
Introduction
Enterprises are racing to deploy agentic AI, but a troubling pattern has emerged: impressive pilots routinely fail to translate into operational value. Gartner predicts that over 40% of agentic AI projects will be canceled by 2027, and real-world reversals are already occurring—Klarna began rehiring customer service staff in 2025 after replacing 700 positions with an AI assistant that drove customer satisfaction down.
Agentic AI systems can plan, execute multistep processes, and self-correct in real-world environments. That makes them fundamentally different from generative AI, which generates content on demand. Agentic AI triggers workflows, calls tools, and makes decisions with minimal human input—the gap between answering a question and acting on it.
This article distills lessons from real enterprise deployments. The insights come from organizations that have moved beyond pilots to achieve measurable ROI—covering governance frameworks, change management, and operational integration in finance, compliance, and operations.
Key Takeaways
- ROI comes from redesigning entire workflows, not inserting agents into legacy processes
- Match the tool to the task—not every process needs an agent; simpler automation often works better
- Build trust through rigorous evaluation frameworks before expanding agent autonomy
- Human oversight is a design requirement, especially in regulated industries like finance and tax
- Build step-level observability into agents so errors surface quickly and stay recoverable
Design Around Workflows, Not the Agent
The most common mistake in agentic AI implementation is treating the agent as the product. Organizations build impressive demos that showcase technical capability but fail to improve the actual work. McKinsey's 2025 research shows high-performing AI adopters are nearly three times more likely to fundamentally redesign workflows rather than layer agents onto existing processes.
Start with process mapping, not technology selection. Before deploying any agent, map your current workflow in detail:
- Where is human effort wasted on repetitive tasks?
- Where does variance create bottlenecks?
- Where do errors compound across steps?
Agents should fill these specific gaps. A Harvard Data Science Review case study documented a global industrial firm that cut audit reporting time by 92% by redesigning the entire process around agentic capabilities—not by replicating the old one.
Rethink the workflow from the ground up. The real gains come when you change how people, processes, and technology interact—not just which steps get automated.
Take invoice processing as a concrete example. The traditional workflow involves manual data entry, three-way matching, and exception handling. An agent-driven redesign eliminates data entry through intelligent extraction, runs continuous validation against multiple data sources, and routes only genuine exceptions to humans—reducing the average cost per invoice from $9.40 to $2.78 (USD), according to Ardent Partners' 2025 benchmarks.
Build feedback loops into the design. Every user correction or edit should become a learning signal. The more the agent operates within a well-designed feedback loop, the more accurately it handles edge cases over time. In practice, this means:
- Capturing user overrides and edits in structured logs
- Routing failed cases back to evaluation datasets
- Using domain expert review to refine prompts and knowledge bases
- Measuring improvement through continuous testing cycles
Use agents as orchestration layers. In complex, multistep workflows like credit risk analysis or compliance review, agents act as the integrating layer. They call the right tools at the right step—whether that's a rule-based validation, a predictive model, or an LLM for unstructured reasoning—unifying outputs under a common framework. This orchestrator-worker pattern, outlined in Anthropic's published guidance on multi-agent systems, allows each component to do what it does best while the agent manages the overall process flow.
Know When Agents Are—and Aren't—the Right Tool
Most implementation failures trace back to the same mistake: deploying agents where simpler tools would do the job better, or avoiding them entirely where they'd genuinely help. The right question is always: what is the work to be done, and what tool is best suited for it?
