
Introduction
Enterprises globally are shifting how they view AI models—no longer just research assets but operational tools powering fraud detection, credit scoring, invoice automation, and customer intelligence. According to Grand View Research, the AI deployment and MLOps market is projected to grow at a compound annual growth rate of approximately 40% through 2030, reflecting this operational imperative.
Most enterprises struggle not with building models, but with getting them reliably into production. Choosing the wrong deployment platform leads to latency failures, cost overruns, and compliance gaps.
For organizations in regulated sectors like banking, finance, and insurance — where model outputs impact credit risk decisions and regulatory reporting — platform selection is a strategic decision, not just a technical one.
This guide covers the top AI model deployment platforms in 2026, what sets each apart, and how to evaluate them against your organization's infrastructure, compliance requirements, and team capabilities.
Key Takeaways
- AI model deployment platforms handle the full lifecycle from trained model to production API—including scaling, monitoring, and governance
- Cloud-native platforms (AWS SageMaker, Google Vertex AI, Azure ML) are strongest for enterprises embedded in those ecosystems
- Developer-first options (Hugging Face Inference Endpoints, Databricks Mosaic AI) offer faster time-to-production for specialized teams
- Key evaluation criteria: scalability, pricing transparency, framework compatibility, security certifications, and MLOps depth
- Platform fit depends on team skill set, model type, infrastructure preferences, and compliance requirements — not feature count
What Are AI Model Deployment Platforms?
AI model deployment platforms are managed or self-hosted services that take a trained ML or AI model and make it available for real-world inference. They handle API creation, compute provisioning, versioning, and traffic management, so engineering teams don't have to build that infrastructure themselves.
Deployment vs. Serving: Understanding the Difference
Model serving is the runtime component that handles inference requests—taking input, running it through the model, and returning output. Model deployment is the broader lifecycle process that includes packaging, infrastructure setup, governance, monitoring, and integration with downstream systems. Serving sits inside deployment, not alongside it.
Three Platform Categories
The 2026 landscape spans three distinct categories:
- Fully managed cloud-native platforms: Integrated with major cloud ecosystems (AWS, GCP, Azure), offering fastest time-to-value and out-of-box compliance
- Serverless/developer-first platforms: Abstracted infrastructure for rapid iteration, often with scale-to-zero capabilities to eliminate idle costs
- Kubernetes-native self-hosted frameworks: Maximum control and data sovereignty for teams with strong infrastructure skills, at the cost of higher operational complexity

Teams with strong DevOps capabilities and strict data residency requirements tend toward self-hosted options; those prioritizing speed and simplicity lean cloud-native or serverless.
Top AI Model Deployment Platforms & Services in 2026
Each platform below was evaluated on enterprise scalability, pricing transparency, supported frameworks, security certifications, MLOps tooling depth, and support quality. The goal: identify services that reliably move models from prototype to production, not just in theory.
Amazon SageMaker (AWS)
SageMaker is AWS's end-to-end managed ML platform, covering data preparation through model deployment. As the cloud market leader with 29% market share (Synergy Research Group, Q3 2025), it's the most widely adopted enterprise AI deployment service due to AWS's dominant position and deep service integration.
Key differentiators:
- Native integration with AWS security stack (IAM, VPC, CloudWatch)
- Four inference modes: real-time, serverless, asynchronous, and batch transform
- SageMaker Pipelines for CI/CD orchestration
- Built-in Model Monitor for drift detection
- FedRAMP Moderate and High authorization for government workloads
| Aspect | Details |
|---|---|
| Key Features | Real-time, serverless, asynchronous, and batch inference endpoints; SageMaker Pipelines; Model Monitor for drift detection; AutoML; integration with S3, CloudWatch, and IAM |
| Pricing Model | Pay-as-you-go based on compute instance type, storage, and data transfer; real-time endpoints incur costs even when idle—requires careful capacity planning; serverless inference bills only for active processing |
| Best For | Enterprises deeply embedded in the AWS ecosystem needing enterprise-grade security, compliance (SOC 2, HIPAA, FedRAMP), and global availability |
Adoption evidence: Itaú, Latin America's largest bank, uses SageMaker to improve speed to market for ML models. GE HealthCare announced in July 2024 it will use SageMaker to deploy clinical foundation models.
Google Cloud Vertex AI
For teams moving from SageMaker's AWS-native approach, Vertex AI offers Google Cloud's equivalent: a unified platform consolidating model training, deployment, and MLOps tooling under a single API. Built for teams already running on GCP services like BigQuery and Google Cloud Storage, it keeps data and models in the same ecosystem.
