
Introduction
Picture this: it's the last Friday of the month, payroll processing is mid-run, and your Azure-hosted ERP goes dark. No failover kicks in. No recovery plan exists. Your HR team is fielding calls, leadership is demanding answers, and every minute of silence costs money — real money.
This isn't hypothetical. According to ITIC's 2024 Hourly Cost of Downtime Report, 90% of mid-size and large enterprises say one hour of downtime costs more than $300,000. For 41% of those organizations, the figure climbs between $1M and $5M per hour.
Azure spans 70+ regions and 400+ datacenters — but that infrastructure redundancy doesn't protect you on its own. You still need a documented, tested recovery plan.
This guide covers everything required to build one:
- Core DR concepts and terminology
- Key Azure services for disaster recovery
- Architecture patterns for SMBs and enterprises
- A step-by-step plan-building framework
- Best practices that hold up under real pressure
Key Takeaways
- Azure DR uses Azure Site Recovery (ASR) and Azure Backup to replicate workloads and restore operations after disruption
- Define RTO and RPO targets first — they determine which architecture and tools are appropriate for your environment
- Most enterprises choose warm standby for the cost-to-recovery balance it offers
- Beyond infrastructure, a complete DR plan documents human roles, escalation paths, and communication protocols for when systems go down
- Microsoft recommends quarterly test failovers per application — unexercised DR plans routinely fail when real incidents occur
What Is Azure Disaster Recovery?
Azure disaster recovery is a structured set of policies, tools, and procedures that restore data, applications, and infrastructure following an unplanned disruption — whether caused by hardware failure, cyberattack, natural disaster, or human error.
How Azure DR Differs from Traditional DR
Traditional DR meant maintaining a secondary physical datacenter: expensive hardware sitting idle, waiting for a failure that might never come. Azure changes that model entirely:
- No secondary datacenter — recovery infrastructure runs in Azure's cloud, provisioned on demand
- Built-in geo-redundancy through Azure region pairs, which support prioritized recovery sequencing
- Pay-per-use pricing — cold standby environments cost a fraction of pre-provisioned physical sites
- Cloud-native replication managed through a single portal
These differences matter most when speed and cost are both on the line — which is exactly where BCP and DR planning intersect.
DR vs. Business Continuity
These terms are related but not interchangeable. Business continuity planning (BCP) covers the full organizational response to disruption — communications, operations, supply chain, people. Disaster recovery is a subset of BCP focused specifically on restoring IT systems. A well-constructed Azure DR plan feeds directly into the broader BCP framework.
| Scope | Business Continuity | Disaster Recovery |
|---|---|---|
| Focus | Full organizational response | IT systems restoration |
| Covers | People, ops, supply chain | Data, apps, infrastructure |
| DR relationship | Parent framework | Subset/component |
Key Azure DR Concepts to Know Before You Plan
Three foundational concepts shape every Azure DR decision — from tool selection to architecture design.
RTO and RPO
Microsoft defines these precisely:
- Recovery Time Objective (RTO): The maximum acceptable duration of downtime before operations must be restored
- Recovery Point Objective (RPO): The maximum acceptable data loss, measured in time — how far back you can afford to roll back
RTO and RPO are contractual commitments, not targets to revisit later. They determine which Azure services, replication frequencies, and architectures you need. Setting RTO at 15 minutes but configuring cold standby will guarantee failure during an actual incident.
Workload Criticality Tiers
Your RTO and RPO targets should vary based on how critical each workload is. Microsoft's Well-Architected guidance recommends classifying workloads by criticality:
| Tier | Example Workloads | Typical RTO/RPO |
|---|---|---|
| Mission-critical | Core banking, payroll, e-invoicing | Minutes |
| Business-critical | ERP, CRM, analytics platforms | Hours |
| Business-operational | Internal tools, dev/test environments | Days |
Higher criticality means faster recovery targets, more frequent replication, and higher DR spend. Without this classification, organizations routinely over-provision DR for dev/test environments while leaving production ERP systems on cold standby.
