
Introduction
Banks and credit unions face a relentless operational reality: systems must stay online, data must remain intact, and customer access cannot falter. Disaster recovery planning (DRP) is the structured process financial institutions use to restore critical systems, data, and operations following disruptive events—from cyberattacks and ransomware to hurricanes, floods, and power outages.
For financial institutions, DRP is non-negotiable. They hold sensitive customer data, process high-value transactions continuously, and face regulatory scrutiny from bodies like the FFIEC, OCC, FDIC, NCUA, RBI, and FCA—depending on where they operate. Even brief downtime triggers financial losses, regulatory penalties, and reputational damage.
The numbers make the stakes concrete: the average data breach now costs $6.08 million, and billion-dollar weather disasters have averaged 23 events annually from 2020–2024.
Most institutions have a DRP. Far fewer have one that functions under actual crisis conditions. This article breaks down what separates the two—and what it takes to build a plan your institution can rely on when it matters.
Key Takeaways
- DRP focuses on restoring IT systems and data after disruption — not just documenting procedures
- Complete plans cover asset inventory, BIA, RTO/RPO targets, and designated response teams
- FFIEC, OCC, FDIC, and NCUA all mandate formal disaster recovery capabilities for financial institutions
- Test regularly and update annually — that's what separates a working DRP from a compliance checkbox
What Is Disaster Recovery Planning for Banks and Credit Unions?
Disaster recovery planning in banking is a documented, tested set of procedures that enables a financial institution to restore its critical IT systems, infrastructure, and data to normal operations after a disruptive event. The FFIEC defines disaster recovery as "the restoring of IT infrastructure, data, and systems."
What the Process Achieves
A functional DRP delivers four core outcomes:
- Minimizes downtime for mission-critical systems like payment processing and digital banking
- Protects data integrity across customer accounts, transaction records, and regulatory filings
- Maintains regulatory compliance with FFIEC, OCC, FDIC, and NCUA requirements
- Restores member access to financial services as quickly as possible
These outcomes define what DRP must accomplish — but understanding where it fits within your institution's broader continuity framework matters just as much.
DRP vs. BCP vs. BCM
Banks frequently conflate these three terms. Each plays a different role:
| Term | Focus | Scope |
|---|---|---|
| DRP (Disaster Recovery Planning) | Restoring IT systems, servers, and databases after an incident | Technical — IT restoration |
| BCP (Business Continuity Planning) | Keeping branches, call centers, and business functions running during a disruption | Operational — service continuity |
| BCM (Business Continuity Management) | Overarching governance program encompassing DRP, BCP, risk assessment, and continuous improvement | Strategic — program-level |

In practice, DRP activates first — getting systems back online — while BCP governs how the institution operates in the interim. BCM is the program that ensures both are regularly tested, updated, and audit-ready.
Why Banks and Credit Unions Can't Afford to Skip a Disaster Recovery Plan
The Regulatory Imperative
Disaster recovery planning is effectively a legal requirement for financial institutions worldwide. Regulators across jurisdictions — from central banks to financial supervisory authorities — mandate that banks and NBFCs maintain tested, documented recovery capabilities.
In India, the RBI's IT Framework for Banks mandates robust IT service continuity management, requiring institutions to define recovery time objectives, conduct periodic DR drills, and maintain offsite data backups. Beyond India:
- RBI Master Directions require banks to document and test IT recovery plans annually
- CBUAE guidelines mandate business continuity frameworks for UAE-licensed financial institutions
- SAMA Cybersecurity Framework (Saudi Arabia) sets DR and resilience requirements for banks operating in the Kingdom
- UK FCA/PRA rules require firms to maintain adequate operational resilience, including recovery from disruptions
Enforcement actions demonstrate consequences for inadequate planning. Regulatory penalties for DR gaps are rising globally — supervisory reviews consistently cite missing DR tests, outdated recovery documentation, and unvalidated recovery time objectives as examination failures.
Compliance alone, however, is only part of the picture. The operational environment of modern banking makes recovery planning a business-critical priority in its own right.
