Introduction
Financial institutions are generating more data than ever—from digital transactions and real-time payments to regulatory reporting and AI-driven decisioning. Yet the infrastructure beneath it all hasn't kept pace. According to industry analysis, 60-80% of large banks still rely on mainframe-COBOL cores that consume 65-80% of IT budgets on maintenance alone, leaving little room for innovation.
Most firms can't access their data fast enough—or trust it enough—to act on it. Three compounding problems make this urgent:
- Compliance risk: Data infrastructure failures have cost individual institutions more than $100 million in regulatory penalties
- Fraud exposure: Batch processing lags of hours or days create dangerous windows compared to sub-second fraud detection requirements
- Innovation drag: IT budgets consumed by legacy maintenance leave little capacity for AI, analytics, or digital product development
Modern data infrastructure closes this gap. This guide covers what modern data infrastructure means for financial services, its key components, real-world use cases, compliance implications, and a practical implementation roadmap that delivers measurable ROI without disruptive "big bang" migrations.
Key Takeaways
- Modern data infrastructure combines cloud-native storage, real-time pipelines, unified governance, and AI-readiness into one integrated architecture
- Legacy systems create data silos, slow decision-making, and increase compliance risk—gaps that compound as regulatory pressure grows
- Core use cases include real-time fraud detection, automated credit decisioning, regulatory reporting, and customer analytics
- Phased implementation—starting with high-value data domains and embedding governance early—delivers faster ROI than all-at-once migrations
- Multi-jurisdiction compliance (GST, ZATCA, PEPPOL, VAT) must be built into the architecture from day one—not bolted on later
Why Legacy Data Infrastructure Falls Short in Financial Services
Legacy architectures suffer from structural limitations that make them ill-suited for modern financial operations. Siloed databases, batch-processing constraints, and on-premises storage cannot scale to handle the velocity and variety of today's financial data. Structured transactions, unstructured documents, and streaming market feeds each require different processing approaches that legacy stacks simply weren't built to support.
Compliance Risk Accumulates Fast
Legacy systems make audit trails, data lineage, and cross-jurisdiction reporting genuinely difficult to maintain. Every new regulation requires expensive custom workarounds rather than native support:
- FATF guidelines demand real-time transaction monitoring legacy batch systems can't deliver
- GDPR and data residency rules require granular access controls that siloed databases struggle to enforce
- Local e-invoicing mandates (India's IRP, UAE's FATOORAH, Saudi Arabia's ZATCA) need direct ERP integration, not manual processes
The cost of falling short is concrete. In 2026, Canaccord Genuity faced $100 million in combined penalties from FinCEN and the SEC because its AML surveillance reports "went completely unreviewed for months or years at a time" — a direct consequence of infrastructure that couldn't surface the right data to the right people.
The AI Readiness Gap
Legacy infrastructure wasn't designed to feed real-time ML pipelines. Before data can reach a fraud model or credit scoring engine, it must be moved, cleaned, and reformatted — adding latency that has direct financial consequences.
Research shows batch systems introduce fraud detection latencies of 6.8 hours on average. During that window, criminals execute an average of 8.2 additional unauthorized transactions per compromised account. Modern streaming architectures cut that exposure to 1.8 minutes: a 226x improvement that translates directly into prevented losses.

Core Components of a Modern Financial Data Infrastructure
Data Ingestion and Integration Layer
Modern architectures use event-driven pipelines and API-first connectors to ingest data in real time from core banking systems, ERP platforms, payment networks, and external market feeds—eliminating batch delays entirely. Industry surveys show that 86% of IT leaders now consider data streaming a strategic priority, with the market for event streaming in banking reaching $2.18 billion in 2024.
Real-world implementations demonstrate the impact:
- Krungsri Bank (Thailand) implemented Apache Kafka-based streaming to detect and block fraudulent transactions in under 60 seconds
- Intesa Sanpaolo (Italy) uses Apache Flink with Change Data Capture (CDC) to replicate customer data in real-time from legacy mainframes to modern databases
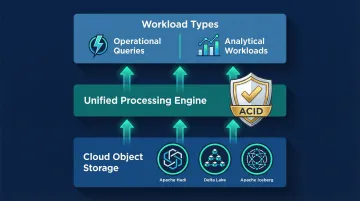
Cloud-Native and Hybrid Storage Architecture
The shift from monolithic data warehouses to a data lakehouse model combines structured and unstructured storage, enabling both operational queries and analytical workloads on a single platform without data duplication. Leading financial institutions have adopted this architecture:
- Nomura achieved a 13.9% performance increase after transitioning from Hadoop to a lakehouse
- Capital One reported job completion speeds up to 60x faster using a Delta Lake-backed Feature Hub
- Barclays uses a lakehouse for FinCrime monitoring, leveraging ACID guarantees and data lineage for regulatory reporting
The lakehouse architecture provides ACID transactions on cloud object storage via open formats like Delta Lake, Apache Iceberg, and Apache Hudi: critical for data reliability, auditability, and regulatory compliance in highly regulated environments.
