Introduction
Legacy data warehouses were built for a different era — one where data volumes were predictable and analytical latency was acceptable. Today, IDC and Seagate projected the Global Datasphere will reach 175 zettabytes by 2025, with nearly 25% of that data generated in real time. On-premises systems built a decade ago weren't designed for this.
This gap — between data generation and analytical capability — is what's forcing the modernization conversation. Enterprises that close it can make faster decisions, build forecasting models on current data, and run AI workloads without retrofitting infrastructure to accommodate them.
What follows is a practical breakdown of modern data warehouse architecture, core design principles, migration pitfalls, and what separates a capable implementation partner from one that just checks the technology boxes.
TL;DR: Key Takeaways
- A modern data warehouse centralizes structured and semi-structured data to support real-time analytics, AI/ML workloads, and BI — well beyond traditional batch reporting
- Four pipeline stages — Ingest, Transform, Model, and Serve — form the architecture, commonly structured using the Bronze/Silver/Gold Medallion pattern
- Choosing the right data model (star, snowflake, or data vault), favoring ELT over ETL, and embedding governance early all shape long-term scalability
- Partner selection matters as much as platform choice — prioritize ERP integration depth, compliance credentials, and enterprise-scale delivery experience
What Is Modern Data Warehousing?
Snowflake defines a data warehouse as a centralized repository storing current and historical data from multiple organizational sources, purpose-built for business intelligence and analytics. Google describes BigQuery as a "fully managed, completely serverless enterprise data warehouse" — a useful contrast to what most legacy systems offer.
The word "modern" matters here. It signals platforms designed for flexibility, cloud scalability, and support for advanced analytical workloads — not just structured batch reporting.
Traditional vs. Modern: A Direct Comparison
| Dimension | Traditional Warehouse | Modern Data Warehouse |
|---|---|---|
| Infrastructure | On-premises | Cloud or hybrid |
| Data types | Structured only | Structured + semi-structured |
| Processing | Batch only | Batch + real-time streaming |
| Cost model | CapEx (upfront hardware) | OpEx (pay-as-you-go) |
| Data loading | ETL | ELT |
| Scalability | Fixed capacity | Elastic, on-demand |
| AI/ML support | None | Native or integrated |
| Governance | Manual, bolted on | Embedded from design |
OLTP vs. OLAP: Why the Distinction Matters
According to AWS, OLAP (Online Analytical Processing) analyzes aggregated data for decision-making, while OLTP (Online Transaction Processing) handles database transactions with millisecond response requirements. OLAP prioritizes read operations across terabytes or petabytes of data; OLTP prioritizes write speed.
Modern data warehouses are built exclusively for OLAP use cases:
- Historical trend analysis and multi-dimensional queries
- Forecasting models and what-if scenario analysis
- Executive reporting and cross-functional BI dashboards
Running these workloads on the same system as transactional operations introduces contention, degrades query performance, and complicates governance — which is why the separation is a design requirement, not an afterthought.
Modern Data Warehouse Architecture Explained
The Four Functional Stages
Microsoft describes a modern data warehouse flow through four stages:
- Ingest — Source data lands in a data lake, persisted from transactional systems, SaaS platforms, APIs, and streaming feeds
- Transform — Data is validated, cleaned, and converted into a standardized schema
- Model — Data is structured for consumption: dimensional models, aggregations, data marts
- Serve — Processed data is exposed to BI dashboards, reports, ML model endpoints, and applications
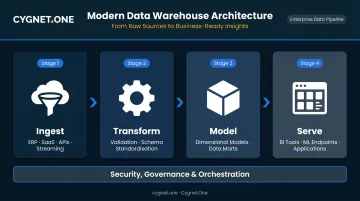
Security, governance, and orchestration span all four stages — they're not confined to any single layer.
The Medallion Architecture (Bronze / Silver / Gold)
Databricks defines Medallion Architecture as a data design pattern that organizes data into layers that incrementally improve data quality. It's the dominant design pattern for modern warehouses:
- Bronze (L1 — Raw): Data lands exactly as it arrives from source systems. No transformation. Preserves full fidelity for reprocessing and auditing.
