
Introduction
Hybrid IT infrastructure has become the operational standard for enterprises worldwide, combining on-premises systems, private clouds, and public cloud services into a single integrated environment. With adoption rates reaching 82% globally and Gartner forecasting this will climb to 90% by 2027, the question is no longer whether to adopt hybrid IT, but how to manage it effectively. Yet many organisations struggle with fragmented visibility, inconsistent security policies, and spiralling costs—challenges that directly threaten performance, security, and business continuity.
Poorly managed hybrid environments create tangible risks:
- Failed compliance audits exposing the organisation to regulatory penalties
- Unplanned downtime costing upwards of $300,000 per hour in lost revenue and recovery
- Excessive cloud spend from over-provisioning and ungoverned resource sprawl
- Security gaps that leave systems exposed for months without detection
For enterprises running compliance-critical workloads—such as e-invoicing platforms processing millions of transactions monthly or ERP systems handling financial reporting—these risks compound quickly. Without active governance and unified monitoring, even a well-architected environment degrades into a liability.
This guide covers why structured hybrid IT management matters, the four management approaches you should know, warning signs your environment is under stress, and a practical review cadence to keep your infrastructure reliable, secure, and cost-optimised.
Key Takeaways
- Hybrid IT combines on-premises and cloud resources, requiring a unified management strategy—not just disconnected tools
- Core challenges include fragmented visibility, inconsistent security policies, and managing performance across distributed environments
- Reactive, preventive, predictive, and strategic management approaches each suit different risk profiles and operational scenarios
- Warning signs include rising latency, recurring incidents, unexplained cost spikes, and unmanaged shadow IT
- Build a review cadence spanning daily health checks to annual architecture reviews to keep environments resilient and cost-efficient
Why Hybrid IT Infrastructure Management Matters
Hybrid IT management is not merely an operational concern—it's a strategic discipline that directly impacts performance, cost control, security posture, and competitive advantage. Organisations that treat it as optional or delegate it to reactive firefighting pay a steep price.
Performance and Business Continuity at Stake:
Siloed monitoring tools and inconsistent governance create blind spots that slow incident response and increase Mean Time to Resolution (MTTR). Over 90% of mid-size and large enterprises report that unplanned downtime costs exceed $300,000 per hour, with some high-impact outages reaching $2 million per hour. When visibility is fragmented across separate dashboards for cloud, on-premises, networking, and security, root cause analysis becomes guesswork—and outages last longer than they should.
Cost Inflation from Reactive Management:
Unmanaged hybrid environments inflate IT spend through over-provisioned cloud resources, redundant tooling, and reactive troubleshooting. Flexera's 2024 report estimates that 29% of cloud spend is wasted, driven by over-provisioning, idle resources, and lack of governance. Contrast this with organisations that implement proactive management and rightsizing: they achieve measurable cost reductions and extend the productive lifespan of their infrastructure.
Compliance and Regulatory Exposure:
For enterprises in banking, financial services, FMCG, and IT services, compliance-critical workloads — e-invoicing, ERP transactions, and financial reporting — must maintain strict SLAs. Tax transformation workflows spanning 250+ ERP integrations, for example, can only sustain 99% uptime when the underlying hybrid infrastructure is actively governed and monitored.
A single misconfiguration can trigger regulatory fines. 32% of global organisations were fined for data breach infractions in 2025 alone — a direct consequence of ungoverned infrastructure.
The Case for Proactive Investment:
Organisations that invest in structured hybrid IT management reduce operational risk, improve resource utilisation, and build the foundation for digital transformation at scale. The result is a measurable shift: fewer incidents, faster resolution, and infrastructure that supports growth rather than constraining it.
Types of Hybrid IT Management Approaches
Hybrid IT management isn't one-size-fits-all. The right approach depends on workload criticality, team capacity, budget, and risk tolerance. Most mature environments use a combination of the following four approaches.
Reactive / Corrective Management
Reactive management responds to failures after they occur—patching outages, restoring services, and troubleshooting incidents as they surface. This approach is unavoidable for unexpected hardware failures or zero-day vulnerabilities, but over-reliance on it is costly and risky.
Beyond immediate remediation expenses, reactive management creates cascading effects on SLAs, team burnout, and reputational damage. The Uptime Institute's 2024 survey found that 80% of serious outages could have been prevented with better maintenance practices.
When teams spend more time firefighting than improving, the organisation pays twice — once for the incident, and again for the opportunity cost of strategic work left undone.