Key differentiators:
- Direct BigQuery integration for data-heavy workloads
- Centralized Feature Store for sharing ML features across teams
- Built-in Vertex AI Pipelines for automated CI/CD
- Vector Search for high-performance similarity search
- AutoML for teams needing minimal-code model training
| Aspect | Details |
|---|---|
| Key Features | Online and batch prediction endpoints with autoscaling; Model Registry; Feature Store; Vector Search; Vertex AI Pipelines; AutoML capabilities |
| Pricing Model | Granular node-hour billing; online prediction endpoints do not scale to zero and incur continuous costs even when idle; pricing complexity increases when using legacy AI Platform features alongside Vertex AI |
| Best For | Data engineering teams and organizations with GCP-heavy infrastructure, particularly those using BigQuery as their primary data warehouse |
Critical cost consideration: Unlike its predecessor, Vertex AI's online prediction endpoints do not support scale-to-zero, meaning idle provisioned resources incur continuous costs.
Microsoft Azure Machine Learning
Azure ML is Microsoft's enterprise-grade ML platform built for organizations standardized on the Microsoft stack. It offers transparent compute-based billing and native integration with Azure DevOps and GitHub Actions for CI/CD—a practical fit for teams already managing infrastructure through Microsoft tooling.
Key differentiators:
- Managed online and batch endpoints with autoscaling
- Prompt Flow tool for LLM-based application development
- Hybrid deployment support spanning on-premises and cloud environments
- Extensive global region footprint for data residency requirements
- Compliance alignment with Microsoft's enterprise governance frameworks
| Aspect | Details |
|---|---|
| Key Features | Managed online and batch endpoints; Prompt Flow for LLM apps; AutoML; Azure DevOps and GitHub Actions integration; built-in model registry and dataset versioning |
| Pricing Model | Billed directly for underlying Azure compute (VMs/Kubernetes), storage, and networking—transparent but requires estimating costs across multiple services; batch endpoints scale to zero to avoid idle costs |
| Best For | Microsoft-centric enterprises needing stringent governance, DevOps-aligned ML workflows, and hybrid cloud or on-premise deployment options |
Databricks Mosaic AI Model Serving
Databricks Mosaic AI Model Serving is the deployment layer within the Databricks Lakehouse Platform. Teams whose data and model assets already live there get direct access to governed data without building separate pipelines—a meaningful efficiency gain for Lakehouse-native workflows.
Key differentiators:
- Serverless autoscaling including scale-to-zero to eliminate idle costs
- Unified interface for both custom models and open-source LLMs
- Unity Catalog governance integration for end-to-end data lineage
- AI Playground for rapid LLM testing and comparison without separate endpoint setup
- Foundation Model APIs and AI Gateway for managing external LLMs
| Aspect | Details |
|---|---|
| Key Features | Serverless real-time inference with scale-to-zero; Unity Catalog governance; Foundation Model APIs; AI Gateway for managing external LLMs; AI Playground; MLflow-native model registry |
| Pricing Model | Databricks Units (DBUs) per hour for compute; per-token pricing for foundation models—requires a DBU-to-dollar translation step for cost modeling |
| Best For | Data engineering and ML teams already operating within the Databricks Lakehouse ecosystem who need integrated governance and data lineage alongside model serving |
Hugging Face Inference Endpoints
Hugging Face Inference Endpoints offers the shortest path from a Hub model to a production REST API. The managed, autoscaling service deploys across AWS, Azure, and GCP with minimal configuration—useful for teams that want infrastructure handled without locking into a single cloud.
Key differentiators:
- One-click deployment for any public or private Hub model
- Built-in scale-to-zero to eliminate idle costs
- Transparent per-instance-hour pricing (calculated by the minute)
- Multi-cloud support (AWS, Azure, GCP)
- Enterprise-tier options with private networking (VPC peering), SOC 2, and HIPAA compliance
| Aspect | Details |
|---|---|
| Key Features | One-click Hub model deployment; autoscaling with scale-to-zero; multi-cloud support (AWS, Azure, GCP); built-in observability; private networking for enterprise tiers; AWS PrivateLink support |
| Pricing Model | Straightforward per-instance-hour billing calculated by the minute; scale-to-zero minimizes idle costs; costs completely eliminated when endpoints are paused |
| Best For | ML teams building with open-source transformer models who need a fast, low-friction path to production without deep infrastructure management |
Capital Fund Management (CFM), a quantitative asset manager, uses Hugging Face Inference Endpoints to securely deploy a Llama-3.1-70B model in production for financial data analysis (December 2024).
