
Introduction
Cyberattacks don't announce themselves. Ransomware encrypts your systems at 2 a.m. A phishing campaign compromises credentials during a holiday weekend. A supply chain breach ripples through your ERP environment before anyone notices something is wrong.
Most enterprises invest heavily in prevention—firewalls, endpoint protection, threat intelligence. Far fewer invest equally in what happens after an incident occurs. Without a structured recovery plan in place, a contained incident can spiral into weeks of downtime, regulatory exposure, and reputational damage.
According to IBM's 2024 Cost of a Data Breach Report, the global average cost of a data breach reached USD 4.88 million in 2024—a 10% increase from the prior year and the steepest rise since the pandemic. In India specifically, that figure hit INR 195 million, up 39% since 2020.
Those numbers reflect organizations that had no clear recovery path. A cybersecurity disaster recovery plan (DRP) is the difference between a two-day disruption and a two-month crisis. This guide covers what a DRP is, why enterprises in regulated sectors like BFSI, NBFC, and IT services need one, and how to build it—including recovery objectives, incident response phases, and testing frameworks.
Key Takeaways
- A cybersecurity DRP is a pre-approved, documented set of procedures for restoring IT systems and data after a cyberattack or security incident
- Without one, organizations face extended downtime, uncontrolled data loss, regulatory penalties, and reputational harm
- Two metrics anchor every DRP: RTO (recovery time target) and RPO (maximum acceptable data loss)
- Key steps include risk assessment, defining RTOs/RPOs, assigning roles, isolating backups, and running simulations
- A DRP is not a Business Continuity Plan—it is narrower, IT-focused, and triggered by a disruption
What Is a Disaster Recovery Plan in Cybersecurity?
A cybersecurity DRP is a documented, pre-approved set of instructions that defines how an organization will detect, contain, and recover its critical IT systems and data following a security incident. That includes ransomware, data breaches, DDoS attacks, and compromised insider accounts — all within a defined recovery time window.
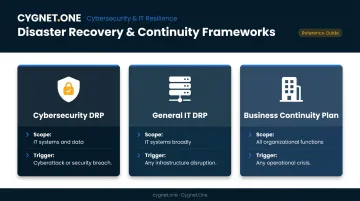
How It Differs From Related Frameworks
Three terms get conflated regularly, but each has a distinct scope and trigger:
| Framework | Scope | Triggered By |
|---|---|---|
| Cybersecurity DRP | IT systems and data, security incidents specifically | Cyberattack or security breach |
| General IT DRP | IT systems broadly, including hardware failure and natural disaster | Any major infrastructure disruption |
| Business Continuity Plan (BCP) | All organizational functions—IT, personnel, facilities, communications | Any crisis affecting operations |
As NIST SP 800-34 Rev. 1 defines it, a DRP is an information-system-focused plan designed to restore operability of systems and applications after an emergency. The cybersecurity-specific variant adds layers that a generic DRP doesn't always address: threat containment, forensic evidence preservation, and regulatory notification procedures tied to specific legal deadlines.
Organizations in regulated industries — banking, healthcare, manufacturing — typically need all three frameworks active simultaneously, each serving a different recovery function.
Why Organizations Need a Cybersecurity Disaster Recovery Plan
The Financial Exposure Is Real
ITIC's 2024 Hourly Cost of Downtime Report found that one hour of downtime costs more than USD 300,000 for over 90% of mid-size and large enterprises. For 41% of enterprises, that figure climbs to between USD 1 million and USD 5 million per hour.
For enterprises processing high volumes of financial transactions (payment portals, lending platforms, tax compliance systems), the math compounds fast. Cygnet's tax platform processes 55 million transactions monthly across India and global markets. It maintains an RTO of approximately one hour and an RPO under 30 minutes for Tier-1 services — even brief outages during peak filing periods carry severe operational consequences.
Regulatory Mandates Make DRPs Non-Optional
Enterprises in BFSI, healthcare, and government-adjacent sectors don't get to treat a DRP as optional infrastructure. Specific mandates include:
- RBI (India): Circular RBI/2015-16/418 requires banks to maintain a Cyber Crisis Management Plan covering detection, response, recovery, and containment, with incident reporting within 2 to 6 hours of a cyber event
- SEBI (India): The 2024 Cybersecurity and Cyber Resilience Framework (CSCRF) mandates documented recovery capabilities for all regulated entities; Qualified RTAs face additional BCP/DR standards under a separate 2023 circular
- GDPR (Europe): Article 33 requires breach notification to supervisory authorities within 72 hours of discovery
- HIPAA (US): Breach notification to HHS and affected individuals must occur within 60 days of discovery
- India DPDP Act, 2023: Data Fiduciaries must notify both the Data Protection Board and affected individuals of any personal data breach
- UAE PDPL: Requires controller notification to the UAE Data Bureau when a breach prejudices privacy, confidentiality, or data security
Missing these deadlines layers regulatory penalties on top of operational damage. A well-designed DRP prevents this by embedding notification deadlines directly into the response workflow — so ownership is clear before a breach ever occurs.