Preventive / Scheduled Management
Preventive management involves scheduled, routine health checks and maintenance tasks performed regardless of whether issues are present. This includes firmware patching, configuration audits, certificate renewals, capacity reviews, and access policy reviews.
Preventive management is the baseline standard for mission-critical workloads. Typical tasks include:
- Weekly performance trend reviews
- Monthly patch cycles aligned with CISA's Known Exploited Vulnerabilities (KEV) catalog
- Quarterly security policy audits
- Annual disaster recovery testing
Preventive maintenance reduces incident frequency and MTTR. IBM's Cost of a Data Breach reports consistently show that preventive controls and preparedness reduce both incident frequency and time to recovery.
Predictive / Condition-Based Management
Predictive management uses real-time telemetry, monitoring tools, and AI/ML-driven analytics to anticipate problems before they surface. For example, detecting anomalous CPU usage trends that precede resource saturation, or flagging network latency spikes between cloud and on-premises environments.
This approach relies on unified observability platforms, AIOps tools, and log aggregation. Gartner reports that 54% of I&O leaders have adopted AIOps, driven by cost optimisation and the need to manage complexity.
The ROI case is clear: reduced alert fatigue, faster root cause analysis, and a shift from reactive to proactive operations. Forrester TEI studies show that unified observability platforms can reduce MTTR by up to 85% and deliver ROIs exceeding 200%.
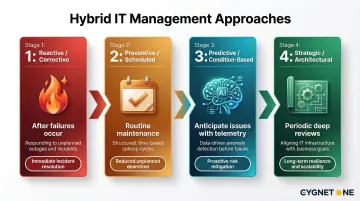
Strategic / Architectural Overhaul
Strategic overhaul involves periodic deep reviews of the hybrid IT architecture itself—assessing whether workload placement (on-premises vs. cloud) still aligns with cost, performance, and compliance goals, and whether the technology stack needs modernisation.
Common triggers for a strategic review include:
- Major business changes — M&A activity, new regulatory requirements, or significant growth
- End-of-life infrastructure approaching replacement cycles
- Persistent performance issues that preventive and predictive approaches cannot resolve
What was optimal at deployment may not be the right fit two or three years later. Scheduling architectural reviews every 12–18 months keeps the environment aligned with where the business is heading — not where it was.
Warning Signs Your Hybrid IT Infrastructure Needs Attention
Early and late indicators signal when a hybrid IT environment is under stress and requires immediate management intervention.
Performance Degradation and Latency Issues
Watch for these performance red flags in your hybrid environment:
- Increased application response times, especially under peak load
- Slower data transfers between cloud and on-premises systems
- Inconsistent throughput pointing to misconfigured networking or routing inefficiencies
- Under-provisioned resources causing bottlenecks at capacity limits
If workloads designed for the cloud are running on legacy on-premises hardware (or vice versa), the resulting performance mismatch is a clear signal that workload placement needs re-evaluation. For latency-sensitive workloads like synchronous database replication, even 5ms round-trip time (RTT) can degrade performance by 5-12%.
Security and Compliance Gaps
Security gaps in hybrid environments are rarely obvious until an audit fails or an incident occurs. Common warning signs include:
- Failed compliance audits or inconsistent access control policies across environments
- Unpatched systems left exposed due to fragmented patch management workflows
- Shadow IT — unauthorised cloud services adopted outside IT governance
Google Cloud's H2 2025 threat report found that misconfigurations accounted for 29.4% of observed cloud security incidents, while weak or absent credentials contributed to another 47.1%.

The risk compounds when sensitive workloads (financial data, customer PII) lack environment-specific security controls. A gap in one layer of a hybrid environment can expose the entire organisation. Netskope's 2025 report found that 60% of users utilise personal, unmanaged apps, creating a significant shadow IT footprint.
Escalating and Unexplained Costs
Unexplained cost increases are a reliable signal that cost governance has broken down. Key indicators:
- Unexpected cloud billing spikes with no corresponding workload increase
- Over-provisioned resources sitting idle across environments
- Multiple overlapping monitoring or management tools with duplicated licensing costs
- Manual processes that drain engineering time and should be automated
Cost overruns rarely result from a single event. They accumulate gradually from poor visibility into resource utilisation, making regular cost audits essential. Organisations waste an estimated 29% of cloud spend on over-provisioning and idle resources alone.
Recurring Incidents and Fragmented Visibility
When the same incidents resurface week after week, the problem is rarely technical — it's structural. Ticketing systems filled with repeat issues, short-lived fixes that fail within days, and teams spending more time troubleshooting than improving all point to a management gap that reactive fixes won't close.