- Silver (L2 — Enriched): Validated, deduplicated, standardized data. Schema enforcement, cleansing, and quality checks are applied here. Often modeled using 3NF or data vault.
- Gold (L3 — Curated): Business-ready dimensional models and analytics sandboxes. Optimized for dashboards, ML, and executive reporting.
This layered approach gives every team a consistent, trusted data foundation — without requiring separate pipelines for each analytical use case.
The Four Core Architectural Components
Each layer of the architecture has a defined role — and the quality of each directly shapes what downstream consumers can do with the data.
| Layer | Function | Key Technologies |
|---|---|---|
| Ingestion | Connects source systems (ERP, CRM, SaaS APIs, streaming feeds) to the data lake | SAP, Oracle, Dynamics connectors; Kafka; Fivetran |
| Processing | Applies business rules, resolves duplicates, enforces schemas via ELT | dbt, Spark, Azure Data Factory |
| Storage | Columnar engines optimized for analytical queries; object storage for raw data | Snowflake, Redshift, Synapse, Databricks |
| Serving | Exposes curated data to BI tools, ML endpoints, and embedded analytics | Power BI, Tableau, custom API endpoints |
Deployment Models
| Model | Best For |
|---|---|
| Fully cloud-managed | Elastic scaling, pay-as-you-go pricing, fast deployment |
| Hybrid | Cloud compute paired with on-premises data control for compliance requirements |
| On-premises | Strict data residency mandates, air-gapped environments |
Organizations in BFSI, healthcare, and government sectors frequently operate under data sovereignty rules that rule out fully cloud-managed deployments. TDWI defines a hybrid data warehouse as a distributed environment spanning both on-premises and cloud systems. This pattern has become the default architecture for regulated enterprises managing cross-border data obligations.
Key Design Principles for a Future-Ready Data Warehouse
Choosing the Right Data Model
Three modeling approaches dominate enterprise warehouse design:
- Star Schema: Denormalized fact and dimension tables. Fast query performance, straightforward for business users. The right default for most analytical use cases. Microsoft identifies this as the mature modeling approach widely adopted by relational data warehouses.
- Snowflake Schema: Normalized dimension tables that reduce storage redundancy. Kimball notes it can represent hierarchies accurately but adds join complexity and is harder for business users.
- Data Vault: Uses Hubs (business keys), Links (relationships), and Satellites (descriptive history). Highly auditable and scalable, ideal for enterprises with frequently changing source systems and strict compliance requirements.

Rule of thumb: Star schema for most reporting needs. Data vault when source systems are unstable, compliance is critical, and auditability is non-negotiable.
ELT Over ETL
Traditional ETL transforms data on a secondary server before loading it into the warehouse. ELT flips this: raw data lands first, and transformation happens in-place using the warehouse's own compute. The result is faster ingestion, preserved raw data for reprocessing, and support for schema-on-read exploration.
Both AWS and Snowflake now recommend ELT as the default approach for cloud warehouse implementations. Cygnet.One's data engineering implementations use automated ELT pipelines — AWS Glue and Lambda — to load versioned data directly into centralized Redshift environments, reducing pipeline complexity and improving traceability.
When to use batch vs. streaming:
- Batch ingestion: nightly financial closes, historical data loads, compliance reporting
- Streaming ingestion: fraud detection, real-time inventory, live customer analytics
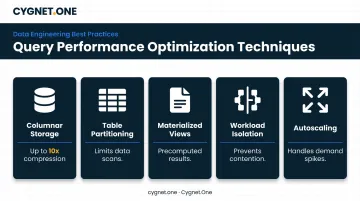
Query Performance Optimization
Key techniques that matter in production:
- Columnar storage: Microsoft documentation states columnstore indexes can improve query performance and data compression by up to 10x
- Table partitioning: Limits data scans to relevant date ranges or segments
- Materialized views: AWS Redshift stores precomputed query results to improve performance for complex, repeated queries
- Workload isolation: Separate analytical and operational clusters to prevent resource contention
- Autoscaling: Handles demand spikes without over-provisioning idle capacity
Governance and Security as Design-Time Requirements
Governance bolted on after go-live is expensive to retrofit and often incomplete. GDPR Article 5 mandates accuracy, integrity, confidentiality, and storage limitation. Article 32 requires technical safeguards proportionate to risk. HIPAA's Security Rule adds administrative, physical, and technical controls for electronic protected health information.