What Happens Without a DRP
The pattern is consistent across incidents:
- Uncoordinated teams take hours to agree on containment steps, extending breach windows
- Evidence gets destroyed during ad-hoc remediation, preventing forensic root cause analysis
- Public communications happen without legal review, creating additional liability
- Notification deadlines are missed because no one owns that responsibility

How to Build a Cybersecurity Disaster Recovery Plan
An effective DRP operates across three phases: Prevention (reducing attack surface), Detection (identifying an incident and activating the plan), and Recovery (restoring systems and data). Most teams focus only on recovery. That narrow focus is precisely why plans break down when an actual incident hits.
Step 1: Conduct a Risk Assessment and Business Impact Analysis
Start by mapping your threat landscape. The most common attack vectors aren't theoretical:
- Ransomware and extortion were involved in 32% of breaches analyzed in Verizon's 2024 DBIR
- Abuse of valid accounts and phishing each accounted for 30% of incidents in IBM X-Force's 2024 data
- Internal actors were involved in 35% of breaches, with 73% of those classified as accidental errors rather than malicious actions
Map these threat types to your specific systems and data assets. Then run a Business Impact Analysis (BIA) to quantify what downtime or data loss in each critical system actually costs: operationally, financially, and in regulatory terms. The BIA output determines which systems get the most aggressive recovery targets.
Step 2: Define RTO and RPO
These two metrics are the operational backbone of any DRP.
Recovery Time Objective (RTO): The maximum time a system can be offline before the business is critically impaired.
Recovery Point Objective (RPO): The maximum acceptable data loss, measured in time, meaning the oldest backup point you can restore from without unacceptable gaps.
These are business decisions first, technical decisions second. Example targets:
| System | RTO | RPO |
|---|---|---|
| Payment processing portal | 1–2 hours | 15 minutes |
| Tax compliance platform | 1 hour | 30 minutes |
| Customer-facing web application | 4 hours | 1 hour |
| Internal HR portal | 48 hours | 24 hours |

SEBI's framework for exchanges and depositories sets RTO and RPO benchmarks of no more than 4 hours and 30 minutes respectively. Financial sector organizations can treat these as a minimum baseline when setting their own targets.
Step 3: Assign Roles and Communication Protocols
A DRP without named owners fails at activation. Define these roles before an incident occurs:
- Incident Commander: Oversees the full response, makes containment decisions
- Technical Recovery Team: Executes isolation, restoration, and validation procedures
- Asset Manager: Secures and inventories critical systems during containment
- Incident Reporter: Manages external communications to customers and regulators
- Documentation Lead: Maintains audit logs throughout the response
Communication protocols must be pre-established, including out-of-band channels (separate email, phone trees, encrypted messaging) for scenarios where primary systems are compromised. Regulatory notification timelines must be assigned to a named owner before an incident occurs: 72 hours under GDPR, 2–6 hours under RBI's cyber framework. Leaving this to whoever remembers is not a protocol.
Step 4: Secure Backups and Define Restoration Procedures
CISA endorses the 3-2-1 backup rule as the operational standard:
- 3 copies of critical data
- 2 different media types
- 1 copy offsite or in an isolated cloud environment
The isolation piece is critical. Veeam's 2024 Ransomware Trends Report found that backup repositories were targeted in 96% of ransomware attacks and successfully compromised in 76% of cases. Backups stored in the same network segment as primary systems offer little protection.
Given how often backups are targeted, the order in which you restore matters as much as whether backups exist at all:
- Quarantine and isolate compromised systems first
- Verify backup integrity before restoring anything
- Apply security patches to close the initial attack vector
- Restore in priority order established by your BIA (not all systems simultaneously)
- Validate restored systems before reconnecting to production networks
Not all data requires the same RPO. Transaction records, customer PII, and compliance documentation require near-continuous backup. Marketing assets may tolerate 24-hour gaps.
Your DRP should specify backup frequency by data tier. A single organization-wide schedule is rarely adequate and often leaves high-risk data under-protected.
Step 5: Test, Simulate, and Update Regularly
Testing is what separates a functioning DRP from a filing exercise. Veeam's 2024 BC/DR data found that only 58% of servers resumed operations within established SLAs during large-scale recovery tests, meaning 42% failed their own targets under controlled conditions, not during an actual incident.