How We Chose the Best AI Model Deployment Platforms
Each platform on this list was evaluated across three core dimensions:
- Scalability: autoscaling behavior, scale-to-zero support, and throughput ceiling under load
- Framework compatibility: support for PyTorch, TensorFlow, scikit-learn, and large language model serving
- Security credentials: SOC 2 certification, GDPR compliance posture, and data residency controls
A common mistake is selecting a platform based on feature lists alone — without verifying compliance certifications or modeling total cost of ownership against realistic traffic patterns.
Business-Outcome Factors
The following factors determine how reliably AI can be operationalized at enterprise scale:
- Connects cleanly with existing data pipelines, reducing integration overhead
- Publishes predictable pricing that accounts for idle compute and per-service charges
- Provides mature MLOps tooling: model monitoring, versioning, CI/CD pipelines, and drift detection
The Open-Source vs. Managed Trade-Off
Managed platforms (SageMaker, Vertex AI, Azure ML) offer faster deployment timelines and built-in compliance features but risk vendor lock-in. Open-source/Kubernetes-native options (Seldon Core, KServe) give maximum control and data sovereignty, but carry greater operational complexity. Teams must manage the Kubernetes cluster, service mesh, autoscaling stack, and GPU scheduling themselves.
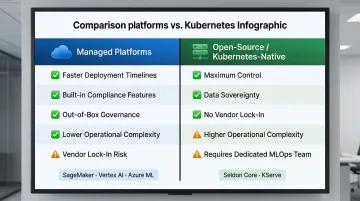
The right choice turns on two variables: team maturity and regulatory exposure. For high-risk AI applications under frameworks like the EU AI Act (2024) — credit scoring and insurance underwriting chief among them — self-hosted deployments may be the only viable path to meeting requirements for tamper-evident audit trails, model provenance, and data residency.
Frequently Asked Questions
What is an AI model deployment platform?
An AI model deployment platform is a managed or self-hosted service that takes a trained ML model and makes it available for real-world inference. It handles API creation, compute provisioning, autoscaling, monitoring, and governance so engineering teams don't need to build this infrastructure from scratch.
What is the difference between model deployment and model serving?
Model serving is the runtime component that handles inference requests: it takes input, runs it through the model, and returns output. Model deployment is the broader lifecycle, covering packaging, infrastructure setup, governance, monitoring, and integration with downstream systems. Serving is just one piece of that process.
Which AI model deployment platform is best for enterprises in regulated industries?
AWS SageMaker, Azure ML, and Hugging Face Inference Endpoints (enterprise tier) are the strongest options for regulated sectors due to their SOC 2, HIPAA, and data residency controls. SageMaker also offers FedRAMP authorization for government workloads. Your existing cloud infrastructure will often tip the decision — teams already on AWS have less migration friction with SageMaker, while Azure ML fits naturally into Microsoft-heavy environments.
How do I choose between open-source and managed AI deployment platforms?
Managed platforms (SageMaker, Vertex AI) are better for teams without dedicated MLOps engineers or those needing out-of-box compliance. Open-source/Kubernetes-native options (Seldon Core, KServe) suit teams with strong infrastructure skills who need maximum control and want to avoid vendor lock-in. Many enterprises use a hybrid approach.
How long does it take to deploy an AI model to production?
Timelines range from hours (simple model, managed platform, existing infrastructure) to weeks or months (new infrastructure, governance approvals, complex integrations). Teams with mature MLOps pipelines using platforms like Hugging Face Endpoints often reach their first live inference in under a day for straightforward use cases.
What are the most important factors when evaluating an AI model deployment platform?
Key factors include: scalability and autoscaling behavior (including scale-to-zero), pricing transparency and total cost of ownership, framework compatibility, security certifications (SOC 2, GDPR, data residency), depth of MLOps tooling (monitoring, versioning, CI/CD), and quality of enterprise support.
Conclusion
No single platform is universally superior—the right choice maps to your team's infrastructure, model types, compliance obligations, and internal skill sets. Enterprises in regulated sectors like BFSI should weight security certifications and data residency controls as heavily as raw performance.
Run a structured pilot before committing to a platform at scale. Deploy a non-critical model, measure time-to-first-prediction, and estimate true TCO including operational overhead. The real friction often shows up during integration, not the initial demo.
That integration complexity is especially pronounced in finance, tax, and compliance workflows, where model outputs feed directly into regulatory decisions, credit risk assessments, and invoice processing. Experienced implementation partners can reduce that friction significantly.
Cygnet.One's finance transformation platform has deployed AI across these workflows in production environments. One UK financial services client used Cygnet.One's AI-enabled risk forecasting and fraud detection to reach £175 million in GMV—a result driven by integration depth, not just model performance.


