
Introduction
Most AWS migrations start with the same question: does it work? Getting workloads running in the cloud is the easy part. The harder question — whether it scales, stays secure, and stays affordable at 10x the load — rarely gets asked until something breaks.
Without a structured approach, cloud flexibility becomes cloud chaos. Teams over-provision to compensate for uncertainty, security gaps appear at account boundaries, and costs spiral past budgets before anyone notices.
The AWS Well-Architected Framework addresses exactly those failure modes. Built by AWS to codify proven design principles, it gives architects a structured way to evaluate decisions before they become production problems. This guide covers all six pillars, the four primary architectural patterns, and the specific practices that separate well-run AWS environments from expensive ones.
Key Takeaways
- The AWS Well-Architected Framework covers 6 pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
- Each pillar maps to concrete design principles and specific AWS services, with actionable guidance for each.
- Choose architecture patterns (three-tier, serverless, microservices, multi-account) based on workload characteristics — not industry trends.
- For enterprise and compliance-sensitive workloads, security and reliability must be designed in from the start — not bolted on later.
What Is the AWS Well-Architected Framework?
The AWS Well-Architected Framework is a set of foundational questions and proven best practices that help architects evaluate trade-offs in cloud design decisions. It covers reliability, security, efficiency, cost-effectiveness, and sustainability — giving teams a consistent framework for assessing how well an architecture is built and where it needs improvement.
Who it's for:
- CTOs and cloud architects making foundational design decisions
- DevOps teams evaluating operational gaps
- Developers building new services or migrating existing ones
- Compliance and security teams assessing cloud posture
Used correctly, the framework drives a structured architectural conversation — one that surfaces trade-offs, identifies improvement areas, and prioritizes remediation work. It's a diagnostic tool, not a compliance checklist.
The AWS Well-Architected Tool makes this accessible as a free, self-service review mechanism in the AWS console. Teams answer a series of questions about their workloads and receive a prioritized list of high-risk findings with recommended remediation steps, without needing an external consultant for the initial review.
The 6 Pillars of the AWS Well-Architected Framework
Each pillar addresses a distinct architectural quality. Improving one often strengthens the others — they are interconnected, not isolated domains.
Operational Excellence
Operational Excellence focuses on running and monitoring systems to deliver business value while continuously improving supporting processes.
- Automate deployments and patching using AWS CloudFormation, CDK, and Systems Manager — manual processes introduce inconsistency at scale
- Implement observability with CloudWatch for metrics/alarms and X-Ray for distributed tracing across services
- Make frequent, small, reversible changes via CI/CD pipelines rather than large, infrequent releases
- Conduct post-incident reviews to extract learning rather than assign blame
Done well, operations become invisible — automated, self-correcting, and rarely requiring manual intervention.
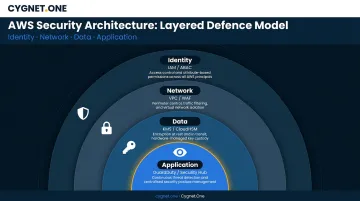
Security
Security must be layered across identity, network, data, and application levels simultaneously.
- Enforce least-privilege IAM using groups and Attribute-Based Access Control (ABAC) with resource tags — never assign permissions directly to individual users
- Encrypt data at rest and in transit using AWS KMS for key management and CloudHSM for workloads requiring hardware-level key isolation
- Enable continuous threat detection with GuardDuty for anomaly detection and Security Hub for centralized findings aggregation
- Centralize logs and security tooling in a dedicated security account, separate from workload accounts
Reliability
Reliability is about designing systems that recover from failure automatically — not systems that never fail.
- Deploy across multiple Availability Zones with Auto Scaling to maintain capacity during AZ failures
- Set RTO and RPO targets based on actual business cost of downtime — not technical preference
- Test resilience regularly: chaos engineering in non-production environments surfaces failure assumptions that monitoring alone won't catch
- Monitor service quota utilization and automate responses before limits become incidents
Performance Efficiency
This pillar focuses on using the right resource at the right scale — not the most powerful resource available.
- Choose compute based on workload pattern: EC2 for sustained, predictable jobs; Lambda for event-driven spikes; ECS/EKS for consistent, portable workloads
- Use Amazon CloudFront for global content delivery and latency reduction
- Right-size instances continuously — what was correct at launch rarely stays correct at scale
- Serverless architectures eliminate structural over-provisioning by design
Cost Optimization
Cost optimization compounds over time — small decisions about tagging, purchasing, and decommissioning add up to meaningful savings at scale.