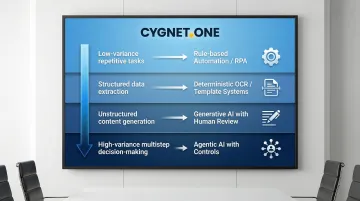
Apply a structured decision framework. Gartner, McKinsey, and Forrester each recommend matching automation technology to task characteristics:
- Low-variance, repetitive tasks: Use rule-based automation or RPA
- Structured data extraction: Use deterministic OCR or template-based systems
- Unstructured content generation: Use generative AI with human review
- High-variance, multistep decision-making: Use agentic AI with proper controls
Strong candidates for agentic AI:
- Complex financial information extraction across variable document formats
- Multi-jurisdictional compliance analysis requiring cross-referencing of regulations
- Credit risk assessment combining structured data, unstructured documents, and external APIs
- Processes where the exact sequence of steps cannot be predetermined
These workflows share common traits: high variance, low standardization, and significant human validation burden. Agents reduce that burden by handling the complex orchestration while humans focus on exceptions and high-stakes decisions.
Poor fits for agentic AI:
- Tightly governed, low-variance processes like statutory filing generation
- Standard regulatory disclosures with fixed formats
- Simple data entry or form population
- Any workflow requiring 100% reproducibility for audit purposes
In these contexts, nondeterministic LLMs add complexity without value. A 2025 study on LLM output drift found that larger models showed only 12.5% consistency across identical runs—even with deterministic settings enabled. Where exact reproducibility is a hard requirement, rule-based systems remain the right choice.
Guard against "agent washing." Many vendors relabel scripted automation as "agents" to ride the hype cycle. Gartner flags this as a growing evaluation risk. True agentic systems demonstrate planning, tool use, and adaptive reasoning—capabilities that are testable, not just claimed.
Build Agent Trust Through Evaluation and Continuous Feedback
Poor-quality AI outputs erode trust faster than anything else. A Harvard Business Review survey found that only 6% of companies fully trust AI agents to run core business processes autonomously. McKinsey reported that 51% of organizations using AI experienced at least one negative consequence, with nearly a third citing inaccuracy as the cause.
Agent deployment works much like onboarding a new hire: agents need clear job descriptions, performance standards, and ongoing feedback to improve. That means:
- Documenting what "good" looks like through expert examples
- Defining measurable success criteria before deployment
- Creating evaluation suites that test against real-world scenarios
- Establishing continuous review cycles with domain experts
Start with Structured Evaluations
Evals are automated tests that measure whether an agent performs as expected. According to guidance from Anthropic, OpenAI, and Google Cloud, comprehensive evals should include:
- Deterministic graders: Code-based checks (regex, schema validation) for objective correctness
- Model-based graders: LLM-as-a-judge scoring for nuanced or subjective outputs
- Trajectory checks: Verification that the agent called the right tools in the right sequence
- Reliability metrics:
pass^kmeasures the probability of success across repeated attempts, not a single run

Anthropic reports that teams using evals from the start can upgrade models in days versus weeks for those who don't. The difference is having a safety net that catches regressions before they reach production.
Codify Expertise at a Granular Level
Generic operating procedures don't work. Teams must document what separates top performers from average ones — the judgment calls, the edge case handling, the domain-specific heuristics — and translate that knowledge into prompt design and agent logic. This requires sustained collaboration with domain experts, not a one-time knowledge dump.
Close the Feedback Loop
Production monitoring should feed directly back into evaluation datasets:
- Instrument systems to capture detailed telemetry (prompts, tool calls, outputs)
- Identify failure cases and near-misses from production logs
- Add these cases to your offline evaluation suite
- Use domain expert review to refine prompts and knowledge bases
- Run automated evals in CI/CD to prevent regressions
Run this cycle consistently, and agents improve against the failures that actually matter in production — not just the edge cases your team anticipated at launch.
Design Human-AI Collaboration Into Every Step
Effective agentic AI design starts by identifying exactly where human judgment, accountability, or oversight must sit within the workflow — then building those touchpoints in deliberately, not as an afterthought.
