Introduction
An unplanned outage doesn't give you time to improvise. Ransomware locks files within minutes. Hardware failures cascade across dependent systems before anyone picks up a phone.
The financial damage adds up fast. According to Uptime Institute's 2024 outage analysis, 54% of significant outages cost more than $100,000, and 16% exceeded $1 million. For regulated enterprises in finance, healthcare, and tax compliance, the damage extends well beyond infrastructure repair — think regulatory penalties, lost customer trust, and compliance failures.
This guide covers everything IT and operations leaders need to build a disaster recovery plan that actually works:
- What a DRP is and how it differs from business continuity
- The three metrics every plan must define: RTO, RPO, and SLA
- A six-step process for building a DRP from scratch
- Best practices that separate functional plans from shelf documents
- Testing cadences, modern DR architectures, and DRaaS considerations
Key Takeaways
- A disaster recovery plan is a documented, tested strategy for restoring IT systems after any disruptive event
- RTO sets your maximum acceptable downtime; RPO sets your maximum acceptable data loss; SLA is your contractual uptime commitment to customers
- Build your DRP in sequence: BIA first, then risk assessment, asset inventory, roles, procedures, and backup strategy
- Immutable backups, automated failover, and quarterly drills are required for any regulated environment
- Evaluate DRaaS if you lack in-house DR infrastructure or need affordable geographic redundancy
What Is a Disaster Recovery Plan and Why Does It Matter?
NIST defines a disaster recovery plan as "a written plan for recovering one or more information systems at an alternate facility in response to a major hardware or software failure or destruction of facilities." In practice, a DRP covers the full range of disruptive events: natural disasters, ransomware attacks, hardware failure, power outages, and human error.
DR vs. Business Continuity: A Critical Distinction
These two terms are often used interchangeably, but they serve different purposes:
- Business Continuity Planning (BCP): A proactive, organization-wide strategy to keep operations running through and after a disruption
- Disaster Recovery (DR): A reactive, IT-focused subset of BCP that specifically addresses how to restore the technology systems that enable business continuity
DR is a component of BCP, not a substitute for it.
organizations experienced a major outage caused by human error** over a three-year period, with 85% of those incidents stemming from failure to follow procedures, according to Uptime Institute's 2025 analysis. That's a documentation and training problem, and it's precisely what a well-maintained DRP addresses.
Key DR Metrics Every Plan Must Define: RTO, RPO, and SLA
Before you build anything, define these three metrics. Skipping this step means every subsequent decision — backup frequency, infrastructure investment, staffing, and vendor selection — is made without a target.
Recovery Time Objective (RTO)
RTO is the maximum acceptable duration of downtime before business operations must be restored. Per NIST, it represents the time system components can remain in recovery before negatively impacting the mission.
A 4-hour RTO allows for manual restoration and cold-standby architectures. A 30-minute RTO demands pre-provisioned warm infrastructure and automation. That gap often represents a 3–5x difference in infrastructure cost. More than any other metric, RTO shapes your architecture.
Recovery Point Objective (RPO)
RPO defines the maximum acceptable amount of data loss, measured in time. NIST defines it as the point in time to which data must be recovered after an outage.
A 2-hour RPO means backups must run every two hours. Cut that to 15 minutes (the threshold SEBI sets for qualified RTAs and market infrastructure institutions) and scheduled batch backups are no longer sufficient — you need near-continuous replication.
Service Level Agreement (SLA)
SLA is a contractual commitment made to customers or partners about service availability. It differs from RTO and RPO in one important way: it's external and legally binding.
The connection between all three metrics matters:
| Metric | What It Defines | Who Sets It |
|---|---|---|
| RTO | Maximum recovery time | Internal — based on BIA |
| RPO | Maximum data loss tolerance | Internal — based on BIA |
| SLA | Service availability commitment | External — contractual |
If your SLA promises 99.9% uptime — which translates to just 8.76 hours of allowable downtime per year — your internal RTO must be tight enough to honour that commitment. An RTO of 4 hours paired with a 99.99% SLA (52.6 minutes of annual downtime) is a recipe for breach of contract.
