
Introduction
Cloud disaster recovery (cloud DR) encompasses the strategies and technologies enterprises use to restore cloud-hosted applications, data, and infrastructure after disruptive events — from cyberattacks and hardware failures to regional outages. As organizations increasingly migrate mission-critical workloads such as financial transactions, compliance systems, and ERP platforms to the cloud, recovery speed and data integrity have become non-negotiable business requirements.
According to the Uptime Institute's 2023 survey data, 55% of data centre and IT operator respondents reported experiencing an outage within the past three years.
The financial consequences are severe. The ITIC 2024 Hourly Cost of Downtime Survey found that for over 90% of mid-size and large enterprises, a single hour of downtime now exceeds $300,000 — with 41% reporting costs between $1 million and $5 million per hour.
Those numbers make DR strategy selection a financial and operational priority — not just an IT checkbox. This article covers what cloud DR is, why it matters for enterprise applications, the four established DR strategy types, and how to choose the right one based on your business needs and risk tolerance.
Key Takeaways
- Cloud DR replicates and recovers enterprise applications via cloud infrastructure — eliminating dependence on secondary physical data centres
- Essential for protecting business continuity, meeting regulatory requirements, and minimising financial losses from downtime
- Four main strategies — Backup and Restore, Pilot Light, Warm Standby, and Multi-Site Active/Active — differ in cost, complexity, and recovery speed
- The right strategy depends on your RTO, RPO, application criticality, and budget
- Testing and automation matter just as much as choosing the right strategy
What Is Cloud Disaster Recovery for Enterprise Applications?
Cloud DR uses cloud platforms to replicate, back up, and recover enterprise IT systems — applications, databases, and configurations — when failures or disasters occur, without relying on a secondary on-premises data centre.
Traditional DR requires significant capital investment in dedicated secondary infrastructure — servers, networking, and physical facilities. Cloud DR replaces that with elastic, on-demand resources:
| Traditional DR | Cloud DR | |
|---|---|---|
| Upfront Cost | High (dedicated hardware) | Low (pay-as-you-go) |
| Provisioning Speed | Days to weeks | Minutes to hours |
| Scalability | Fixed capacity | On-demand elasticity |
| Maintenance | In-house team required | Managed by cloud provider |

This shift matters most for enterprises running large, distributed application estates across multiple regions.
The Two Metrics That Drive Every DR Decision
Every cloud DR strategy is governed by two parameters defined by NIST SP 800-34 Revision 1:
- Recovery Time Objective (RTO): The maximum acceptable downtime before unacceptable impact occurs
- Recovery Point Objective (RPO): The maximum acceptable data loss window, measured by the time since the most recent backup
Together, RTO and RPO set the boundaries for your DR architecture — a tighter RTO demands active replication, while a looser RPO may allow daily backups. Getting these numbers wrong means either overspending on unnecessary resilience or accepting risks your business cannot afford.
Why Cloud DR Matters for Enterprise Applications
Operational Consequences Without DR
Enterprises without tested DR plans face prolonged downtime affecting customer-facing services, supply chains, and financial transactions. Regulatory penalties for failing to meet data availability obligations compound the damage, alongside reputational harm from extended outages.
Cloud-hosted enterprise applications carry additional complexity — interdependent microservices, multi-region deployments, and real-time data replication needs — making recovery harder without a deliberate strategy. Cloud-hosted enterprise applications carry additional complexity — interdependent microservices, multi-region deployments, and real-time data replication needs — making recovery harder without a deliberate strategy. That operational exposure is also, increasingly, a compliance liability.
The Compliance Dimension
Enterprises in regulated sectors (BFSI, fintech, manufacturing) are frequently required by law or industry standards to have documented and tested DR procedures. Key frameworks include:
- SOC 2 availability criteria require documented and tested recovery procedures
- GDPR Article 32 mandates the ability to restore data availability within a defined timeframe
- PCI-DSS v4.0 requires annual testing of incident response and recovery plans
- DORA (EU) imposes comprehensive ICT business continuity obligations on financial entities
Meeting these obligations is not optional — regulators in the EU, UK, and India have each demonstrated willingness to enforce penalties where continuity planning is absent or untested.
The Cost of Inaction
Research shows that four in five operators believe their most recent significant downtime incidents were preventable with better management, processes, or configuration. For enterprises, that pattern points to one consistent conclusion: most costly outages are an operational choice, not an unavoidable risk.
The 4 Cloud Disaster Recovery Strategies for Enterprise Applications
These four strategies form a spectrum — from lowest cost with the longest recovery time, to highest cost with near-zero recovery time. No single strategy is universally correct. The right choice depends on your RTO/RPO requirements, budget, and tolerance for operational complexity.
Backup and Restore
Backup and Restore periodically copies data and application configurations to cloud storage (object storage or managed backup services), then rebuilds the full environment from scratch when disaster strikes. It maintains no live standby environment — infrastructure is redeployed at failover time, typically using Infrastructure as Code (IaC) tools like AWS CloudFormation or Terraform.
