
Introduction
Machine learning adoption is accelerating fast. McKinsey's 2025 Global Survey reports 88% of organizations use AI regularly in at least one business function — yet nearly two-thirds haven't begun scaling it enterprise-wide. The bottleneck is capacity, not interest.
Most organizations simply don't have dedicated data scientists available to build, train, and deploy models from scratch. That gap is exactly where AutoML tools like AWS SageMaker Autopilot step in.
Autopilot handles a lot — but it rewards teams who understand how to use it well. Common sticking points include identifying which problem types it handles, configuring training modes correctly, interpreting outputs, and keeping costs in check without a coding background.
This guide walks through all of it: when Autopilot is the right tool, what you need before starting, a step-by-step UI walkthrough, how training modes differ, and practical best practices for getting reliable results.
Key Takeaways
- Autopilot automates the full ML pipeline — data prep, algorithm selection, hyperparameter tuning, training, and deployment — with no-code and low-code options
- Best suited for tabular data (regression, binary/multiclass classification) via the UI; time-series and text classification need the AutoML V2 API
- Prerequisites: an AWS account, an S3 bucket with your dataset, a target column, and the correct IAM permissions
- Auto mode picks Ensembling (under 100 MB) or HPO (over 100 MB) automatically, though you can override either choice
- Once training completes, deploy the best model to a real-time endpoint or run batch predictions directly from SageMaker Studio
When Should You Use SageMaker Autopilot?
Autopilot works best for structured, tabular data where you have a clearly defined target variable. Common use cases include:
- Customer churn prediction
- Credit risk scoring
- Price and demand forecasting
- Risk assessment and fraud flagging
Each of these follows the same pattern: rows as observations, columns as features — the data shape Autopilot is optimized for.
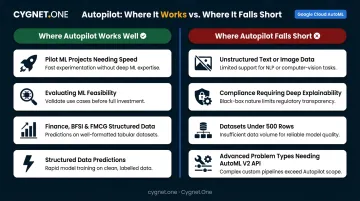
Where Autopilot Falls Short
Autopilot has real constraints worth understanding before you commit to it. Avoid it when:
- Your data is unstructured — free-form text requiring custom NLP pipelines, or image tasks needing specialized architectures, fall outside the no-code UI's scope
- You need full model transparency for compliance — if regulators require explainability at a level beyond SHAP attributions, a custom-built model gives more control
- Your dataset is too small — AWS requires at least 500 rows; in practice, datasets under a few thousand rows often don't produce reliable model candidates
- You need advanced problem types — time-series forecasting, image classification, and LLM fine-tuning are only available through the AutoML V2 API, not the UI
Knowing these limits makes it easier to spot where Autopilot actually earns its place.
Where Autopilot Delivers Results
For teams without a dedicated data science function, Autopilot cuts weeks of model experimentation down to hours. It fits well when:
- Pilot ML projects where speed to insight matters more than model perfection
- Evaluating whether a business problem is solvable with ML before investing in custom development
- Finance, BFSI, and FMCG teams that need repeatable predictions from structured operational data
What You Need Before Running an Autopilot Job
Skipping setup steps creates problems mid-job. Get these in place before you launch.
Access and Infrastructure
- Active AWS account with SageMaker access enabled and appropriate service limits for training instances
- S3 bucket in the same AWS region as your SageMaker Studio environment, containing your dataset in CSV or Parquet format
- IAM role with SageMaker execution permissions — specifically
s3:GetObject,s3:PutObject, ands3:ListBucketon your input and output buckets, plusiam:PassRolefor theCreateAutoMLJobcall
Dataset Requirements
- Minimum 500 rows of training data; validation data must be under 2 GB; training data must be under 100 GB
- A clearly defined target column — the variable you want Autopilot to predict
- CSV files must include a header row; Parquet is also supported
Autopilot handles missing value imputation and feature normalization automatically. Still, severe data quality issues — duplicate rows, inconsistent data types, heavily imbalanced target columns — should be resolved before you upload.
AWS SageMaker Data Wrangler integrates directly with SageMaker Canvas and Studio Classic, making it a practical pre-processing tool for cleaning and transforming datasets before feeding them into Autopilot.