Real-Time Processing Layer
Stream processing engines allow financial institutions to act on data as it arrives, covering millisecond-level fraud signals, live credit assessments, and dynamic risk pricing. Research indicates that real-time fraud detection can reduce fraud losses by up to 60% compared to batch systems, since it stops subsequent fraudulent transactions before processing windows close.
That ROI is driving rapid adoption: over 50% of banks and insurance firms had stream processing in production by 2022, and 84% of organizations reported 2x to 10x returns on their data streaming investments.
Data Governance and Master Data Management
A trusted, unified record for each customer, transaction, and financial entity is the backbone of accurate analytics and regulatory reporting. MDM prevents conflicting definitions across business units, a gap that directly causes regulatory failures when customer records, invoice amounts, or KYC data are inconsistent.
Poor data quality costs organizations an average of $12.9 million per year, according to Gartner research. Financial institutions implementing cloud-based MDM have achieved up to 85% faster data onboarding, reducing provisioning time from weeks to days.
AI/ML Enablement Layer
A modern data platform serves as the foundation for training and deploying models at production scale. This includes vector databases, model registries, and feature stores that allow financial AI applications to operate in production environments.
Production deployments are accelerating:
- Banco Hipotecario (Argentina) uses MLflow model registry to manage and version models, with measurable gains in customer retention
- Varo (Neobank) built an internal feature store as a core component of its ML platform for low-latency production inference
- Over 300 AI use cases run in production at J.P. Morgan, requiring robust MLOps infrastructure to manage the full portfolio
Cygnet.One in Practice
Cygnet.One's finance transformation platform processes over 55 million transactions per month, generating real-time CFO dashboards and ITC insights for lenders, NBFCs, and enterprises. The platform currently handles 15–19% of India's e-invoices, with over 412 million generated to date.
That scale is backed by 99% uptime and 250+ successful ERP integrations across multiple jurisdictions, reflecting what production-grade financial data infrastructure looks like when operational reliability and regulatory compliance are built in from the start.
Key Financial Services Use Cases Enabled by Modern Data Infrastructure
Fraud Detection and Prevention
Real-time streaming data combined with AI models enables anomaly detection at the transaction level—reducing false positives and catching sophisticated fraud patterns that batch systems miss entirely. Research shows that modern streaming architectures achieve detection latencies of 80-120 milliseconds, with end-to-end ML scoring as low as 42 milliseconds.
The business impact is measurable: institutions moving to real-time fraud detection report fraud loss reductions of up to 60%, as the shortened detection window prevents criminals from executing multiple fraudulent transactions during batch processing delays.
Credit Assessment and Loan Decisioning
Modern infrastructure aggregates alternative data signalssuch as invoice histories, cash flow patterns, and supplier networks to enable automated, risk-optimized credit scoring. RBL Bank's Rural Vehicle Finance product demonstrates this in practice: loan decisioning compressed from 48-72 hours down to 36 hours total, achieving a 3x productivity increase through Business Rules Engines, API integrations, and eKYC verification.
The accelerated cycle breaks down as:
- 10 minutes for login and application
- 2 hours for sanction
- 24 hours for disbursal
Cygnet.One's platform supports similar capabilities through its Finalyze product, which enables data-driven invoice-based credit decisions for NBFCs and lenders, leveraging real-time transaction data for automated credit assessment.
Regulatory Reporting and Audit Trails
Unified data lineage and governance layers make it possible to generate accurate, on-demand compliance reports across multiple jurisdictions without manual reconciliation. Analyst findings indicate that centralized data repositories and process automation reduce regulatory reporting production times by 30-50%. Specific implementations have achieved even more dramatic results: a US bank working with DQLabs achieved 40% faster time-to-insight and 75% improvement in regulatory data accuracy.
The European Central Bank explicitly states that monthly or quarterly risk reports should not require more than 20 working days to produce—a standard that legacy batch systems struggle to meet but modern platforms handle routinely.