Setting Targets by Tier
Not all systems need the same targets. Use your Business Impact Analysis output (covered in the next section) to tier workloads by criticality and assign appropriate recovery windows:
| Tier | System Types | RTO Target | RPO Target |
|---|---|---|---|
| Tier 1 — Mission-critical | Payment processing, e-invoicing, ERP, GST compliance | Under 1 hour | Under 30 minutes |
| Tier 2 — Important | CRM, reporting systems, secondary APIs | 4–8 hours | Up to 4 hours |
| Tier 3 — Non-critical | Internal tools, development environments | 24+ hours | Up to 24 hours |

How to Build a Disaster Recovery Plan: Step-by-Step
Building a DRP is a structured process, not a one-time document exercise. Each step feeds the next.
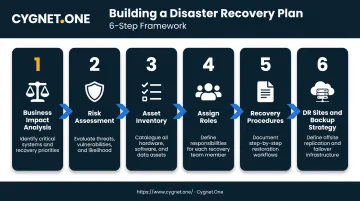
Step 1: Conduct a Business Impact Analysis (BIA)
The BIA maps every business function to its technical dependencies and quantifies what happens when those dependencies fail: revenue loss, regulatory exposure, operational bottlenecks, and reputational damage.
Per NIST SP 800-34, the BIA output directly determines RTO and RPO targets for each function. Without a BIA, recovery priorities are based on opinion, not evidence.
Step 2: Perform a Risk Assessment
A risk assessment evaluates which threats are most likely and most damaging for your specific industry and geography. NIST SP 800-30 Rev. 1 provides a structured model covering:
- Threat sources and events (ransomware, supply chain attacks, natural disasters)
- Vulnerabilities and existing weaknesses
- Likelihood and impact scoring
Use both qualitative approaches (team-based risk workshops) and quantitative methods (historical incident data, insurance actuarial inputs) to avoid blind spots.
Step 3: Build a Tiered Asset Inventory
Catalogue all IT assets: hardware, software, cloud services, data stores, network infrastructure, and third-party integrations. Classify each by operational impact:
- Critical: Operations cannot function without it
- Important: Disruption significantly hampers operations
- Non-critical: Disruption is inconvenient but manageable
For enterprises in finance and tax compliance, high-volume transaction systems meet the Critical threshold almost automatically. A platform processing 55 million transactions per month with direct regulatory integration — such as Cygnet.One's Tax Compliance platform and its GSTN-connected GST filing workflows — requires tightly defined RTO and RPO targets backed by a tested DR architecture.
Getting this classification wrong means under-protecting systems your business cannot afford to lose.
Step 4: Assign Roles and Responsibilities
Every DRP needs named owners, not job titles. Key roles:
- DR Plan Manager — owns overall execution and decision-making during an incident
- Incident Reporter — manages internal escalation and external communications
- Asset Managers — responsible for restoring specific systems within defined timeframes
Each role needs a documented backup contact. Cross-functional coverage matters: IT, security, legal, and business operations all have DR responsibilities that shouldn't be siloed.
Step 5: Document Recovery Procedures and Communication Protocols
The DRP must include:
- Step-by-step recovery runbooks for each critical system
- Pre-written communication templates for internal teams, customers, and regulators
- Defined escalation paths with clear triggers
- A "war room" protocol: a centralized coordination channel, physical or virtual, activated at incident declaration
- Offline or printed copies stored in accessible locations, since primary systems may be unavailable
This last point is frequently overlooked. If your DRP lives only in a cloud document repository and that system goes down during the incident, you're executing blind. Where you store the plan is as important as what it contains — and that connects directly to the infrastructure decisions in the next step.