What the Banking Environment Demands
Financial institutions operate under conditions that make disaster recovery uniquely critical:
- Customers expect account access around the clock — outages at any hour carry immediate reputational cost
- Fiduciary duty over deposits and payment processing leaves no margin for data loss or processing gaps
- Real-time payment systems, NEFT/RTGS transfers, and card networks demand near-zero downtime tolerance
- Cyberattack frequency and climate-related disruptions are both escalating across every region
The threat landscape has intensified. Cyberattacks targeting financial institutions continue to escalate in sophistication and cost. Meanwhile, climate-related disruptions have grown more frequent globally — the World Meteorological Organization reported that weather-related disasters caused over $2 trillion in economic losses between 2000 and 2019 alone, with financial services among the most exposed sectors.
What Goes Wrong Without a DRP
Institutions without functional disaster recovery plans face predictable failures:
- Prolonged outages trigger regulatory penalties, supervisory scrutiny, and formal examination findings
- Customers unable to access accounts migrate to competitors — loyalty erodes fast during crises
- Reputational damage from visible failures compounds long after systems are restored
- During disasters, financial institutions that can't operate fail the communities depending on them most
These aren't hypothetical risks. Enforcement actions consistently cite inadequate DR testing, outdated Business Impact Analyses, and failure to validate that recovery objectives can actually be met.
Core Components of an Effective Bank Disaster Recovery Plan
Operational Asset Inventory
The foundation of any DRP is a complete catalogue of every IT asset critical to operations:
- Hardware: Employee devices, servers, network equipment, ATMs
- Software: Core banking platforms, digital banking applications, payment processing systems
- Cloud-based applications: SaaS platforms, cloud storage, hosted services
- APIs and integrations: Connections between internal systems and third-party providers
Each asset should be classified by criticality:
- Mission-critical: Systems whose failure immediately halts core operations (payment processing, account access)
- Essential: Systems required within hours to maintain service levels
- Necessary: Systems needed within days to restore full functionality
- Non-essential: Systems that can be offline for extended periods without major impact
This classification is what determines which systems get restored first when an incident occurs — and feeds directly into the Business Impact Analysis.
Business Impact Analysis (BIA)
The BIA is the foundational process for identifying and prioritizing all business functions by criticality. It quantifies the financial, operational, and reputational cost of downtime for each critical system:
- Lost revenue from transaction processing delays
- Regulatory penalties for reporting failures
- Staff overtime and emergency response costs
- Hardware replacement and data recovery expenses
The BIA determines Maximum Tolerable Downtime (MTD) for each function—the absolute longest a system can remain offline before the institution suffers unacceptable damage. This analysis directly informs Recovery Time Objectives and recovery priorities.
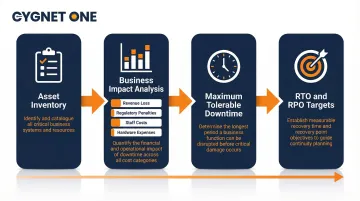
Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
RTO and RPO set the measurable targets that every other recovery decision flows from:
| Metric | Definition | Example |
|---|---|---|
| Recovery Time Objective (RTO) | Maximum acceptable downtime before a system must be restored | Payment processing: 2 hours; internal reporting: 24 hours |
| Recovery Point Objective (RPO) | Maximum acceptable data loss, measured in time | Mission-critical systems may require near-zero RPO through real-time replication |
Regulators do not mandate universal numeric benchmarks for all institutions. Each bank or credit union must establish RTO and RPO values based on its own BIA and risk profile. The Federal Reserve designs its Fedwire systems to resume operations within two hours of a disruptive event. That is an operational goal for the Fed's own infrastructure, not a requirement imposed on all participants.
Data Backup and Offsite Replication Strategy
Storing backups is not enough—institutions must prove they can actually restore from them. An effective backup strategy includes:
- Geographically distributed backup locations to protect against regional disasters
- Multiple copies stored in different formats (disk, tape, cloud)
- Regular restoration testing to validate backup integrity
Key questions every DRP must answer:
- Which data gets restored first?
- Where will systems be recovered (primary site, alternate site, cloud)?
- Where are backups physically located?