DR Architecture Patterns
Microsoft documents three primary patterns for multi-region deployments:
- Active-passive cold standby — no pre-deployed resources in recovery region; lowest cost, highest RTO
- Active-passive warm standby — partial resources pre-deployed; faster failover, moderate cost
- Active-active — workloads run simultaneously across regions; lowest RTO, highest cost
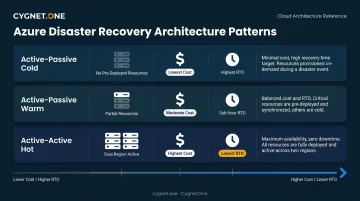
Warm standby is the most common choice for enterprise workloads. It delivers sub-hour recovery without the full cost of running duplicate infrastructure in a second region.
Core Azure Disaster Recovery Services
Azure Site Recovery (ASR)
ASR is Microsoft's primary Disaster Recovery as a Service (DRaaS) offering. It orchestrates and automates replication across:
- Azure VMs between regions
- On-premises VMware and Hyper-V VMs to Azure
- Physical servers to Azure
- Azure Stack Hub workloads
ASR recovery plans define failover sequencing — database tier first, then application tier, then web tier — with machines in the same group failing over in parallel. Plans can integrate Azure Automation runbooks to reduce manual steps during failover. ASR also supports test failovers that validate recovery without touching production data or causing downtime.
One important note: ASR failover is not automatic by default. It's initiated through the portal or PowerShell, though automation can be built using the SDK or REST API.
Azure Backup
Azure Backup is distinct from ASR. Where ASR handles infrastructure failover and replication, Azure Backup focuses on data protection and point-in-time restores. Supported workloads include:
- Azure VMs and Azure Files
- SQL Server and SAP HANA on Azure VMs
- AKS (cluster state and application data)
- Azure Blobs and Azure Data Lake Storage
The two services are complementary: ASR gets your infrastructure back online, while Azure Backup ensures you can restore to a clean data state.
Azure Traffic Manager
Traffic Manager performs DNS-based routing and monitors endpoint health. In a DR scenario, it redirects user traffic to the recovery region automatically when primary endpoints fail health probes. Two routing configurations are commonly used in DR setups:
- Priority routing: Primary endpoint serves normal traffic; failover endpoint activates when the primary fails health probes
- Nested profiles: Layered Traffic Manager configurations for enterprise environments that need more granular routing logic
Azure Monitor and Alerts
Azure Monitor alerts proactively notify teams when collected data indicates a problem. Dynamic thresholds use machine learning to detect anomalies against historical baselines, catching degradation before it becomes a full outage. Combined with health modeling (Healthy / Degraded / Unhealthy states), Monitor serves as the early warning system for meeting DR activation criteria before issues escalate.
Supporting Services
- Azure Virtual Network — network topology (VNets, subnets, routes, NSGs) must be replicated to the recovery region; ASR handles VNet mapping automatically during Azure-to-Azure replication
- Microsoft Entra ID — identity and access continuity; soft-deleted objects are retained for 30 days, but some objects delete immediately, making Entra recoverability planning important
- Azure VPN Gateway — encrypted connectivity between on-premises locations and Azure, maintaining secure hybrid access during failover
Azure Disaster Recovery Architectures: SMB to Enterprise
SMB Disaster Recovery Architecture
For organizations without dedicated infrastructure teams, a cost-effective Azure DR architecture uses:
- Azure Traffic Manager — DNS routing with health probes directing users to the recovery region
- Azure Site Recovery — orchestrating VM replication between regions
- Azure Virtual Network — recovery site network topology mirroring production
- Azure Blob Storage — storing replica images
This pattern requires no secondary physical site, handles failover reliably, and keeps standby costs low when using cold or warm standby configurations.