Step 6: Define Your DR Sites and Backup Strategy
Four primary recovery site models exist, each with different cost and RTO implications:
| Model | Cost | RTO | Best For |
|---|---|---|---|
| On-site cold storage | Low | Hours–days | Non-critical data archives |
| On-site warm backup | Medium | 1–4 hours | Important systems |
| Off-site cold storage | Low–medium | Hours–days | Regulatory retention |
| Off-site warm/cloud | Medium–high | Minutes–1 hour | Mission-critical systems |
The 3-2-1 backup rule, endorsed by CISA, is a foundational standard: keep 3 copies of data, on 2 different media types, with 1 copy stored offsite. For organisations exposed to regional disasters, or those operating across multiple regulatory jurisdictions, multi-region distribution adds an essential layer of resilience.
Disaster Recovery Plan Best Practices
A DRP that exists and a DRP that works are two different things. The practices below determine which category yours falls into.
Prioritize by Business Criticality, Not Gut Feel
Allocate recovery resources based on BIA output. A Tier 1 system like an e-invoicing platform needs hourly or continuous backups, near-zero RTO, and automated failover. A Tier 3 internal wiki can tolerate 24-hour recovery with manual restoration. Mixing those priorities, or treating everything as equally important, wastes budget and delays actual recovery when it matters.
Implement Immutable and Encrypted Backups
Veeam research found that over 93% of cyberattacks target backup storage to force ransom payment. Immutable backups — stored using WORM (Write Once, Read Many) models — prevent attackers from deleting or encrypting your recovery copies.
Non-negotiable requirements for backup security:
- Immutability enforced with a defined retention window
- Encryption at rest and in transit
- Integrity validation on a scheduled basis — not just when you suspect a problem
- At least one air-gapped or offline copy outside the production network
Automate Where Possible, But Maintain Human Oversight
Automated failover, declarative recovery scripts, and pre-deployed pipelines can compress RTO from hours to minutes. Only 13% of organizations use orchestrated workflows as part of DR, according to Veeam's 2024 BC/DR survey — so most teams still rely on manual steps under high-pressure conditions.
Over-automation without oversight creates its own risks. Manual approval gates before production failover are essential, as are trained operators who understand what the automation is doing. Define explicit criteria for when automated failover should trigger — and when a human must authorize it instead.

Keep the DRP as a Living Document
A DRP becomes outdated the moment anything changes — new systems, personnel changes, infrastructure updates, or a new threat vector. Best practice:
- Review and update at minimum every six months
- Trigger an immediate review after any significant architecture change
- Update after every real incident or drill, within a defined timeframe
- Version-control the document and align updates with Failure Mode Analysis (FMA) outputs
Address Cybersecurity Threats Explicitly
Physical disaster scenarios are no longer sufficient. Modern DRPs must include:
- Specific ransomware and cyberattack response procedures
- Threat detection checks during restoration — to confirm the recovered environment isn't re-infected
- Role-based access controls on DR systems
- Multi-factor authentication on all recovery infrastructure
- Data integrity validation before declaring recovery complete
These elements work together rather than in isolation. Cygnet.One's work with a Tax Compliance MSP shows what that looks like in practice: their DR architecture combined automated backup validation, EKS workloads across two Availability Zones, and quarterly failover simulations — achieving 99.95% application availability with a defined 1-hour RTO and 30-minute RPO for Tier-1 services.
Testing and Maintaining Your Disaster Recovery Plan
Testing transforms a disaster recovery plan from a document into a proven capability. Four test types cover the full spectrum:
| Test Type | Risk Level | Purpose |
|---|---|---|
| Tabletop walkthrough | Low | Team familiarity, gap identification |
| Parallel test | Low–medium | Recovery alongside live systems |
| Simulation test | Medium | Controlled scenario exercise |
| Full interruption test | High | Live failover in production |
Recommended cadence:
- Tabletop exercises: quarterly
- Full production-level drills: at least annually
- Surprise drills: after baseline maturity is established (Google's DiRT approach, using real and fictitious outages to expose hidden dependencies)
NIST SP 800-84 sets annual testing as a minimum floor. SEBI requires DR drills at least quarterly for specified market infrastructure institutions — a benchmark worth adopting for any mission-critical financial or tax system, regardless of regulatory mandate.