Define clear decision boundaries. Some decisions agents can handle autonomously:
- Organising structured data from multiple sources
- Recommending approaches based on pattern matching
- Routing tasks to appropriate specialists
- Generating first drafts for human review
Other decisions require human involvement:
- Legal sign-off on contracts or filings
- Credit approvals above certain thresholds
- Compliance validation for high-risk transactions
- Strategic decisions with business impact
Implement Human-in-the-Loop (HITL) patterns. Confidence threshold routing is effective: the agent's confidence score determines whether an action proceeds autonomously or queues for human review. For example:
- Confidence > 0.95: Execute automatically
- Confidence 0.80–0.95: Execute but log for asynchronous review
- Confidence < 0.80: Block and queue for mandatory human approval
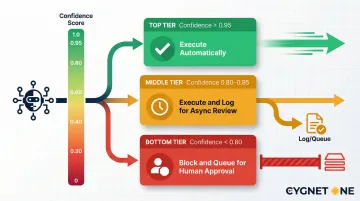
Start with conservative thresholds and adjust as you collect performance data. This approach balances efficiency with safety, allowing high-certainty tasks to flow while catching ambiguous cases.
Make the Interface Work for the People Using It
Agentic systems succeed when interfaces make it easy for people to interact with agents, validate outputs quickly, and course-correct. This means:
- Clear visibility into what the agent is doing and why
- Simple mechanisms to approve, reject, or override decisions
- Contextual information that helps humans make informed judgements
- Fast feedback loops so corrections improve future performance
When the interface removes friction from validation, teams adopt the system faster — and the feedback they provide makes the agent measurably better over time.
Make Every Step Visible: Observability and Governance at Scale
Tracking agent behavior is manageable with a few agents. At scale, it becomes a governance crisis. Gartner predicts that by 2026, 40% of enterprise applications will feature task-specific AI agents, up from under 5% in 2025. A 2026 Dynatrace survey found 26% of organizations already have 11 or more agentic projects underway.
The Scale Problem
Most organizations only monitor outcomes — which makes it nearly impossible to identify where in a workflow something went wrong. When an agent produces an incorrect result, you need to know:
- What data was accessed?
- What tools were called, and in what order?
- What intermediate reasoning steps occurred?
- What decision logic was applied?
Without step-level telemetry, debugging becomes guesswork and errors remain undetected until they compound.
What Step-Level Observability Requires
Vendor guidance and emerging regulatory frameworks now prescribe a dedicated observability layer for agentic systems. At minimum, this means capturing:
- Immutable execution transcripts covering the agent's full decision path
- Tool call logs — every API interaction with its function, arguments, and response
- State change records showing how the agent modified internal or external systems
- Latency metrics: time-to-first-token, overall task duration, and error rates
- Quality signals: hallucination rates, toxicity scores, and PII/PHI leakage detection
- Token and tool-usage cost tracking for financial accountability
In finance, tax, and compliance contexts, every agent action must be auditable — not just the final output. The EU AI Act mandates that high-risk AI systems automatically record events throughout their operational lifetime, with logs retained for at least six months.
India's RBI FREE-AI framework goes further: it requires comprehensive audit trails, human override mechanisms, and formal business continuity plans for any core AI system. For organizations operating across both frameworks, observability isn't optional infrastructure — it's a compliance prerequisite.
Building a Centralized AI Control Plane
As agent deployments multiply across business units, decentralized monitoring breaks down. A centralized AI control plane provides:
- A system of record for all agents across the enterprise
- Centralized policy enforcement and access controls
- Standardized telemetry collection and analysis
- Incident response and rollback capabilities
- Compliance reporting and audit support
Teams that establish this infrastructure before scaling retain the ability to audit, correct, and roll back any agent — a capability that becomes exponentially harder to retrofit once deployments proliferate.
Agentic AI in Finance and Tax Workflows: Where It Creates Real Value
Finance and tax workflows represent one of the highest-value targets for agentic AI. These processes are high-volume, high-variance, and compliance-critical—exactly where agents deliver measurable ROI.