Enterprise-Scale Disaster Recovery Architecture
Enterprise environments extend the SMB model with additional layers:
- Microsoft Entra ID replication — ensuring identity services remain available post-failover
- VPN Gateway — maintaining secure on-premises-to-Azure connectivity during regional failover
- Multi-tier recovery sequencing — granular ASR recovery plans for complex application stacks (SAP, SharePoint farms, multi-tier web applications)
- Multiregion load balancing — Traffic Manager combined with Application Gateway for resilient multitier applications
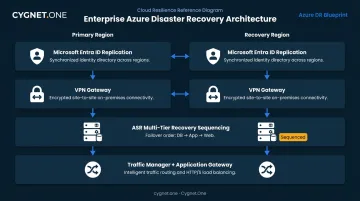
For SAP specifically, Microsoft recommends ASR replication for the web dispatcher and application server pool, with native database replication technology handling the database tier separately.
Selecting the Right Architecture
These two architecture patterns cover most scenarios, but the right choice depends on four factors specific to your environment:
| Factor | What to Evaluate |
|---|---|
| RTO/RPO targets | Cold standby suits a 24-hour RTO; warm standby targets hours; active-active targets minutes |
| Budget | Active-active can cost 2x or more compared to warm standby |
| Regulatory requirements | Data residency mandates in BFSI and regulated industries often constrain which Azure regions can be used for replication |
| Hybrid vs. cloud-native | On-premises dependencies require VPN Gateway and AD/DNS DR planning |
Validate your chosen architecture through actual test failovers — design assumptions alone won't reveal gaps in sequencing, DNS propagation timing, or credential replication.
How to Build an Azure Disaster Recovery Plan (Step-by-Step)
Step 1: Assess Business Impact and Define Recovery Objectives
Start with a complete inventory of applications and workloads. For each one:
- Identify the business owner — who declares an incident, who approves failover
- Classify by criticality tier — mission-critical, business-critical, or business-operational
- Define RTO and RPO — based on actual business tolerance, not technical defaults
- Quantify the cost of downtime — use this to justify DR investment
With 41% of large enterprises reporting hourly downtime costs between $1M–$5M, precise RTO and RPO targets aren't bureaucratic formality. Setting them loosely is a financial risk.
Step 2: Identify Risks and Define Disaster Activation Criteria
Map the specific failure scenarios your DR plan must handle:
- Azure regional outages
- Dependent service failures (DNS, identity, connectivity)
- Network outages or latency degradation
- Data corruption or accidental deletion
- Ransomware or cyberattack
Then define quantitative activation criteria — the specific thresholds that distinguish a minor incident from a declared disaster. Vague criteria like "significant outage" cause delay and confusion under pressure.
Specific criteria like "primary region health check failures exceed 5 minutes with confirmed data plane impact" enable decisive action. Embed these thresholds into Azure Monitor alerts and health models.
Step 3: Design Recovery Architecture and Configure Azure Services
Technical setup involves:
- Create a Recovery Services Vault in your target Azure region
- Enable VM replication via ASR, defining recovery groups and failover sequencing
- Configure Azure Backup policies with retention periods matched to RPO requirements
- Replicate network topology — VNets, subnets, NSGs, route tables — to the recovery region
- Configure Traffic Manager health probes pointed at both primary and failover endpoints
- Pre-deploy compute resources in warm standby environments so they're ready for workload activation

Document every configuration, script, and credential in a location that remains accessible during a regional outage — which means storing it outside the affected region, with offline or printed copies for worst-case scenarios.
Step 4: Define Communication Protocols and Assign Roles
DR plans fail as often on the human side as the technical side. Define clearly:
- Who declares a disaster — with explicit criteria, not judgment calls
- Who runs operations tasks — failover execution, monitoring, rollback decisions
- Who manages stakeholder communication — leadership, customers, regulators
- Who leads post-incident retrospectives — capturing lessons before memory fades
Create cross-functional war room channels in advance. Pre-build message templates for internal and external communication so teams aren't drafting under pressure. For enterprises in regulated industries — BFSI, healthcare, compliance-heavy sectors — documented role assignments are also an audit requirement, not just operational hygiene.