Problem Type Clarity
Know which problem type applies before you start:
| Problem Type | Available Via |
|---|---|
| Regression | No-code UI + API |
| Binary classification | No-code UI + API |
| Multiclass classification | No-code UI + API |
| Text classification | AutoML V2 API only |
| Time-series forecasting | AutoML V2 API only |
| LLM fine-tuning | AutoML V2 API only |
Note: As of November 2023, Autopilot's no-code UI is migrating to Amazon SageMaker Canvas as part of the updated Studio experience. Studio Classic users can continue using the existing Autopilot UI during the transition.
How to Use SageMaker Autopilot: Step-by-Step
Autopilot follows a defined configuration sequence. Misconfiguring earlier steps — particularly target column selection and training mode — directly affects model quality and run time.
Setup and Configuration
- Open SageMaker Studio and navigate to the AutoML section
- Select "Create AutoML Experiment" — enter an experiment name
- Provide the S3 URI for your input dataset
- Set the data split ratio — default is 80% training / 20% validation; adjust if you have a separate validation dataset
- Specify an output S3 location for results, or let Autopilot auto-generate one
On the Target and Features screen:
- Select your target column from the dropdown
- Autopilot auto-detects data types for all columns — override as needed
- All features are included by default; custom feature selection is possible via the Candidate Generation Notebook after the run

With setup complete, the next step is configuring how Autopilot trains.
Running the AutoML Experiment
On the Training Method screen, choose:
- Auto — Autopilot decides based on dataset size (recommended for most users)
- Ensembling — for smaller datasets where speed and model diversity matter
- Hyperparameter Optimization (HPO) — for larger datasets where fine-tuning a specific algorithm is the priority
Deployment and Advanced Settings control both problem framing and cost boundaries:
- Set an endpoint name if you want Autopilot to auto-deploy the best model after training
- Select the ML problem type if known — this unlocks the ability to choose a ranking metric
- Set
MaxCandidatesorMaxAutoMLJobRuntimeInSecondsto cap run time and control costs
Click "Create Experiment" to launch. Autopilot runs multiple trials in parallel, handling training, tuning, and candidate evaluation automatically.
Reviewing Results and Selecting the Best Model
Once training completes, all trials appear in the Studio UI with their accuracy scores. Autopilot automatically selects the best-performing model based on the objective metric.
Three key outputs are generated:
- Data Exploration Notebook — summary statistics, missing values, duplicate rows, target outliers, cardinality, and anomaly scores
- Candidate Generation Notebook — editable; experienced users can modify preprocessing steps or target specific algorithms before re-running
- Model Performance Report — downloadable as PDF or JSON; includes confusion matrix, ROC curve, precision-recall tradeoff, and gain/lift curves for classification problems
- Feature Attributions (via SageMaker Clarify) — SHAP-based scores for the best model candidate, showing which features drove predictions
Deploying the Model
Select the best model from the trials list and click "Deploy Model". Two deployment options are available:
- Real-time inference — creates an HTTPS endpoint for on-demand predictions; best for applications that need near-instant responses (credit scoring at loan origination, fraud flagging at transaction time)
- Batch inference — processes large datasets at scheduled intervals; suited for monthly reporting, bulk customer scoring, or demand forecasting runs
For real-time deployment, configure the endpoint name and instance type. Once live, test the endpoint with a sample payload before routing production traffic to it.
Important: Real-time endpoints accrue charges continuously while active. Delete endpoints when not in use to avoid unnecessary costs.
Understanding Autopilot's Training Modes and Algorithms
Auto Mode
Autopilot automatically selects the training method based on dataset size:
- Under 100 MB → Ensembling
- Over 100 MB → HPO
This is the recommended default for users without a strong reason to prefer one mode. Autopilot handles the selection internally, so you can move straight to training without evaluating tradeoffs.
Ensembling Mode
Uses the AutoGluon library to run 10 trials with different model and meta-parameter settings, then combines the best-performing models into a stacked ensemble.
Supported algorithms:
- LightGBM, CatBoost, XGBoost
- Random Forest, Extra Trees
- Linear Models
- Neural Network (PyTorch) and Neural Network (fast.ai)
Ensembling uses cross-validation regardless of dataset size. An AWS benchmark from 2022 found ensembling completed up to 8x faster than HPO with 250 trials — for a sub-1 MB dataset, 10 minutes vs. 120 minutes. The speed advantage is most pronounced at smaller dataset sizes.
HPO Mode
Uses Bayesian optimization (under 100 MB) or multi-fidelity optimization (over 100 MB) to find optimal hyperparameter configurations. Runs up to 100 trials by default.