This is the only approach with no pre-provisioned compute in the recovery region, giving it the lowest ongoing cost but the highest RTO and RPO.
Best suited for:
- Non-critical or administrative workloads where hours of downtime are tolerable
- Enterprises with limited DR budgets
- Organizations beginning their DR maturity journey
- Baseline layer even when higher-tier strategies cover critical systems
Strengths:
- Lowest cost and simplest to implement
- Suitable for archival workloads and regulatory data retention
- IaC pairing enables consistent infrastructure redeployment
Limitations:
- Highest RTO — recovery can take hours
- Highest RPO — data loss extends to the last backup window
- Not suitable for mission-critical applications with tight availability SLAs
- Manual restoration steps increase human error risk under pressure
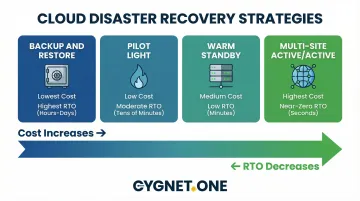
Pilot Light
In Pilot Light, the core data layer — databases, object storage — is continuously replicated to a recovery region and kept live at all times. Application servers and secondary infrastructure are pre-configured but not running. When disaster strikes, the dormant application layer is powered on and scaled up around the always-on data core.
Unlike Backup and Restore, data is always current. Unlike Warm Standby, application servers are not running — they must be started or deployed during failover, creating a brief lag.
Best suited for:
- Business-critical applications tolerating short recovery windows (tens of minutes to an hour)
- Mid-market enterprise and SaaS workloads where databases are the highest-value assets
- Organizations that cannot justify running a full second live environment
Strengths:
- Significantly reduces RPO through continuous data replication
- Keeps ongoing DR costs low by not running full compute in the recovery region
- Faster recovery path than pure backup approaches
Limitations:
- Failover is not instant — application infrastructure must be provisioned during the event
- Requires consistent IaC automation and tested runbooks
- May depend on cloud control plane operations during high-pressure recovery scenarios
Warm Standby
Warm Standby maintains a scaled-down but fully functional replica of the production environment in a secondary region. All services are deployed and running — just at reduced capacity. During a disaster, traffic is redirected to the standby environment, which then scales up to handle full production load.
The key differentiator from Pilot Light: application servers are already running and can accept traffic immediately. No deployment or startup time is needed. Think of it as "always on, not always at full scale."
Best suited for:
- Business-critical enterprise applications — e-commerce, ERP, financial systems
- Workloads requiring near-continuous availability
- Organizations where even minutes of downtime have measurable financial impact
- Enterprises that want confidence from continuous DR testing
Strengths:
- Faster RTO than Pilot Light — no infrastructure spin-up required
- Enables ongoing DR testing against a live (if reduced) environment
- Traffic routing can be automated, minimizing human intervention
Limitations:
- Higher ongoing cost because compute resources run continuously
- Scaling to full capacity may depend on Auto Scaling, a control plane operation
- Requires careful capacity planning for the standby environment
Multi-Site Active/Active
Multi-Site Active/Active runs the full production workload simultaneously across two or more cloud regions, with live traffic distributed across all of them. There is no "secondary" region — all regions serve users at all times. If one region fails, the others absorb its traffic without a conventional failover step.
This is the only strategy with no failover step. Losing one region results in automatic traffic redistribution, achieving near-zero RTO for infrastructure failures. The trade-off is architectural complexity: concurrent writes across regions require sophisticated data consistency and conflict resolution design.
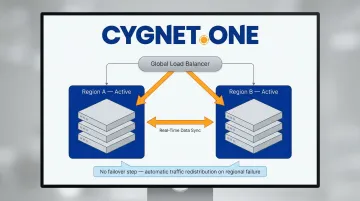
Best suited for:
- Strictest availability requirements — financial trading platforms, payment gateways, global SaaS
- Workloads where seconds of downtime create unacceptable consequences
- Organizations with mature cloud operations teams and significant investment capacity
Strengths:
- Near-zero RTO for regional infrastructure failures
- Supports global performance optimization by routing users to the nearest active region
- Eliminates single points of failure across the entire production stack
Limitations:
- Most expensive and operationally complex strategy
- Requires multi-region data replication and conflict resolution for concurrent writes
- Data disasters — corruption, accidental deletion — still require point-in-time recovery with non-zero RPO
- Not appropriate for most enterprise workloads; typically reserved for tier-1 mission-critical systems
How to Choose the Right Cloud DR Strategy for Enterprise Applications
The right strategy is not determined by what is technically impressive or what peers use — it is determined by matching RTO/RPO requirements and application criticality to cost and complexity tolerance.