For BFSI clients, BCBS 239 (BIS) goes further: banks must demonstrate strong data architecture and IT infrastructure as a precondition for effective risk data aggregation — not an afterthought.
Governance requirements to embed from day one:
- RBAC: Role-based access control restricting data access by function and sensitivity
- Data lineage and audit logging: Traceable provenance for every transformation
- Metadata management: Discoverability, data dictionaries, quality metrics
- Encryption: At rest and in transit, with key management policies
Cygnet.One's implementations embed these controls natively, including IAM-based access, data encryption, and monitoring via CloudTrail — for clients in healthcare and financial services.
AI and ML Readiness
A future-ready warehouse must support ML workloads in-place, without exporting data to separate environments. Google BigQuery ML lets users create and run ML models directly with SQL queries. Snowflake's ML capabilities support model training and batch inference within the warehouse itself.
Architectural choices that enable AI workloads:
- Columnar storage for fast feature extraction
- Streaming ingestion to keep training data current
- Support for semi-structured data (JSON, Parquet)
- Integration with Python notebooks and ML frameworks
Migrating to a Modern Data Warehouse: Challenges and How to Overcome Them
The Three Migration Challenges That Derail Projects
1. Data migration complexity Moving historical data while keeping the business running requires detailed planning. Legacy formats, undocumented transformations, and data quality issues compound the complexity. Phased rollouts with rollback capability at each stage are the baseline requirement for managing this risk effectively.
2. Skills gap Modern data warehouse platforms require cloud engineering, data pipeline development, and governance expertise that most internal teams lack. This is where an experienced implementation partner closes the gap faster than internal hiring can.
3. Cost management The shift from predictable CapEx to variable OpEx catches organizations off-guard. Autoscaling policies, query optimization, and resource monitoring frameworks need to be in place before go-live, not scrambled into action after the first unexpectedly large cloud bill.
A Practical Migration Blueprint
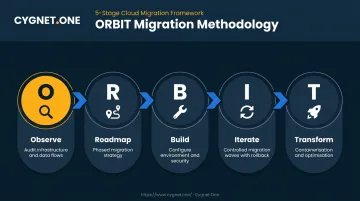
Cygnet.One uses a structured methodology called ORBIT for enterprise migrations:
- Observe — Audit current applications, infrastructure, dependencies, and data flows
- Roadmap — Build a phased migration strategy based on workload priority and business timelines
- Build — Configure the target environment, implement security controls, validate the landing zone
- Iterate — Migrate in controlled waves with parallel-run testing and rollback at every stage
- Transform — Modernize progressively through containerization, serverless adoption, and optimization
This approach has delivered production migrations with as little as 15 minutes of downtime, including migrations of 450+ databases and 7TB+ of data with zero data loss.
Common Pitfalls to Avoid
Even with a solid methodology, execution gaps can derail progress. The most common ones to watch for:
- Migrating everything at once instead of phasing by use case
- Underestimating data quality remediation time (it's almost always more than planned)
- Treating governance as a phase 2 activity
- Skipping a pilot use case before full rollout
What to Look for in a Data Warehouse Implementation Partner
Technology selection and partner selection are equally important decisions. The right partner shapes architecture, manages integrations, ensures compliance alignment, and provides ongoing support. The wrong partner adds months to timelines and technical debt to the architecture.
Five Criteria for Evaluating a Partner
1. ERP and System Integration Depth
Enterprise data warehouse projects require ERP integration as a foundational step. A strong partner maintains pre-built connectors for SAP, Oracle, Microsoft Dynamics, and regional ERP platforms — not custom-built integrations from scratch on every project.
