Introduction
Global data volumes are projected to reach 393.9 zettabytes by 2028, growing at 24.4% annually according to IDC's Global DataSphere forecast. Legacy systems — Oracle RAC, Teradata, SQL Server, Netezza — were not built for this scale. The result is predictable: performance bottlenecks, rising infrastructure costs, and analytics cycles too slow to drive timely decisions.
For IT decision-makers, data architects, and analytics managers across BFSI, FMCG, IT services, and manufacturing, modernizing to AWS has shifted from a strategic consideration to an execution challenge. This guide covers how to make that transition efficiently without disrupting business continuity.
Key Takeaways
- Modernization moves legacy data warehouses to AWS-native services: Redshift, S3, Glue, and EMR
- Key drivers: rising infrastructure costs, poor scalability, and inability to support real-time analytics or ML workloads
- AWS decouples storage from compute, enabling independent scaling and pay-per-use pricing
- Migration follows four phases — assess, migrate, transform, and optimize — using the AWS 6 R's framework
- BFSI and enterprise teams typically see faster reporting, lower costs, and stronger data governance post-migration
What Is Data Warehouse Modernization on AWS?
Data warehouse modernization is the process of moving from rigid, hardware-bound on-premises systems to scalable, cloud-native analytics architectures on AWS — without discarding existing data assets or business logic.
The shift enables organizations to handle higher data volumes, support both batch and real-time queries, reduce total cost of ownership, and connect with modern ML/AI pipelines inside a managed, governed environment.
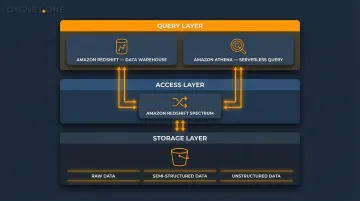
Modernization requires architectural redesign — not a simple migration. That means separating storage from compute, adopting open formats like Parquet and ORC, and enabling federated access across data sources. Three components define this architecture:
- Amazon S3 serves as object storage for the data lake foundation, storing raw, semi-structured, and unstructured data
- Amazon Redshift is the cloud data warehouse that runs analytical queries on structured data
- Together, they form a lakehouse pattern — Redshift Spectrum queries data directly in S3, eliminating redundant data movement
Why Enterprises Are Modernizing Their Data Warehouses on AWS
The Core Pain Points
Legacy data warehouses were designed for predictable, structured workloads. They cannot scale dynamically to meet modern demands. A 2025 Forrester Data and Analytics Survey found that organisations now store 62% of their total data in the cloud on average, with Financial Services and Insurance storing 65% and Manufacturing storing 61%.
Legacy infrastructure compounds costs in predictable ways:
- Legacy systems require provisioning for peak load, leaving expensive hardware underutilised during off-peak periods
- Oracle and Teradata licensing costs compound annually
- On AWS, pay-for-use pricing eliminates over-provisioning waste
An IDC study on Amazon Redshift found that migrating customers achieved a 503% three-year ROI and 43% lower data warehousing platform costs.
Operational Overhead and Analytics Gaps
Database administrators spend considerable time on manual patching, backup management, hardware provisioning, and performance tuning. AWS-managed services like Redshift Serverless and AWS Glue remove this burden, freeing teams to focus on insights rather than infrastructure maintenance.
Legacy warehouses cannot natively support:
- Machine learning model deployment
- Streaming ingestion from IoT or transactional systems
- Federated queries across data lakes
AWS closes these gaps through native integrations: Redshift connects with SageMaker for ML, Kinesis for streaming, and EMR for large-scale Spark processing. Each capability works within a single, unified ecosystem.
Compliance and Governance Imperatives
Operational gaps are one challenge — governance is another. Enterprises in finance, BFSI, and regulated industries require auditable data environments for real-time compliance dashboards and CFO reporting. AWS offers native governance features that are difficult to replicate on-premises:
- AWS Lake Formation provides row and column-level security
- CloudTrail delivers comprehensive audit trails for data access
- Automated compliance reporting supports regulatory requirements
These capabilities are particularly relevant for organisations managing high transaction volumes and regulatory reporting, where data lineage and access controls directly affect audit outcomes.
Key AWS Services That Power Data Warehouse Modernization
Amazon Redshift: The Analytical Engine
Amazon Redshift is a columnar, massively parallel processing (MPP) data warehouse that supports queries across petabytes of structured data. AWS claims Redshift delivers up to 3x better price performance than other cloud data warehouses based on TPC-DS derived benchmarks.