Supported algorithms:
- Linear Learner
- XGBoost
- Multilayer Perceptron (MLP)
Multi-fidelity optimization stops underperforming trials early, reallocating compute to stronger candidates. For datasets with 50,000 or fewer training instances, HPO also applies k-fold cross-validation (k=5) — adding roughly 20% to training time, but improving estimate reliability.

Practical Decision Rule
| Scenario | Recommended Mode |
|---|---|
| Dataset under 100 MB, need results fast | Ensembling |
| Dataset over 100 MB, need fine-tuned single algorithm | HPO |
| Unsure / first time using Autopilot | Auto |
Best Practices for Using SageMaker Autopilot Effectively
Prioritize Data Quality Before Launch
Autopilot handles imputation and normalization — but it cannot fix fundamentally poor data. Research published in Information Systems (2025) confirmed that data quality materially affects ML performance across tabular datasets. Label noise compounds this: a peer-reviewed study found that increasing label noise from 10% to 50% reduced XGBoost accuracy by 23%.
Before uploading your dataset:
- Remove duplicate rows and resolve data type inconsistencies
- Check that the target column is correctly labeled — accidental inclusion of the target as an input feature is one of the most common errors Autopilot's Data Exploration Notebook flags
- Address class imbalance in classification problems before training, not after
Use AWS SageMaker Data Wrangler for visual data preparation — it integrates directly into the Studio environment and requires no code for most common transformations.
Control Costs Actively
Autopilot jobs can run for several hours depending on dataset size, training mode, and number of trials. Each trial consumes compute resources.
Cost control levers available in CompletionCriteria:
MaxCandidates— valid range 1 to 750 for tabular problemsMaxAutoMLJobRuntimeInSeconds— caps total job durationMaxRuntimePerTrainingJobInSeconds— limits individual trial runtime
Always delete real-time endpoints when not in use. They accrue charges for the duration they remain active, regardless of whether they're receiving traffic.
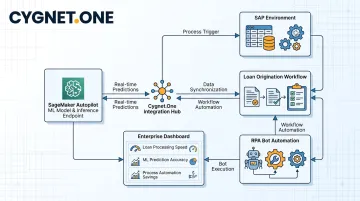
Connecting Model Outputs to Business Workflows
For enterprise teams in finance, BFSI, or FMCG sectors, the harder challenge is often connecting Autopilot outputs to existing ERP systems, compliance workflows, or operational processes.
Cygnet.One works with organizations to close that gap. Their implementation work spans:
- Integrating real-time inference endpoints into SAP environments
- Embedding credit risk predictions into loan origination workflows
- Triggering downstream RPA processes based on model outputs — using 300+ ready-to-deploy bots — without custom development for each connection
Frequently Asked Questions
What is AWS SageMaker Autopilot?
SageMaker Autopilot is an AutoML feature within Amazon SageMaker AI that automates the end-to-end ML workflow — data analysis, preprocessing, algorithm selection, hyperparameter tuning, training, and deployment. It offers both no-code UI options (for tabular data) and low-code API access for advanced problem types.
Is Amazon SageMaker fully managed?
Yes. AWS handles the underlying infrastructure, instance management, software compatibility, patching, and scaling. Users pay only for the compute and storage consumed during training and inference — no server management required. AWS renamed the service Amazon SageMaker AI on December 3, 2024.
What problem types does SageMaker Autopilot support?
Via the no-code UI and API: regression, binary classification, and multiclass classification on tabular data. Via the AutoML V2 API only: text classification, image classification, time-series forecasting, and LLM fine-tuning.
How long does a SageMaker Autopilot training job typically take?
Duration varies by mode and dataset size. Ensembling on small datasets can finish in under an hour, while large HPO jobs with 100 trials may run several hours; cross-validation adds roughly 20% on top. Use MaxCandidates and MaxAutoMLJobRuntimeInSeconds in advanced settings to cap total runtime.
What is the difference between Ensembling and HPO training modes?
Ensembling runs 10 trials across algorithms like LightGBM, XGBoost, and CatBoost, then stacks the top performers into a combined model — suited for datasets under 100 MB. HPO runs up to 100 hyperparameter-tuning trials using Linear Learner, XGBoost, or MLP, making it better for larger datasets. Auto mode selects between them based on dataset size.
Does SageMaker Autopilot require coding experience?
The no-code UI in SageMaker Studio (now migrating to SageMaker Canvas) requires no coding — configuration happens through a guided interface. Advanced use cases such as time-series forecasting, custom feature selection, or pipeline integration require Python and the AutoML V2 SDK.