Step 5: Test, Document, and Iterate the Plan
Process preparation only delivers value when it's validated. Uptime Institute reports that 80% of serious outages are considered preventable through better management, process, or configuration — and regular testing is the mechanism that surfaces gaps before production does.
Three testing modes:
- Tabletop exercises — team practice, role familiarization, scenario walkthroughs; no systems involved
- Non-production dry runs — validate procedures safely without risking production workloads
- Production-level drills — the only true validation of RTO/RPO targets

Microsoft recommends quarterly test failovers per application using ASR's built-in test failover feature. Review and update the DR plan every six months, or after any significant architecture change.
Cygnet.One's managed infrastructure practice — which has delivered outcomes including 75% reductions in recovery time and sub-30-minute RPO across client environments — incorporates quarterly failover simulations as a standard element of DR engagement. For enterprises requiring both technical validation and compliance documentation (SOC 2 Type II, audit-ready DR records), their infrastructure team can support the full design, implementation, and testing lifecycle.
Azure Disaster Recovery Best Practices
Automate wherever possible. Use Azure Automation runbooks within ASR recovery plans to reduce manual steps and compress RTO. Scripts should be declarative, idempotent, and include retry logic. Pre-deploy CI/CD pipelines in recovery regions so they're operational post-failover. Automation still requires trained operators — false-positive triggers can cause unnecessary failovers with real business impact.
Plan for full regional failures. Azure availability zones protect against datacenter-level failures within a region, but not against region-wide outages. Critical applications must be distributed across regions with confirmed cross-region replication support for all services involved. Validate that your chosen Azure region pairs support the specific replication behaviors your workloads require — not all services support all region-pair configurations.
Keep the DR plan current and accessible. A DR plan that's 18 months out of date is a false sense of security. To keep it reliable:
- Store documentation, scripts, recovery credentials, and certificates in highly available locations replicated across regions
- Maintain offline copies as a fallback
- Review every six months with operations, technology leadership, and business stakeholders
- Update the plan whenever architecture changes or testing uncovers gaps
Frequently Asked Questions
Does Azure have a disaster recovery plan?
Azure provides native DR tools — primarily Azure Site Recovery and Azure Backup — that organisations use to build their own plans. The infrastructure and tooling are Azure's responsibility; designing, owning, and maintaining the DR plan is yours. Azure does not provide a pre-built, organisation-specific recovery plan.
How does Azure disaster recovery work?
VM configurations and data are continuously replicated to a secondary Azure region. When a disruption is declared, ASR orchestrates failover — switching traffic to the recovery region and restoring workloads from replicated data. Once the primary environment is stable, failback returns operations to the original region.
What is the difference between Azure Backup and Azure Site Recovery?
Azure Backup creates copies of data for point-in-time restores — it's about data protection. Azure Site Recovery handles infrastructure failover and replication, ensuring entire VMs and applications can be brought online in a recovery region. Most organisations use both together as complementary layers.
What are RTO and RPO, and why do they matter for Azure DR?
RTO is the maximum acceptable downtime; RPO is the maximum acceptable data loss measured in time. These metrics determine which Azure DR architecture, replication strategy, and tools are appropriate — and directly determine how much the solution costs to build and maintain.
How often should I test my Azure disaster recovery plan?
Microsoft recommends quarterly test failovers per application using ASR's built-in test failover feature. Pair that with tabletop exercises for team readiness and a full DR plan review every six months — or after any significant architecture change.
What is the cost of Azure disaster recovery?
Azure DR costs vary based on your chosen strategy (cold standby is the most affordable; active-active is the most expensive), data replication volume, and the regions involved. Use the Azure pricing calculator for current estimates, as figures change frequently by region and resource type.