Three testing methods serve different purposes:
- Tabletop exercises: Team discussion simulating a scenario; low cost, good for role clarity
- Simulated drills: Functional rehearsals without impacting live systems; tests procedures under realistic pressure
- Full failover tests: Actually switching to backup systems; the only way to validate actual RTO/RPO targets

Test at minimum annually, and after every major infrastructure change, significant personnel shift, or actual incident. Cygnet conducts quarterly failover simulations for its own tax compliance infrastructure, including documented rollback drills, which is how the platform maintains its 99.95% application availability record.
Post-test findings must update the plan formally, with version control and a documented review date. Infrastructure changes faster than most DRPs are refreshed; a plan written against last year's architecture is a liability, not a safeguard.
Key Factors That Shape an Effective Cybersecurity DRP
Infrastructure Complexity
Multi-environment complexity directly amplifies recovery difficulty. IBM's 2024 data found that breaches spanning public cloud, private cloud, and on-premises environments cost over USD 5 million on average and took 283 days to identify and contain. Organizations running 250+ ERP integrations need dependency mapping built into their DRP, because restoration sequencing must account for which systems others rely on before they can come back online.
Jurisdiction-Specific Response Branches
Organizations operating across multiple regulatory environments cannot run a single generic DRP. Notification timelines, data residency rules, and evidence preservation requirements differ by jurisdiction.
A platform operating under India's DPDP Act, UAE's PDPL, and GDPR simultaneously needs jurisdiction-specific response branches embedded in a single master plan — each with its own breach notification window, data localization constraints, and evidence handling procedures. Cygnet's compliance footprint across India, UK, UAE, Saudi Arabia, and Belgium reflects exactly this level of jurisdictional granularity.
Human Factors
Verizon's 2024 DBIR found that the human element was a factor in 68% of breaches — a figure that should anchor how you design recovery controls, not just prevention. Your DRP needs explicit human-layer safeguards:
- Identity verification during recovery — prevents attackers from impersonating IT staff while systems are being restored
- Post-incident forensics protocols — distinguishes accidental errors from deliberate sabotage, which affects both legal response and insurance claims
Common Mistakes in Cybersecurity DRP Implementation
Mistake 1: Treating Backups as a Full DRP
Backups are a component, not a substitute. Without a documented restoration procedure, a tested recovery timeline, and a clear chain of command, teams find that restoration takes three to four times longer than expected — because the process was never rehearsed.
Mistake 2: Filing the DRP and Forgetting It
When a real incident hits, outdated plans reference decommissioned systems, stale contact lists, and procedures that no longer match current infrastructure. DRPs must be version-controlled and reviewed after every major change — not shelved after initial sign-off.
Mistake 3: Waiting for Full Clarity Before Activating
Teams often delay response while trying to assess the complete breach scope. That wait is itself one of the costliest errors in incident response. Activation criteria should be low-threshold: begin containment within minutes of detection, not hours.
Here's a quick summary of each mistake and the corrective action:
| Mistake | Root Cause | Corrective Action |
|---|---|---|
| Backups treated as DRP | No restoration procedure tested | Rehearse recovery with documented RTO/RPO targets |
| Plan never updated | No change-triggered review cycle | Version-control the DRP; review after every major infrastructure change |
| Delayed activation | Scope assessment before containment | Set low-threshold activation criteria; act within minutes of detection |

Frequently Asked Questions
What is a disaster recovery plan in cybersecurity?
A cybersecurity DRP is a documented set of pre-approved procedures for restoring IT systems and data after a cyberattack or security incident. It defines roles, timelines, backup restoration sequences, and regulatory notification steps to minimize downtime, data loss, and compliance exposure.
What are RTO and RPO examples?
RTO is the maximum acceptable downtime: a banking payment portal might target an RTO of 1–2 hours. RPO is the maximum acceptable data loss measured in time — an RPO of 15 minutes means backups must run at least every 15 minutes so no transaction window exceeds that threshold.
How is a cybersecurity DRP different from a Business Continuity Plan?
A DRP is IT-focused and activated after a disruption to restore specific systems and data. A BCP is broader, covering all organizational functions—personnel, facilities, communications, and operations—during and after a crisis. Enterprises typically need both, coordinating closely.
How often should a cybersecurity DRP be tested?
At minimum once annually through tabletop exercises or simulated drills. Additional tests should follow any major infrastructure change, after a real incident, or when significant new threats emerge in your sector. High-volume transaction environments benefit from quarterly failover simulations.
What is DRaaS (Disaster Recovery as a Service)?
DRaaS is a cloud-based model where a third-party provider manages disaster recovery infrastructure, letting organizations fail over during an incident without maintaining their own secondary data center. The DRaaS market was valued at USD 13.3 billion in 2024.
Which organizations are most required to have a formal cybersecurity DRP?
Regulated sectors face the clearest mandates: banking, NBFCs, insurance, and healthcare, along with any organization subject to GDPR, India's DPDP Act, or HIPAA. These frameworks specify DRP requirements, testing frequency, and incident reporting timelines.