Fragmented tooling drives this pattern. Separate dashboards for cloud, on-premises, networking, and security — with no unified view — force teams into "swivel-chair troubleshooting." Enterprises operating 4-8 separate monitoring tools find root cause analysis slow and often inconclusive, extending mean time to resolution well beyond acceptable thresholds.

Hybrid IT Infrastructure Management Best Practices and Review Cadence
Effective hybrid IT management requires both ongoing best practices and a structured review schedule. The cadence varies by workload criticality, scale, and operational model, but the framework below applies to most enterprise environments.
Management Review Frequency Table
| Frequency | Activities |
|---|---|
| Daily | Automated health checks, alert triage, uptime verification |
| Weekly | Performance trend review, patch status, incident post-mortems |
| Monthly | Cost optimisation review, access policy audit, capacity planning |
| Quarterly | Security posture assessment, workload placement review, SLA compliance check |
| Annual | Architectural review, vendor and contract evaluation, disaster recovery testing |

Three Non-Negotiable Best Practices
1. Enforce Unified Visibility
Invest in a unified monitoring platform that provides consistent visibility across both on-premises and cloud environments. Organisations with full-stack observability achieve 20% faster Mean Time to Detect (MTTD) for high-impact outages — 28 minutes vs. 35 minutes. Industry estimates also indicate this observability can reduce the median cost of outages from $2 million to $1 million per hour.
2. Automate Routine Management Tasks
Automate patching, certificate renewal, auto-scaling, and incident routing to reduce human error and free IT teams for strategic work. The Uptime Institute found that nearly 40% of major outages result from human error, with 85% stemming from failures to follow established procedures.
3. Apply Environment-Specific Security Controls Consistently
Do not assume that a cloud-native security policy translates directly to on-premises systems. Implement consistent security frameworks aligned with NIST CSF 2.0, ISO/IEC 27001, and industry-specific regulations. Research suggests misconfigurations account for roughly 21% of error-related security breaches — making policy consistency a direct risk management priority.
Workload Placement Governance
Regularly assess whether workloads are running in the environment best suited to their performance, compliance, and cost requirements. Over time, what was optimal at deployment may no longer be the right choice. Strategic reviews should evaluate:
- Cost-performance alignment
- Compliance and data residency requirements
- Latency and throughput needs
- Disaster recovery and business continuity requirements
Conclusion
Hybrid IT infrastructure management is not a one-time project but an ongoing discipline. Organisations that treat it as such gain measurable advantages in uptime, cost control, security posture, and operational agility.
Effective management rests on a few consistent pillars:
- Preventive routines that catch failures before they reach production
- Predictive intelligence that surfaces capacity and performance risks early
- Periodic strategic reviews that realign infrastructure spend with business priorities
- Unified visibility across on-premises and cloud environments to maintain control
With hybrid adoption rates approaching 90% globally, the competitive gap between organisations that manage their hybrid environments proactively and those that react to problems is widening. The discipline you build today directly determines the uptime, cost efficiency, and scalability your business can count on tomorrow.
Frequently Asked Questions
What is hybrid IT infrastructure?
Hybrid IT infrastructure combines on-premises hardware and data centres with public and/or private cloud services, enabling organisations to run different workloads in the environment best suited to their performance, compliance, and cost needs.
What is a common management challenge that results from complex hybrid IT environments?
Fragmented visibility is the most cited challenge—different environments report different metrics through different tools, making it difficult to get a unified view of performance, security, and cost across the entire infrastructure.
What is an example of a hybrid infrastructure?
A financial services company might run its core banking application on on-premises servers for regulatory compliance while hosting its customer-facing web application and analytics workloads on a public cloud like AWS or Azure.
How to optimise hybrid cloud infrastructure?
Four levers drive the most impact:
- Unified monitoring for end-to-end visibility
- Automated resource scaling to eliminate over-provisioning
- Regular workload placement reviews for cost-performance alignment
- Consistent security policy enforcement across all environments
What are the 5 pillars of cloud security?
The five pillars are identity and access management, data protection, infrastructure security, threat detection and response, and compliance and governance. Each must be enforced consistently across both on-premises and cloud layers.
What is the purpose of DCIM?
Data Centre Infrastructure Management (DCIM) software gives IT teams real-time visibility into physical assets, power consumption, cooling, and capacity. It is a foundational tool for managing the on-premises layer of any hybrid IT environment.


