Introduction
Global data volumes are on track to reach 182 zettabytes by 2025, and most legacy on-premises warehouses weren't built to handle that load. Query performance degrades, ETL pipelines breach SLAs, and infrastructure costs keep climbing — all while business decisions wait on data that should already be available.
This guide is for data architects, IT leaders, and enterprise teams — particularly in data-intensive sectors like BFSI, FMCG, and IT services — who are evaluating or actively planning a move to AWS. It covers the end-to-end migration process, the AWS services involved, and the pitfalls that derail even well-funded projects.
Key Takeaways
- Data warehouse migration moves analytical workloads from legacy systems to cloud-native AWS services like Amazon Redshift
- Legacy warehouses struggle to scale, carry high maintenance costs, and block modern analytics use cases
- Migration runs through four phases: assessment, schema conversion, data transfer, and cutover
- AWS offers dedicated tools for each phase — SCT handles schema conversion, DMS handles data movement
- Choosing the right migration strategy — one-step, two-step, or wave-based — determines how smoothly the cutover goes
What Is Data Warehouse Migration to AWS?
Data warehouse migration to AWS is the process of moving an organization's existing data warehouse—its schemas, tables, ETL pipelines, stored procedures, and historical data—from on-premises or legacy systems to AWS cloud-native services.
It's a distinct discipline from other cloud transitions:
- General cloud migration covers applications and infrastructure broadly
- Database migration typically targets transactional systems (OLTP)
- Data warehouse migration focuses specifically on analytical workloads, reporting environments, and BI pipelines
The objective goes beyond lifting and shifting existing infrastructure into the cloud. Organizations use this transition to rebuild for scalability, faster query performance, and cost efficiency—moving from fixed-capacity, batch-oriented systems to elastic platforms that support real-time analytics and machine learning workloads.
Why Organizations Migrate Their Data Warehouses to AWS
Scalability Failure
Traditional data warehouses are architected for fixed capacity. Compute and storage are tightly coupled—to increase storage, you must also add compute power, leading to underutilized resources and higher costs. These systems can't automatically scale to handle load peaks or bursts in query activity.
This leads directly to performance degradation, query timeouts, and ETL failures. Before re-architecting on AWS, Vanguard's analysts faced a 10-minute query timeout and frequent ETL SLA failures that disrupted critical business processes. The EOS Group experienced significant processing delays as their data volume grew 15% annually, unable to handle load peaks effectively.
Total Cost of Ownership
On-premises data warehouse environments carry high CapEx in hardware, licensing, and maintenance, plus ongoing operational overhead. AWS shifts this to a pay-as-you-go OpEx model where you only pay for compute and storage actually consumed.
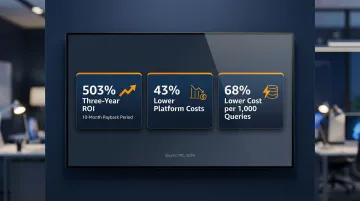
The financial case is well-documented. A 2024 IDC study on Amazon Redshift users found:
- 503% three-year ROI with a 10-month payback period
- 43% lower data warehousing platform costs
- 68% lower cost per 1,000 queries
A separate Forrester study calculated a three-year risk-adjusted ROI of 162% with $5.29 million in net present value.
Agility for Modern Analytics
Legacy architectures are ill-suited to real-time ingestion, machine learning integration, and multi-source analytics. They lack the elasticity and automation needed for today's analytical demands.
AWS services provide these capabilities through Amazon Redshift, Amazon Athena, and Amazon QuickSight. Organizations can query data lakes directly, scale compute independently from storage, and integrate with ML services—none of which are feasible on traditional systems.
Security and Compliance Requirements
Regulated industries—particularly BFSI and enterprise finance—face increasing pressure to meet data governance, audit, and compliance mandates. AWS provides built-in encryption, fine-grained access controls, and compliance certifications that reduce the burden of managing these controls in-house.
AWS services like Redshift and Lake Formation are in-scope for PCI DSS, SOC 1/2/3, and ISO 27001—covering the compliance requirements most enterprises face.
For India-based BFSI clients, this is especially relevant. The Reserve Bank of India's 2018 circular mandates that payment system data be stored only in-country, making AWS's India regions a compliant default for organizations handling large transaction volumes.