Customer 360 and Personalization
A unified data platform consolidates transaction histories, product holdings, and behavioral data to power individually targeted financial products and proactive advisory services. Implementations consistently report improvements in product adoption, cross-sell rates, and customer retention when institutions can access complete customer data in real-time rather than through fragmented legacy systems.
High-Frequency and Algorithmic Trading Analytics
At the far end of the performance spectrum, capital markets use cases push infrastructure to its limits: sub-millisecond latency, terabyte-scale ingestion, and real-time risk dashboards.
FPGA-based market data parsing established a foundational hardware latency benchmark of 4 microseconds—a threshold that continues to shape architecture decisions today. Trading firms require this level of processing speed to react to market changes before prices shift, making low-latency infrastructure a non-negotiable design constraint rather than a performance goal.
Building a Regulatory-Compliant and Governed Data Infrastructure
Embedding Compliance in Infrastructure Design
Compliance must be embedded in infrastructure design, not bolted on later. Data residency requirements, audit log mandates, consent management, and e-invoicing regulations impose specific technical requirements on how data is stored, transmitted, and retained.
The table below maps major jurisdictions to their core technical mandates:
| Jurisdiction | Framework | Core Technical Requirements |
|---|---|---|
| India | GST e-Invoicing (IRP/GSP) | JSON schema (Form GST INV-1), REST API integration, IRN hash generation, digital signatures, QR codes |
| Saudi Arabia | ZATCA (FATOORA) | UBL-based XML, REST APIs (Clearance + Reporting), Cryptographic Stamp Identifier (CSID), ECDSA signatures |
| UAE | FTA Electronic Invoicing | PINT-AE (Peppol UAE) XML format, PEPPOL network (four-corner model), AS4 protocol, Peppol PKI certificates |
| EU | PEPPOL BIS Billing 3.0 | UBL Invoice 2.1 XML, AS4 profile, SML/SMP infrastructure, Peppol PKI for transport security |
| UK | HMRC Making Tax Digital | JSON schemas, REST APIs, OAuth 2.0, fraud-prevention headers, digital links, TLS encryption |

The cost of retrofitting compliance is substantial. Aggregate data shows that operating costs have surged by over 60% for retail and corporate banks compared to pre-crisis levels, with financial-crime compliance alone running approximately $200 billion annually worldwide.
Building compliance in after the fact drives up operational expenses through constant manual reconciliation, bespoke scripting, ongoing remediation, and elevated penalty risk.
Data Lineage and Observability
Tracking where every data point originated, how it was transformed, and who accessed it is essential for both internal audits and external regulatory submissions. Modern platforms must make this lineage queryable and automated. Adoption data shows that 53% of data and AI leaders have already implemented data observability tools, with an additional 43% planning adoption within 18 months.
Regulators explicitly require this capability. The Basel Committee's BCBS 239 principles on risk data aggregation emphasize data lineage as a supervisory focus, while the ECB's guide on risk data aggregation notes that banks must create enterprise-wide data governance frameworks that include "data lineage and data taxonomy."
Key capabilities a compliant lineage system must support:
- End-to-end audit trails from data origin through every transformation
- Queryable lineage accessible to both internal teams and regulators
- Automated tagging and classification at ingestion
- Role-based access controls with timestamped access logs
Data Quality Management as a Compliance Prerequisite
Inaccurate or inconsistent data—duplicate customer records, mismatched invoice amounts, incomplete KYC records—directly causes regulatory failures. Automated data quality checks at ingestion prevent downstream errors that lead to penalties. The 2026 Nationwide Building Society case demonstrates this: the FCA imposed a £44 million penalty for "ineffective systems for keeping up-to-date due diligence and risk assessments" and "flawed systems and weak controls" that prevented effective money laundering risk management.
Cygnet.One's Compliance Infrastructure
Cygnet.One is recognized across six major compliance frameworks—GSTN (IRP + GSP), ZATCA, FTA, HMRC, PEPPOL, and MDEC—making it one of the few platforms that satisfies overlapping global mandates without requiring separate regional implementations. This shows how financial data infrastructure can be architected for compliance from the start, not retrofitted afterward.
Core compliance capabilities include:
- 400+ data validations enforced at ingestion
- 3-way reconciliation across E-Way Bills, GST Returns, and E-Invoicing data
- Automated vendor compliance checks against GSTN and MCA databases
- SOC 2 Type II certified audit trails for regulatory submissions
Multi-region operations span APAC, the Middle East, Europe, Africa, and Oceania—embedding compliance as a structural capability rather than a manual process layer.