Redshift Serverless removes cluster management overhead entirely:
- Auto-provisions capacity based on workload demand
- Charges only for compute used (measured in RPU-hours)
- Eliminates capacity planning for variable or unpredictable query workloads
Reserved capacity pricing offers up to 73% savings for Reserved Instances and up to 45% for Serverless Reservations compared to on-demand pricing.
Amazon S3: The Data Lake Foundation
S3 stores raw, semi-structured, and unstructured data in native formats with 11-nines (99.999999999%) durability. S3 serves as the storage layer, not a query engine. Redshift Spectrum and Amazon Athena query data directly in S3, enabling a lakehouse pattern that avoids redundant data movement and duplication costs.
AWS Glue: ETL and Data Cataloging
AWS Glue is a serverless data integration service that:
- Crawls data sources to automatically discover schemas and populate the Data Catalog
- Transforms data using managed Apache Spark jobs written in Python or Scala
- Orchestrates pipelines between S3, Redshift, and other sources with event-driven triggers
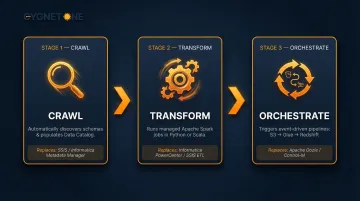
Glue replaces legacy ETL tools like SSIS and Informatica, automating schema conversion and eliminating the need to maintain custom pipeline infrastructure.
AWS Schema Conversion Tool and Database Migration Service
AWS Schema Conversion Tool (SCT) handles the structural lift of migration:
- Converts DDL and stored procedures from Oracle, Teradata, and SQL Server to Redshift-compatible SQL
- Leverages generative AI to automatically convert up to 90% of complex objects, including stored procedures, triggers, and functions
AWS Database Migration Service (DMS) handles ongoing data replication during cutover:
- Performs full data loads from source to target
- Supports Change Data Capture (CDC) for near-real-time synchronisation
- Keeps source systems live while teams test and validate the new environment
Supporting Services That Complete the Architecture
- Amazon EMR runs large-scale Spark and Hadoop processing where data scientists need compute without duplicating data
- Amazon QuickSight provides serverless BI and visualization, integrating directly with Redshift and S3
- Amazon Kinesis and Kinesis Firehose enable streaming ingestion into the data lake for near-real-time analytics pipelines
How Data Warehouse Modernization on AWS Works
Data warehouse modernization runs as a phased program spanning discovery, pilot workloads, iterative migration waves, and post-migration optimisation. The source warehouse remains live throughout migration to preserve business continuity, with workloads migrated in prioritised waves based on business value and technical complexity.
The AWS 6 R's Migration Framework
Teams use the AWS 6 R's to evaluate each workload:
- Rehost - Move as-is (lift-and-shift)
- Replatform - Move with minor optimisation
- Refactor/Re-architect - Redesign for cloud-native architecture
- Repurchase - Replace with SaaS
- Retire - Decommission unused workloads
- Retain - Keep on-premises where necessary
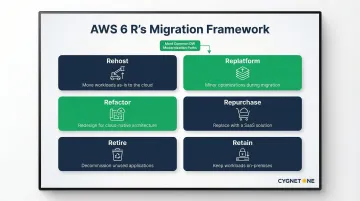
For data warehouse modernization, Replatform (moving to Redshift with optimisation) and Refactor (re-architecting with a lakehouse pattern) are most common.
Phase 1: Assess and Plan
This phase involves:
- Workload discovery - Inventorying ETLs, tables, queries, and dependencies
- Business case development - TCO analysis comparing on-premises vs AWS costs
- Schema assessment - Running AWS SCT to evaluate conversion complexity
- Prioritisation - Identifying highest-priority datasets based on usage frequency and business criticality
Phase 2: Migrate and Transform
Dual-write seeding approach: Load priority datasets into AWS while simultaneously writing to the legacy warehouse. This allows data consumers to test ETLs, reports, and transforms against the new platform before switching.
Key activities:
- Schema and code conversion using AWS SCT
- Data movement using AWS DMS or S3 Transfer
- Validation testing before cutover
- ETL pipeline re-engineering
Teams with deep ERP integration expertise — particularly across Oracle and SAP environments — can accelerate this phase by managing data source mapping and transformation logic for finance, compliance, and GL workloads.