Strategic Modernization
AWS migration is becoming an industry standard for enterprise data modernization. A 2024 Deloitte survey found that 52% of banking and capital markets organizations have already migrated more than half of their data to the cloud for analytics initiatives. For these organizations, the outcome is a unified analytics environment—centralized data, reduced redundancy, and a foundation for modern data lakehouse architecture.
How Data Warehouse Migration to AWS Works: Step-by-Step
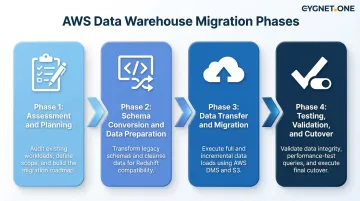
Data warehouse migration follows a structured, phased process: discovery, transformation, movement, and validation. The right strategy depends on database size, network bandwidth, acceptable downtime, and data change rate. Common approaches include one-step (small datasets), two-step (medium/large), and wave-based (complex MPP environments).
Step 1: Assessment and Planning
Conduct a thorough inventory of your current environment:
- Catalog all data sources, table sizes, stored procedures, ETL workflows, BI dependencies, and query patterns
- Assess data quality issues, data volumes, and identify migration complexity
- Output: migration assessment report and business case
Define migration goals, timeline, resource requirements, and risk mitigation strategies. Confirm stakeholder alignment and governance sign-off before moving to schema conversion.
Step 2: Schema Conversion and Data Preparation
Use AWS Schema Conversion Tool (SCT) to analyze the source schema and auto-convert database objects (tables, views, stored procedures, and functions) to Amazon Redshift-compatible formats. SCT generates an assessment report highlighting objects that require manual intervention.
Cleanse and prepare data before migration:
- Deduplicate records
- Resolve data type mismatches
- Remove incomplete or stale data
- Validate transformations with data owners and end-users (data analysts, BI teams)
Data cleansing before migration is far less costly than cleaning after cutover when downstream BI reports and analytics are already running.
Step 3: Data Transfer and Migration
Before executing data movement, set up the target Amazon Redshift environment:
- Configure security, IAM roles, VPC networking, and encryption
- Define distribution keys and sort keys optimized for your query patterns
- Establish workload management (WLM) queues for query prioritization
With the environment ready, execute data movement using:
- AWS DMS for ongoing replication with Change Data Capture (CDC)
- AWS Snowball Edge for large offline bulk transfers (note: no longer available to new customers as of 2026)
- AWS DataSync for file-based transfers
The approach: run an initial full-load migration, then use CDC to sync records that changed in the source during the migration window.
Step 4: Testing, Validation, and Cutover
Run comprehensive data integrity checks:
- Compare source and target row counts, checksums, and query outputs
- Perform user acceptance testing with actual BI reports and analytics workloads
- Establish performance benchmarks against pre-migration SLAs
Execute the cutover using a planned maintenance window to minimize disruption:
- Switch ETL pipelines, BI tools, and applications to the new AWS target
- Define rollback procedures and ensure old environment remains available until the new system is validated in production
- Use point-in-time snapshots as your primary rollback strategy
Key AWS Tools and Services for Data Warehouse Migration
Amazon Redshift
The primary target for data warehouse migration—a fully managed, petabyte-scale MPP cloud data warehouse that uses columnar storage and parallel query execution. Key capabilities include:
- RA3 instances that separate compute and storage for independent scaling
- Redshift Spectrum for querying S3 data directly without loading into tables
- Concurrency Scaling to automatically handle fluctuating query loads
- AQUA (Advanced Query Accelerator) for hardware-accelerated query performance
Redshift integrates tightly with the broader AWS analytics ecosystem, using S3 as underlying storage, AWS Glue for metadata management, and AWS Lake Formation for governed data access.
AWS Schema Conversion Tool (AWS SCT)
Converts source database schemas from Oracle, Teradata, Greenplum, IBM Netezza, MS SQL Server, and others to Amazon Redshift-compatible format. SCT also converts embedded SQL in application code and ETL scripts.
SCT's data migration agents extract and upload data in parallel to Redshift. For large tables, the tool leverages native table partitions to create parallel subtasks, speeding up extraction. Once conversion runs, SCT generates an assessment report that details conversion success rates and flags objects requiring manual rework.
Once schemas are converted, the next challenge is moving the data itself—that's where AWS DMS takes over.