- Are there multiple recovery pathways if the primary method fails?
- How will remote branches recover independently?
Communication and Notification Protocols
The DRP must define how and when key stakeholders are notified:
- Recovery team members and their backups
- Senior leadership and board members
- Regulators (OCC, FDIC, NCUA as applicable)
- Core banking vendors and critical service providers
- Customers (when and how to communicate service disruptions)
Contact information must be current and accessible outside the affected systems. A secure alternate communication channel—not dependent on the institution's primary infrastructure—is essential.
Third-Party Vendor Risk Management
For third-party financial technology vendors, banks must verify their vendors' own DR posture. The 2023 Interagency Guidance on Third-Party Relationships requires institutions to assess vendor operational resilience, including:
- Vendor disaster recovery and business continuity plans
- Vendor RTO and RPO commitments that align with the institution's needs
- Frequency and nature of joint DR testing
- Timely data access rights during vendor outages
- Notification requirements for significant vendor changes
When evaluating technology vendors — including tax and finance platforms — institutions should verify independent compliance certifications and uptime commitments. Cygnet.One, for instance, holds SOC 2 Type II compliance and maintains 99% infrastructure uptime, credentials that directly address the operational resilience requirements regulators expect institutions to validate in their vendor assessments.
Designated Recovery Team Structure
The DRP must specify roles and responsibilities:
- Who activates the plan and under what conditions
- Who makes decisions during recovery operations
- Which IT and business unit representatives participate
- Who serves as backups for each critical role
Having too many people involved without defined roles hampers recovery. Having too few creates single points of failure. The team structure should balance broad expertise with clear accountability.
How to Build and Test Your Bank's Disaster Recovery Plan
Effective DRP development follows a function-based rather than incident-based approach. Instead of writing separate plans for floods, cyberattacks, and power outages, focus on what happens if the institution loses a critical system or capability—regardless of cause. This design principle broadens the plan's applicability across threat types.
Step 1: Conduct a Risk Assessment and Asset Inventory
Begin by identifying all IT systems, physical infrastructure, and third-party dependencies:
- Catalogue every hardware component, software application, and cloud service
- Rank assets by criticality using the mission-critical/essential/necessary/non-essential framework
- Map which business functions depend on which systems
- Identify gaps in current backup or redundancy arrangements
This inventory feeds directly into the Business Impact Analysis, where each asset gets assigned measurable recovery targets.
Step 2: Perform a Business Impact Analysis and Set Recovery Objectives
Use the BIA to assign MTD, RTO, and RPO values to each critical system. These values become measurable targets the DRP must achieve. Without them, recovery efforts have no benchmark for success.
For each critical system, document:
- Financial impact of downtime per hour
- Operational impact on customer service
- Regulatory reporting obligations
- Reputational risk factors
With these figures in hand, the case for investing in backup infrastructure and redundancy becomes straightforward to make—and to defend to regulators.
Step 3: Document the Plan and Establish Activation Protocols
The DRP document should include:
- Activation trigger criteria: What conditions justify declaring a disaster and activating the plan
- Step-by-step recovery procedures for each system, including technical commands and configuration details
- Notification trees: Who contacts whom, in what order, using what methods
- Vendor escalation contacts: Direct lines to critical service providers
- Workspace contingencies: Where staff will work if the primary facility is inaccessible
Documentation should be detailed enough that someone unfamiliar with the systems can follow the procedures.
Step 4: Test the Plan Regularly Through Tabletop Exercises and Simulations
Regulators expect periodic testing whose frequency is determined by the institution's risk profile. Three primary testing formats apply:
- Tabletop exercises: Walk response teams through hypothetical scenarios to identify gaps in planning, decision-making, and communication. Low-cost and effective for surfacing coordination weaknesses.
- Parallel tests: Run backup systems alongside production systems to validate failover mechanisms without disrupting live operations.
- Full-scale simulations: Recover failed systems under controlled conditions, the most thorough way to catch technical issues before a real event.

Annual testing is a regulatory expectation. Staff familiarity with the plan is one of the strongest predictors of fast recovery when an actual disaster occurs.