- Tag all resources at creation with workload, owner, and environment metadata to enable accurate cost attribution
- Use Reserved Instances or Savings Plans for stable workloads; Spot Instances for fault-tolerant batch and pipeline jobs
- Set AWS Budgets alerts before costs exceed thresholds — not after
- Decommission unused resources proactively — idle infrastructure is a continuous cost with no return
Sustainability
The newest pillar focuses on reducing the environmental impact of cloud workloads.
- Choose AWS regions with renewable energy sources when latency and compliance requirements permit
- Use auto-scaling and rightsizing to eliminate idle resource energy consumption
- Prefer managed and serverless services — they pack compute more efficiently than self-managed alternatives
- Apply data lifecycle policies to avoid storing unnecessary data in high-cost, high-energy storage tiers
AWS Architectural Patterns: Choosing the Right One
Pattern selection must be driven by workload type, compliance requirements, team structure, and scalability goals — not by what appears most frequently in conference talks.
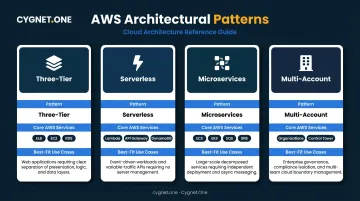
The Four Primary Patterns
| Pattern | Core Services | Best Suited For |
|---|---|---|
| Three-Tier | ELB + EC2/Elastic Beanstalk + RDS/DynamoDB | Web applications, teams migrating traditional workloads |
| Serverless | Lambda + API Gateway + DynamoDB | Event-driven workloads, unpredictable traffic spikes |
| Microservices | ECS/EKS + SQS/SNS + X-Ray | Large apps with independent service boundaries, autonomous teams |
| Multi-Account | AWS Organizations + Control Tower | Enterprise environment isolation, compliance segmentation |
A Practical Decision Framework
Start here before committing to a pattern:
- Start with data sensitivity: regulated data (financial, health, personal) constrains your architecture before anything else does
- Work backwards from user experience, since latency requirements and traffic patterns directly shape compute choices
- Sketch the workflow: a rough data flow diagram reveals which pattern fits
- Choose the pattern that fits now and scales later — optimize for tomorrow's load, not today's
Key questions for any architecture review:
- Is sensitive data isolated at the account or VPC level?
- Is encryption enforced everywhere: at rest, in transit, and service-to-service?
- Can unnecessary resources be automatically shut off during low-traffic periods?
Patterns are not mutually exclusive. A real enterprise workload often combines elements — a multi-account strategy wrapping a three-tier application core, with a serverless data ingestion pipeline running alongside it. This layered approach is common in practice: for example, using AWS Control Tower for multi-account governance while running microservices on EKS within each account boundary — a pattern Cygnet.One applies across enterprise cloud engagements.
Security and Reliability: Non-Negotiable Pillars for Enterprise Workloads
For finance, healthcare, and government workloads, security and reliability carry regulatory weight that goes well beyond technical preference. IBM's 2025 Cost of a Data Breach Report puts the global average cost of a data breach at $4.88 million. A breach or extended outage in a regulated industry compounds that figure with penalties, remediation costs, and client attrition.
IAM: Beyond the Basics
The AWS IAM security best practices documentation covers the fundamentals, but enterprise environments require more than the basics:
- Implement ABAC with resource tags to scale permissions management without proliferating policies
- Isolate production, development, and testing in separate AWS accounts — not separate VPCs within the same account
- Use temporary, time-limited credentials for production changes via IAM roles and session policies
- Run IAM Access Analyzer regularly to identify unintended external access to resources
Network Security in Layers
- Create dedicated VPCs for ingress, egress, and inspection flows — not a single shared VPC for all traffic
- Encrypt east-west traffic (service-to-service) even within the same network boundary
- Deploy AWS WAF and Shield for perimeter defence against application-layer attacks and DDoS
Disaster Recovery: Matching Strategy to Business Cost
Define RTO (Recovery Time Objective) and RPO (Recovery Point Objective) based on the actual cost of downtime to the business — not on what's technically convenient.
The DR strategy spectrum:
| Strategy | RTO/RPO | When to Use |
|---|---|---|
| Backup & Restore | Hours | Non-critical, cost-sensitive workloads |
| Pilot Light | 10s of minutes | Core systems that can tolerate brief outages |
| Warm Standby | Minutes | Important systems with moderate downtime tolerance |
| Multi-Site Active/Active | Seconds | Mission-critical, zero-tolerance applications |

Use AWS Backup for centralised, policy-driven backup management and Route 53 health checks for automatic DNS-level failover during incidents.