Frequency alone isn't enough. Each test must produce actionable output:
- Document every gap found during the drill
- Assign a named owner and resolution deadline to each gap
- Update the DRP before the next scheduled test cycle
- Revisit underlying infrastructure if RTO targets cannot be met
If drill results don't change the plan, the testing process itself needs review.
Modern DR Approaches: Cloud, DRaaS, and Automation
Disaster Recovery as a Service (DRaaS)
DRaaS offloads DR infrastructure management to a third-party provider, enabling data replication, automated failover, and on-demand scaling without maintaining dedicated secondary infrastructure. The market reflects genuine enterprise adoption: MarketsandMarkets estimates DRaaS at USD 16.11 billion in 2025, growing to USD 46.09 billion by 2032 at a 16.2% CAGR.
Key considerations before selecting DRaaS:
- Vendor SLA alignment with your internal RTO/RPO targets
- Data sovereignty and residency requirements for your jurisdiction
- Testing rights — can you trigger drills independently, or does the vendor control that?
- Failback procedures — returning to primary systems is a separate process that must be explicitly planned
Cloud DR Architecture Patterns
AWS identifies four DR strategies on a cost-versus-RTO spectrum:
- Backup and restore — lowest cost, highest RTO/RPO; suitable for non-critical workloads
- Pilot light — core components ready to scale; faster recovery at higher cost
- Warm standby — scaled-down functional environment; used for customer-facing or regulated workloads
- Multi-site active/active — lowest RTO/RPO, highest cost; reserved for near-zero tolerance systems
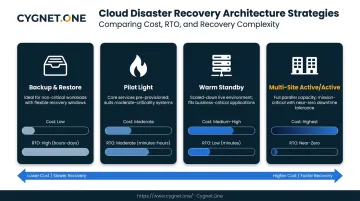
Choose your pattern based on documented RTO targets, not budget alone. A warm standby for a tax compliance platform processing millions of transactions monthly is appropriate; applying the same architecture to internal HR tools is unnecessary spend.
Failback planning is where many teams stumble. When returning to the primary environment after a DR event, data written to the recovery site during the outage must be reconciled carefully — skipping this step is the most common cause of secondary incidents post-recovery.
Frequently Asked Questions
What is SLA vs RTO vs RPO?
RTO is the maximum time your systems can be down before operations are critically impacted; RPO is the maximum data loss you can tolerate, measured in time. SLA is a contractual commitment to external parties about service availability. Your internal RTO and RPO must be set tightly enough to consistently honor your SLA obligations.
What are the key components of an effective disaster recovery plan?
An effective DRP covers a business impact analysis, risk assessment, defined RTO/RPO targets, documented recovery runbooks, assigned roles with backup contacts, and a regular testing schedule. Each component must be documented, tested, and kept current — not just drafted once and shelved.
What is the difference between disaster recovery and business continuity?
Disaster recovery is IT-focused and reactive : it restores specific systems after a disruption. Business continuity is broader and proactive — it ensures the entire organization can continue operating through and after an event. DR is a critical component of BCP, not a replacement for it.
How often should a disaster recovery plan be tested?
At minimum: full DR drills annually and tabletop exercises quarterly, with immediate reviews after major infrastructure changes or real incidents. Regulated environments — particularly financial services and tax compliance — should run technical tests quarterly rather than annually.
What is DRaaS and when should organisations consider it?
DRaaS is a managed service where a third-party provider hosts, manages, and executes disaster recovery infrastructure and procedures. Consider it when your organization lacks in-house DR expertise, cannot maintain dedicated secondary infrastructure, or needs cost-effective geographic redundancy without significant capital expenditure.
How do you prioritise systems in a disaster recovery plan?
Prioritise based on Business Impact Analysis output. Classify systems as Critical, Important, or Non-critical, then assign tightest RTO/RPO targets and highest investment to systems whose failure immediately halts revenue, compliance operations, or customer-facing services. Opinion-based prioritization consistently misallocates DR resources.