and real-time alerting, including integrations with PagerDuty and Slack for faster incident triage.
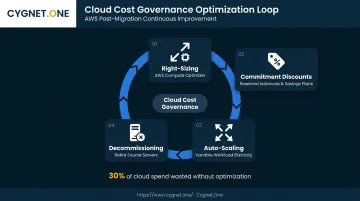
Optimization Cycle
- Right-sizing: AWS Compute Optimizer analyzes CPU and memory utilization and flags over-provisioned and under-provisioned instances. Running on-premise specs directly in EC2 without right-sizing is one of the most reliable ways to overspend.
- Commitment discounts: Purchase Reserved Instances or Savings Plans for stable workloads after 30+ days of confirmed utilization patterns
- Auto-scaling: Implement for variable-load applications to match capacity to actual demand
- Decommissioning: Retire source servers only after 30+ days of stable cloud operation and the rollback window has formally closed
Common Mistakes in AWS Cloud Migration
Treating Migration as a Copy-Paste Exercise
The most damaging misconception is that migration means copying VMs to a new location. A poorly planned lift-and-shift replicates every on-premise configuration problem—security gaps, over-provisioned specs, unresolved dependencies—into the cloud, often at higher cost because those problems weren't rethought for the cloud operating model.
Applying One Strategy to Everything
Using rehost-only across an entire portfolio misses obvious replatforming opportunities—like moving a self-managed SQL Server to Amazon RDS—that add meaningful operational value without major rework. Strategy selection should happen per workload, not once for the entire estate.
Skipping Wave Planning
Attempting to migrate an entire environment simultaneously is how controlled migrations become emergency recovery situations. Wave planning exists to sequence risk. Non-critical workloads go first, build operational confidence, and surface problems before business-critical systems are touched.
Neglecting Post-Migration Cost Governance
McKinsey research found that more than 80% of companies were over budget, behind schedule, or both, with the average company spending 14% more than planned annually. Flexera's 2025 State of the Cloud report adds that **84% of organizations struggle to manage cloud spend**, with an estimated 30% of cloud spend wasted.
The primary culprit is over-provisioned instances—on-premise specs migrated directly to equivalent EC2 types without right-sizing. AWS Compute Optimizer and commitment discounts address this directly, but only when teams treat optimization as a Day 1 post-cutover priority, not a deferred task.
Frequently Asked Questions
How do you migrate an on-premise database to AWS?
AWS Database Migration Service (DMS) is the primary tool. Configure a DMS replication instance with source and target endpoints (for example, on-premise MySQL to Amazon RDS), run a full load with CDC enabled for continuous synchronization, validate data integrity, then switch application connections during a low-traffic cutover window. CDC, when enabled before cutover, reduces downtime to minutes.
What is the difference between rehosting and replatforming in AWS migration?
Rehosting moves workloads to AWS as-is—fastest path, no code changes, minimal optimization. Replatforming makes targeted improvements during migration, such as moving from a self-managed database server to Amazon RDS, to capture managed cloud benefits without redesigning application architecture. Both preserve the existing codebase; replatforming just closes the gap to cloud-native operations faster.
How long does it take to migrate from on-premise to AWS?
Timelines depend on environment complexity. McKinsey found the average large enterprise migration takes 18–24 months; AWS documents a 1,000-server migration completed in 6 months by ramping from 5 servers per week to 50–100 per week. Expect 4–6 weeks for assessment and planning before migration waves begin.
What AWS tools are used for cloud migration?
The core native toolset covers every migration phase:
- AWS Application Discovery Service — asset inventory
- AWS Migration Evaluator — TCO and business case
- AWS Application Migration Service (MGN) — server lift-and-shift
- AWS Database Migration Service (DMS) — database migration
- AWS Control Tower — landing zone governance
- Amazon CloudWatch — post-migration monitoring and alerting
What are the biggest risks when migrating from on-premise to AWS?
The top risks: application downtime during cutover if rollback plans aren't tested in advance; data loss or corruption if CDC isn't properly configured before cutover; unexpected cloud costs from over-provisioned instances; and security misconfigurations if IAM roles, security groups, and encryption policies aren't established in the landing zone before workloads arrive.
How much does it cost to migrate to AWS?
Costs depend on environment size, migration strategy, and partner involvement — typical line items include DMS/MGN service fees, Landing Zone setup, consulting, training, and any refactoring required. Use the AWS Pricing Calculator for service-level estimates and AWS Migration Evaluator for a full TCO business case built on your actual on-premise utilization data.