What This Looks Like at Scale
Cygnet.One processes over 55 million transactions monthly and handles approximately 19% of India's e-invoice volumes — workloads where a reliability failure triggers compliance failures for thousands of downstream businesses, not just an internal outage.
Sustaining 99% uptime across these volumes requires every layer of the architecture to pull its weight. The core components include:
- Multi-AZ EKS deployments for container workload resilience across availability zones
- Route 53 health routing for automatic DNS-level failover during incidents
- PostgreSQL replicas with automated failover to protect transactional data continuity
- CloudWatch monitoring with SNS alert routing for real-time incident detection and response
SOC 2 Type II compliance and 250+ ERP integrations are direct outputs of these architectural decisions — each certification reflects a control that the infrastructure already enforces.
Cost Optimisation, Performance, and Operational Excellence in Practice
Cost as a Continuous Practice
Cost optimisation requires the same active, ongoing discipline as security. Periodic reviews aren't enough.
- Tag every resource at creation with workload, function, owner, and environment — untagged resources are invisible costs
- Conduct **monthly reviews using AWS Cost Explorer** with SMART cost targets assigned to specific teams
- Use Reserved Instances or Savings Plans for stable baseline workloads; Spot Instances for batch jobs and fault-tolerant pipelines
- Flatten demand curves with API Gateway throttling and SQS buffering to reduce over-provisioned capacity sitting idle during off-peak hours
Cygnet.One's FinOps practice has delivered documented outcomes: a 30% reduction in AWS spend for one digital lending client, 50% lower long-term storage costs for a banking client, and 60% storage cost reduction for an AI SaaS workload — all through rightsizing, lifecycle policies, and eliminating idle resources.
Operational Excellence in Practice
Automate everything that is repeatable:
- Provision infrastructure with CloudFormation or CDK for consistent, version-controlled environments
- Deploy through CI/CD pipelines (CodePipeline, GitHub Actions, Jenkins) with automated testing and security scanning
- Patch fleets using Systems Manager for coordinated, auditable patch management
- Define rollback paths for every deployment — automated, not manual
Design retry logic with exponential backoff and jitter to handle transient failures without overwhelming upstream services. Design for idempotency so duplicate requests don't create duplicate outcomes — a critical pattern for financial transaction processing.
Performance Efficiency in Practice
Run chaos engineering experiments in non-production environments to surface hidden vulnerabilities before they appear in production
- Load test before provisioning — understand actual resource requirements rather than guessing at scale
- Run chaos engineering experiments in non-production environments to surface hidden vulnerabilities before they appear in production
- Right-size continuously using AWS Trusted Advisor and Compute Optimizer recommendations on an ongoing basis, not just at launch
- Use CloudFront for latency reduction across geographies
Frequently Asked Questions
What are AWS architecture best practices?
AWS architecture best practices are proven design and operational principles rooted in the Well-Architected Framework's six pillars. They give teams a structured way to evaluate trade-offs across security, reliability, efficiency, cost, and sustainability — replacing ad hoc decisions with consistent, repeatable standards.
What are the 6 pillars of the AWS Well-Architected Framework?
The six pillars are Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability. Each pillar defines specific design principles and recommended AWS services to help teams assess and strengthen a distinct quality of their architecture.
How do I choose the right AWS architectural pattern for my workload?
Start with data sensitivity and compliance requirements, then match workload characteristics (traffic patterns, team structure, scalability needs) to the appropriate pattern. Three-tier, serverless, microservices, and multi-account can overlap — most enterprise workloads draw from more than one pattern.
What AWS services support disaster recovery and reliability?
Key services include AWS Backup for centralized automated backups, Route 53 with health checks for DNS-level failover, Auto Scaling for capacity management, Elastic Load Balancing for traffic distribution, and multi-AZ deployments for redundancy. Together they support DR strategies from Backup & Restore through to Multi-Site Active/Active.
How can I reduce AWS costs without compromising performance?
A few high-impact actions:
- Tag all resources for lifecycle tracking and use Reserved Instances or Savings Plans for stable workloads
- Rightsize continuously with Trusted Advisor and Compute Optimizer; eliminate idle resources proactively
- Use Spot Instances for flexible batch jobs and SQS buffering to flatten demand spikes instead of over-provisioning