Implementation Roadmap: Moving from Legacy to Modern Data Architecture
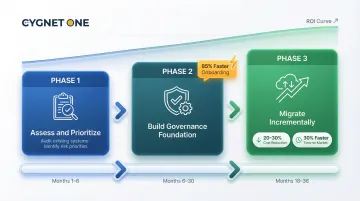
Phase 1: Assess and Prioritize
Start with a data domain audit to identify the highest-value, highest-risk data sets—typically customer master data and transaction records. Avoid attempting a full enterprise migration in a single pass. Industry research from McKinsey, Gartner, and Deloitte favors phased migration over "big bang" approaches, as incremental methods reduce the operational risk of replacing core systems.
Key activities:
- Audit current data domains and identify critical dependencies
- Assess technical debt, compliance blockers, and cost risks
- Prioritize domains based on business value and regulatory urgency
- Define success metrics (report processing time, fraud detection accuracy, loan decisioning speed)
Typical duration: 3-6 months for assessment and roadmap development
With priorities confirmed and risks mapped, the next step is building infrastructure that data can actually trust.
Phase 2: Build the Foundation with Governance First
Deploy MDM, data cataloging, and lineage tooling before migrating workloads. Embedding governance at the start prevents technical debt and ensures migrated data is immediately trustworthy for analytics and compliance. This approach delivers measurable benefits: Citizens Bank achieved up to 85% faster data onboarding by implementing cloud-based MDM for reference data, reducing provisioning time from weeks to days.
Key activities:
- Implement Master Data Management for customer, product, and reference data
- Deploy data cataloging and lineage tracking systems
- Establish data quality rules and automated validation checks
- Create unified data governance frameworks across business units
Typical duration: 12-24 months for foundation deployment
Once governance is embedded, workload migration can proceed domain by domain without compromising data integrity or audit trails.
Phase 3: Migrate Incrementally and Validate with Business Outcomes
Move workloads domain by domain, validating each migration against defined KPIs. Hybrid architectures (on-premises + cloud) are a practical interim state for most financial institutions—industry data shows that 71% of core banking deployments remain on-premises as of 2024, with 56% of organizations increasing their use of mainframes within hybrid IT environments.
Key activities:
- Execute secure migration with automation and governance controls
- Validate each domain migration against business outcome KPIs
- Implement rollback planning and zero-data-loss protocols
- Optimize performance, tune CI/CD pipelines, and establish compliance checkpoints
Typical duration: 18-36 months for full enterprise modernization, with initial wins demonstrable within the first 3-6 months
Programs that follow this phased structure typically yield 20-30% cost reductions over 3-5 years. Time-to-market improves by roughly 30% and build costs drop by around 20%—outcomes that depend on automation discipline, open-source platform choices, and treating migrated data as the authoritative record for downstream analytics.
Frequently Asked Questions
What is financial services infrastructure?
Financial services infrastructure is the combination of technology systems—data platforms, networks, processing engines, and compliance tools—that financial institutions use to store, process, and act on financial data across their operations. It includes everything from core banking systems to real-time fraud detection pipelines.
What is the new technology for financial services?
Key emerging technologies reshaping financial services include cloud-native data platforms, real-time streaming architectures (Apache Kafka, Apache Flink), AI/ML-powered decisioning engines, and blockchain-based transaction verification. These are converging into unified modern data platforms that support multiple workloads simultaneously.
What are the 4 pillars of big data?
The four pillars are Volume (massive scale of financial transactions), Velocity (speed at which data is generated and must be processed), Variety (structured transactions, unstructured documents, market feeds), and Veracity (accuracy and trustworthiness of the data). All four are critical for financial services.
How does modern data infrastructure support regulatory compliance in finance?
Modern infrastructure embeds compliance through automated data lineage, real-time audit trails, data residency controls, and native integrations with regulatory reporting frameworks (GST, ZATCA, PEPPOL, VAT). This makes compliance a built-in capability rather than a manual, error-prone process.
What is the difference between a data warehouse and a data lakehouse in financial services?
A data warehouse handles structured, pre-processed data optimized for reporting, while a data lakehouse combines the flexibility of a data lake (storing raw, unstructured data) with warehouse-style querying. This gives financial institutions one platform for both operational and analytical workloads without data duplication.
How long does it take to modernize data infrastructure for a financial institution?
Timelines vary by organization size and complexity, but phased approaches (starting with high-priority data domains) typically deliver initial wins within 3-6 months. Full enterprise modernization spans 18-36 months, with hybrid architectures serving as a practical interim state for most large institutions.