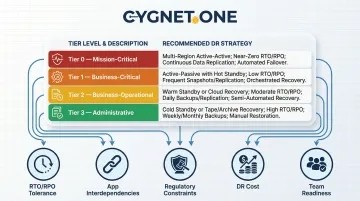
Start by classifying all applications into criticality tiers. This tiering directly dictates which DR strategy is viable — and which is overkill or insufficient:
- Mission-critical (Tier 0): Revenue-generating, customer-facing systems
- Business-critical (Tier 1): Essential operations, compliance systems
- Business-operational (Tier 2): Supporting functions
- Administrative (Tier 3): Internal tools, reporting
With tiers defined, five factors drive the final strategy decision:
- RTO/RPO tolerance: Sub-minute recovery windows point to Warm Standby or Active/Active. Hours of tolerance opens the door to Backup and Restore or Pilot Light.
- Application interdependencies: Tightly coupled stacks require a defined recovery sequence — failing over one component without its dependencies leaves the entire application non-functional.
- Regulatory constraints: BFSI and healthcare enterprises often face mandated recovery objectives and data residency rules that limit which cloud regions and architectures are permissible.
- Total DR cost: Active/Active carries the highest ongoing cost; Backup and Restore the lowest. Model cost across all tiers rather than forcing a single strategy on every application.
- Team readiness: Warm Standby and Active/Active demand cloud architecture depth, runbook automation, and regular failover testing. Validate your team's execution capacity before committing — a strategy only works if it can be run under real pressure.
Common Mistakes Enterprises Make When Finalising a Cloud DR Strategy
Choosing Strategy Based on Prestige Rather Than Fit
Many enterprises default to Active/Active because it sounds robust, when their RTO/RPO requirements and budget would be well served by Warm Standby or even Pilot Light. Overspending on DR for non-critical workloads diverts budget from systems that need it.
Skipping or Underinvesting in DR Testing
A DR plan that has never been tested is not a DR plan — it is a hypothesis. Research shows that 80% of operators believe their most recent outages were preventable with better processes. DR tests should be scheduled as regular operational events, not reactive drills.
Ignoring Application Interdependencies in Recovery Sequencing
Enterprise applications rarely fail in isolation. Recovering a database without the authentication service or API layer it depends on results in a non-functional environment. DR runbooks must map and enforce correct recovery order across all dependent components.
Treating Cloud DR as a One-Time Project
Enterprise applications, cloud architectures, and compliance requirements evolve continuously. A DR strategy designed for last year's environment may be inadequate for today's. Schedule formal reviews after major events — cloud region migrations, ERP version upgrades, new compliance mandates, or significant architectural changes.
Conclusion
Cloud disaster recovery is not a binary choice but a spectrum of strategies, ranging from simple Backup and Restore to fully redundant Multi-Site Active/Active deployments. Each approach suits a different combination of application criticality, budget, and operational maturity. The right strategy is the one that reliably meets RTO/RPO targets for each application tier at a cost the business can sustain.
Choosing the right strategy is only part of the equation. Converting a DR plan on paper into a capability that performs under real conditions requires:
- Consistent testing — scheduled failover drills that validate actual recovery times
- Runbook automation — scripted, repeatable recovery steps that reduce human error under pressure
- Cross-team alignment — shared ownership between infrastructure, application, and compliance teams
Enterprises running compliance-critical workloads on SOC 1-certified infrastructure, such as Cygnet.One's platform, should treat cloud DR as a built-in architecture decision rather than a retrofitted afterthought.
Frequently Asked Questions
What is the difference between RTO and RPO in disaster recovery for cloud-hosted enterprise applications?
RTO (Recovery Time Objective) is the maximum acceptable downtime after a disaster; RPO (Recovery Point Objective) is the maximum acceptable data loss measured in time. Both metrics directly determine which DR strategy an enterprise should adopt — lower RTO/RPO requirements point to higher-tier approaches like Warm Standby or Active/Active.
What are the main steps and frameworks of disaster recovery for cloud-hosted enterprise applications?
The five core steps are Risk Assessment, Business Impact Analysis, DR Planning, Implementation, and Testing and Maintenance. Cloud providers like AWS and Google Cloud offer prescriptive frameworks and native tooling aligned to each step.
What is the difference between pilot light and warm standby cloud DR strategies?
In Pilot Light, only the core data layer runs in the recovery region while application servers are off and must be started during failover. In Warm Standby, a scaled-down but fully functional environment is always running — traffic can be routed immediately, with only a scale-up needed rather than a cold start.
How often should enterprises test their cloud disaster recovery plan?
Best practice is to conduct DR tests at least annually for all application tiers, with quarterly tests for mission-critical systems or after major infrastructure changes. Automated runbooks and tabletop exercises supplement full failover drills, maintaining readiness without disrupting production.
What is Disaster Recovery as a Service (DRaaS) and when should enterprises consider it?
DRaaS is a cloud-based service where a third-party provider hosts, manages, and orchestrates the DR environment and failover on behalf of the enterprise. It suits organizations that lack the internal expertise or capacity to self-operate a Pilot Light or Warm Standby setup.
How does cloud disaster recovery support regulatory compliance for enterprises?
Frameworks such as SOC, GDPR, and PCI-DSS require documented, tested DR procedures and the ability to recover systems within defined timeframes. Cloud DR supports this through geo-redundant storage, encryption, audit logging, and documented RTO/RPO targets — each of which auditors routinely assess.