Step 5: Review, Update, and Audit the Plan Continuously
The DRP requires continuous updates whenever significant changes occur:
- New technology implementations or system upgrades
- Personnel changes affecting recovery team composition
- Regulatory guidance updates from FFIEC, OCC, FDIC, or NCUA
- Changes in the institution's risk profile or threat landscape
Many institutions build annual DRP review cycles tied to their broader risk management calendar. Reviews should include:
- Verification that contact information is current
- Confirmation that backup locations remain viable
- Assessment of whether RTO/RPO targets still align with business needs
- Validation that vendor relationships and contracts remain appropriate
Common DRP Mistakes Banks and Credit Unions Make
Treating DRP as Incident-Based Rather Than Function-Based
The most common misconception is writing separate plans for specific disaster types—"what to do in a flood" versus "what to do in a cyberattack." This creates gaps for unexpected scenarios.
Instead, organize the DRP around the loss of functions: payment processing, account access, regulatory reporting. A function-based framework applies regardless of whether the cause is weather, cyber, hardware failure, or human error.
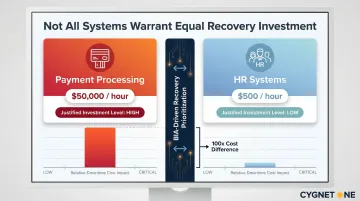
Setting Arbitrary RTO and RPO Targets
Many institutions set recovery objectives without anchoring them to a BIA. This produces arbitrary targets rather than objectives based on actual financial impact modeling.
For example, declaring that all systems must recover within four hours sounds reasonable. But if the BIA shows that payment processing downtime costs $50,000 per hour while HR systems cost $500 per hour, those systems justify entirely different recovery investments.
Storing Backups Without Testing Restoration
Institutions often store backup data without ever testing whether it can actually be restored. This creates a false sense of security. Backup files can become corrupted, procedures can fail silently, and restoration can take far longer than expected.
Regular restoration testing — not just backup verification — is the only way to confirm the DRP will work when it matters.
Confusing DRP Completeness with DRP Readiness
Having a documented DRP does not mean the institution is ready to execute it. Common readiness gaps include:
- Plans that have never been tested
- Teams that have never trained on recovery procedures
- Contact lists that are months or years out of date
- Vendor relationships that haven't been validated
These gaps have real consequences during examinations. Regulators increasingly look for evidence of testing and readiness, not just documentation — and findings frequently cite inadequate testing frequency or failure to update plans after significant operational changes.
Frequently Asked Questions
What is a recovery plan for a bank?
A bank recovery plan is a documented set of procedures enabling the institution to restore critical IT systems, data, and operations after a disruptive event. It covers data backup protocols, response team responsibilities, system restoration procedures, and regulatory notification requirements.
What is included in a disaster recovery plan?
A complete DRP typically includes:
- Asset inventory with criticality rankings
- Business Impact Analysis (BIA)
- Defined RTO and RPO targets
- Data backup and replication strategies
- Designated response team with clear roles
- Activation, notification, and testing schedules
What's the difference between DRP and BCP?
DRP focuses on restoring IT systems and data after an incident, while BCP focuses on maintaining business operations during the disruption. DRP is about getting systems back online; BCP is about keeping the institution functioning while that recovery happens.
Is a disaster recovery plan a legal requirement?
For banks and credit unions, DR planning is effectively a regulatory requirement. The FFIEC IT Examination Handbook mandates it, and the OCC, FDIC, and NCUA all issue guidance requiring financial institutions to maintain documented and tested disaster recovery capabilities.
What is BCM in banking?
Business Continuity Management (BCM) is the overarching program that governs both business continuity planning and disaster recovery. It encompasses risk assessment, impact analysis, plan development, testing, and continuous improvement across all disruption scenarios.
What are some examples of disaster recovery scenarios?
The most common scenarios financial institutions plan for include:
- Ransomware or cyberattacks locking access to core banking systems
- Natural disasters (floods, wildfires, hurricanes) destroying physical infrastructure
- Extended power outages affecting branches and data centers
- Vendor or third-party system failures
- Pandemic-related disruptions cutting off access to facilities