AWS Database Migration Service (AWS DMS)
The primary service for continuous data replication and migration. DMS supports homogeneous and heterogeneous migrations and works with both relational databases and data warehouse sources. It enables Change Data Capture (CDC) for near-zero downtime cutovers.
For analytical migrations, DMS uses an intermediate S3 bucket as a staging area. It writes data to files in S3 and then issues COPY commands to load into Redshift tables. AWS published a case study where Phreesia replicated a 30 TB SQL Server database to S3 in just 2 days using DMS.
Supporting Services
Three additional AWS services round out a typical migration stack:
- AWS Glue — Serverless ETL for data cataloging and transformation. Its Data Catalog also serves as a metadata repository for Redshift Spectrum queries.
- AWS Lake Formation — Governs data lakes running alongside the warehouse, enforcing row-level and column-level security that Redshift Spectrum honors when querying S3.
- AWS DataSync — Accelerates file-based data transfers when network bandwidth is available but manual processes are too slow.
Common Challenges and Misconceptions in AWS Data Warehouse Migration
Misconception: Lift-and-Shift Is Sufficient
Many teams assume migrating a data warehouse means simply copying data to the cloud in the same format. In practice, legacy schemas, stored procedures, proprietary SQL dialects, and ETL logic almost always require conversion and re-engineering to work efficiently in Amazon Redshift.
A pure "Rehost" strategy typically results in ballooning costs and lagging query performance — followed by a costly modernization effort anyway. For data warehouse workloads, "Replatform" or "Refactor" strategies deliver the cloud-native performance gains that justify the migration in the first place.
Mistake: Neglecting Data Quality Before Migration
Teams that skip pre-migration data cleansing carry over years of duplicate records, broken relationships, and inconsistent formats into the new environment. A 2025 survey found that 94% of IT leaders reported slower or similar system performance after migration, often due to inadequate data quality and testing.
Cleaning data before migration costs far less than fixing it post-cutover, when downstream BI reports and analytics are already live. Conduct thorough data profiling, deduplication, and validation before the transfer phase.
Challenge: Underestimating Schema Conversion Complexity and Testing Scope
Complex stored procedures, non-standard SQL functions, and tightly coupled ETL dependencies frequently require manual intervention beyond what AWS SCT can automate. Organizations should allocate realistic timelines for testing, especially user acceptance testing (UAT) with business stakeholders.
Common pain points that extend timelines include:
- Proprietary SQL functions with no direct Redshift equivalent
- Stored procedures embedded in ETL pipelines requiring logic rewrites
- Hard-coded schema references across reporting layers
- Insufficient test data coverage for edge-case validation

Cygnet.One's data engineering practice supports enterprises in BFSI, FMCG, and IT services through this phase — using structured migration assessments and proven conversion frameworks to reduce the manual effort involved in schema remediation and test planning.
Frequently Asked Questions
What are the 4 phases of cloud migration?
The four phases are: Assess (audit your current environment and identify gaps), Plan (design target architecture and choose migration strategy), Migrate (execute data and workload transfer), and Optimize (tune performance, manage costs, and decommission legacy systems).
What are the 7 migration strategies in AWS?
AWS's 7 Rs are: Retire, Retain, Rehost (lift-and-shift), Relocate, Replatform, Repurchase, and Refactor/Re-architect. For data warehouse migration, Replatform and Refactor are the most commonly applied strategies to leverage cloud-native capabilities.
Which AWS service is used for data migration?
AWS DMS handles database and data warehouse replication, AWS SCT converts schemas, AWS DataSync manages file-based transfers, and AWS Snowball Edge (for offline, large-scale transfers) enables physical data movement at scale.
What is AWS data migration?
AWS data migration is the process of moving data from on-premises, legacy, or third-party systems to AWS cloud storage, databases, or analytics services, using AWS's migration tools to maintain security and minimize downtime during transfer.
Does AWS SCT migrate data?
AWS SCT primarily converts schemas and database objects — tables, views, and stored procedures — rather than moving data itself. SCT's data migration agents pair with AWS DMS to handle the actual extraction and loading into Amazon Redshift.
Is data migration part of data engineering?
Yes, data migration is a core component of data engineering. It involves designing pipelines, transforming schemas, ensuring data quality, and validating data integrity throughout the move. Data engineers typically own the ETL conversion and schema mapping in cloud migration projects.