Phase 3: Optimise and Scale
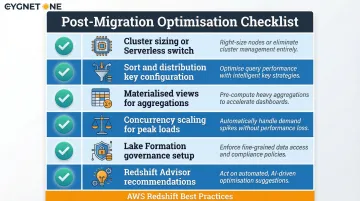
Once migration is complete, the focus shifts to performance tuning and cost efficiency. Key optimisation activities include:
- Adjusting Redshift cluster size or switching to Serverless based on actual usage patterns
- Configuring sort and distribution keys for query performance
- Enabling materialised views for frequently accessed aggregations
- Setting up concurrency scaling for peak workloads
- Implementing Lake Formation for data governance
- Using Redshift Advisor to surface performance recommendations automatically
Common Challenges and Misconceptions
The Cultural Change Misconception
The most common misconception: data warehouse modernization is purely a technology lift-and-shift. It's equally a cultural and organisational shift. Teams must redefine data ownership, retrain users, and adapt governance processes. Organisations that treat it as a pure IT project routinely face adoption failures — not technical ones.
SQL Compatibility Overconfidence
Many teams assume that because Redshift uses SQL syntax similar to Oracle or Teradata, conversion is trivial. It rarely is. Objects that commonly require significant manual rework include:
- Stored procedures with proprietary logic
- Platform-specific functions not supported natively in Redshift
- Sequences and identity column definitions
- Complex or custom data types
The SCT Database Migration Assessment Report flags objects requiring manual intervention. Audit that output before trusting automated accuracy estimates.
Schema-on-Write vs Schema-on-Read Confusion
Teams unfamiliar with cloud analytics often conflate the data lake (S3, schema-on-read) with the data warehouse (Redshift, schema-on-write) and design architectures that duplicate data or fail to leverage federated querying. This drives up costs and latency instead of reducing them.
When AWS Data Warehouse Modernization May Not Be the Right Fit
Scenarios Where Timing Is Premature
Organisations with highly stable, low-volume workloads and no near-term growth trajectory may not generate sufficient ROI to justify migration costs and disruption. Organisations lacking internal cloud skills or a defined data strategy face the same risk — spending heavily without improving analytical outcomes.
Constraints That Reduce Effectiveness
Certain environments place a hard ceiling on how far modernisation can go:
- Legacy codebases with thousands of proprietary stored procedures that cannot be ported cleanly to Redshift
- Embedded BI tools that lack native Redshift connectivity, requiring costly re-integration or replacement
- Data residency mandates that prohibit moving regulated data to cloud infrastructure
In these cases, a phased hybrid architecture — retaining on-premises components while modernising specific workloads — is often the more pragmatic path.
Wrong Reasons for Modernisation
If the primary driver is "everyone else is doing it," the project is already on shaky ground. Without a clearly articulated business problem — slow reports, uncontrolled costs, inability to run ML workloads — modernisation becomes an expensive infrastructure exercise rather than a meaningful improvement to how decisions get made.
Frequently Asked Questions
What is data warehouse modernization?
Data warehouse modernization is the process of migrating legacy on-premises data warehouse systems to cloud-native architectures, replacing rigid hardware infrastructure with scalable, managed services that reduce cost, improve performance, and enable advanced analytics.
How is Redshift different from S3?
Amazon S3 is object storage used as a data lake to store raw and semi-structured data at scale, while Amazon Redshift is a managed cloud data warehouse that runs analytical SQL queries on structured data. In a modernized architecture, S3 acts as the storage foundation and Redshift queries data stored within it via Redshift Spectrum.
What are the 6 R strategies for AWS?
The six strategies are Rehost, Replatform, Refactor, Repurchase, Retire, and Retain. For data warehouse modernization, Replatform (moving to Redshift with optimization) and Refactor (re-architecting with a data lakehouse pattern) are the most commonly applied.
How long does it take to modernize a data warehouse on AWS?
Timelines depend on warehouse size, schema complexity, and ETL workload volume. A pilot migration of priority workloads may take weeks, while a full enterprise migration across multiple waves typically spans six to eighteen months.
What is the cost of migrating a data warehouse to AWS?
Migration costs depend on source complexity, services used, and whether professional services are engaged. Organizations commonly offset this investment through savings on legacy hardware and licensing — Redshift Reserved Instances can reduce compute costs by up to 75% compared to on-demand pricing.
What is Amazon Redshift Serverless?
Amazon Redshift Serverless automatically provisions and scales data warehouse capacity based on workload demand, eliminating cluster management and charging only for compute used — making it especially suited for variable or unpredictable query workloads.