Watch for these signals during evaluation:
- Pre-built connectors for your specific ERP (not promises of future builds)
- ERP-agnostic architecture that doesn't lock you into one vendor's ecosystem
- Documented integration references across at least 3-4 ERP platforms
Cygnet.One supports 250+ ERP integrations globally, with plug-and-play connectivity across major platforms by design.
2. Compliance and Regulatory Expertise
For BFSI, FMCG, and government clients, the partner must demonstrate hands-on experience with data governance frameworks and regional compliance requirements — data residency, financial reporting standards, sector-specific mandates.
Verifiable credentials matter here. SOC 2 Type II compliance and CMMI Level 5 appraisal both provide documented assurance of security controls and delivery quality. Cygnet.One holds both, with SOC 2 Type II achieved in 2024.
3. Enterprise Track Record and Scale
Evaluate the complexity of projects the partner has actually delivered — not just the industries listed on their website. Ask for references from projects at comparable transaction volumes and organizational complexity.
Cygnet.One has completed implementations across 35 countries over 25 years, with clients in BFSI, healthcare, manufacturing, retail, and logistics. Its tax platform processes 55 million transactions per month, demonstrating infrastructure that handles enterprise-scale transaction volumes under production conditions.
4. Architecture Flexibility and Future-Proofing
A platform-agnostic partner selects technology based on your requirements, not preferred-vendor arrangements. The right architecture avoids lock-in from day one — with hybrid deployment options available where data residency constraints apply.
Cygnet.One designs across Snowflake, Amazon Redshift, Azure Synapse, and Databricks, choosing based on client workload profile, latency requirements, and cost targets.
5. Post-Go-Live Support Model
A data warehouse that isn't tuned and governed after go-live degrades. Before signing, evaluate:
- 24x7 availability and documented incident response SLAs
- Performance optimization services (not just break-fix)
- Ongoing access to data engineering expertise, not just account managers
Cygnet.One structures post-go-live engagement to include continuous technical support and domain expertise, backed by CMMI Level 5 process maturity.
Frequently Asked Questions
What is modern data warehousing?
Modern data warehousing uses cloud-capable, scalable platforms to centralize and integrate data from multiple sources — enabling real-time BI, advanced analytics, and AI/ML workloads. It contrasts with traditional batch-only, structured-data-only approaches by supporting streaming ingestion, semi-structured data, and embedded governance.
What are the 4 pillars of data architecture?
The four pillars are Storage, Compute, Orchestration, and Governance — covering everything from where data lives to how it's processed, coordinated, and protected. A well-designed modern data warehouse must address all four in concert.
What is L1 L2 L3 in a data warehouse?
L1/L2/L3 corresponds to the Medallion architecture: L1 (Bronze/Raw) stores data exactly as received from source systems; L2 (Silver/Enriched) applies validation, standardization, and transformation; L3 (Gold/Curated) contains business-ready, consumption-optimized data products for reporting and ML.
How is a modern data warehouse different from a traditional one?
Traditional warehouses are on-premises, structured-data-only systems that rely on ETL batch processing and require heavy upfront hardware investment. Modern warehouses run on cloud or hybrid infrastructure, support ELT and real-time streaming, scale on demand, and embed AI, governance, and BI natively.
What should enterprises look for in a data warehouse implementation partner?
Evaluate partners against five criteria:
- Depth of ERP and system integrations
- Regulatory and compliance expertise with verifiable certifications
- Proven enterprise-scale project track record
- Architectural flexibility that avoids vendor lock-in
- Post-go-live support model with clear SLAs
How does a modern data warehouse support AI and machine learning?
Modern warehouses support AI/ML through in-database model execution, low-latency access to curated training datasets, and native integration with Python notebooks and ML frameworks. Platforms like BigQuery ML and Snowflake ML allow model training directly within the warehouse, while columnar storage with streaming ingestion keeps data fresh.