Why finance and tax workflows are ideal candidates:
- High manual effort: Ardent Partners' 2025 benchmarks show the average cost to process an invoice is $9.40, with 9.2 days processing time
- Significant variance: Documents arrive in multiple formats from diverse suppliers across jurisdictions
- Complex validation requirements: Multistep reconciliation against purchase orders, receipts, tax records, and compliance rules
- Regulatory accountability: Every action must be auditable and traceable
High-impact use cases:
Invoice Processing and Reconciliation
Agents extract data from unstructured documents, validate against multiple data sources (POs, GRNs, tax records), perform three-way matching, and flag exceptions while maintaining audit trails. Attainment Labs' 2026 ROI analysis showed a 97% cost reduction (from $7.00 to $0.20 per invoice) and processing time cut from 15–20 minutes to under 2 minutes, achieving 98% accuracy.
GST and VAT Compliance
Agents cross-reference invoices with regulatory databases (GSTR-2A/2B in India, FTA systems in UAE), identify mismatches, block non-compliant payments, and generate audit-ready reports. In India, failure to generate an e-invoice carries penalties of ₹10,000 or 100% of tax due, whichever is higher — making automated compliance validation business-critical.
Credit Risk Assessment
Agents analyze bank statements, financial statements, GST data, and ITR records to assess creditworthiness. Customizable underwriting rules can be applied throughout, with explainability maintained for regulatory review.
Multi-Jurisdictional Compliance Analysis
Agents navigate varying regulations across markets — extracting relevant requirements, comparing against transaction data, and flagging compliance gaps. This replaces work that previously required teams of specialists across each jurisdiction.
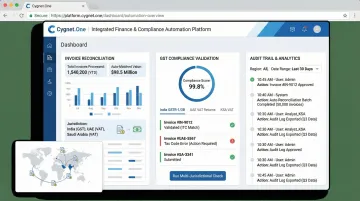
How Cygnet.One Applies This in Practice
These use cases aren't theoretical at Cygnet.One. The platform automates invoice reconciliation, GST compliance, and credit assessment across India, UAE, and Saudi Arabia — processing over 55 million transactions monthly through its tax platform.
The underlying capabilities driving this scale include:
- GLIB OCR technology trained on thousands of document samples, achieving 100% accurate data capture across invoice, BOE, and tax entries
- 400+ automated data validations with three-way reconciliation logic handling high-variance, multistep document workflows
- Full audit traceability on every action, meeting regulatory accountability requirements across all supported jurisdictions
Frequently Asked Questions
What is the difference between agentic AI and generative AI?
Generative AI responds to prompts by producing content like text or images. Agentic AI goes further—it can plan, execute multistep tasks, call tools, and adapt to changing information with minimal human input, taking real-world actions rather than just generating outputs.
How do you know if a workflow is ready for agentic AI?
Readiness depends on variance and standardization. High-variance workflows with unstructured inputs and multistep decision-making are good candidates. Low-variance, tightly governed processes with fixed formats may be better served by simpler rule-based automation.
What are the biggest risks of agentic AI implementation?
The top risks include low-quality outputs that erode user trust, lack of step-level observability leading to undetected errors, and poor human-agent workflow design that results in silent failures or compounding mistakes in production.
How do you measure ROI from agentic AI?
ROI should be measured across multiple dimensions: time saved per task, increased throughput, error rate reduction, and financial outcomes such as cost per transaction or reduced manual headcount. Top-performing invoice automation, for example, can reduce per-invoice processing costs by more than 70%, according to Ardent Partners' accounts payable benchmarking research.
What role do humans play in an agentic AI system?
Humans remain essential for oversight, compliance validation, edge case handling, and high-stakes approvals. Their role shifts from doing repetitive work to guiding, validating, and continuously improving the agents they work alongside.
How should enterprises start their agentic AI journey?
Start with high-impact, well-understood use cases that already have clear success criteria. Invest in proper evaluation frameworks from day one, and treat the first deployment as a learning system — not a finished product — so observability and feedback loops can drive continuous improvement.


