Introduction
Enterprise data volumes aren't just growing — they're accelerating in ways that expose the structural limits of legacy infrastructure. In India alone, UPI grew 41.7% by volume and 30.3% by value in 2024-25, now accounting for 84% of retail payment volume. For BFSI organisations and large corporates processing millions of transactions daily, that velocity puts direct pressure on every database, pipeline, and reporting layer underneath.
The bottleneck isn't the data itself. It's the architecture: on-premises relational databases, monolithic warehouses, and batch ETL pipelines built for a lower-volume era — alongside departmental silos that fragment data at the point it's most needed. None of these were designed to support real-time analytics, AI/ML pipelines, or India's evolving compliance mandates.
This article covers the ground that matters most for organisations evaluating that shift:
- Why conventional stacks fail at scale
- What a modern data platform looks like, layer by layer
- How to approach migration without blowing timelines and budgets
- The challenges that derail most projects
- What measurable outcomes to realistically expect on the other side
Key Takeaways
- Conventional on-premises stacks cannot handle real-time analytics, AI/ML workloads, or modern compliance requirements
- Data platform modernization replaces legacy infrastructure with cloud-native architectures that unify storage, pipelines, governance, and analytics
- A modern platform is built in five layers — from cloud-native storage through to self-service analytics and AI integration
- Migration should be phased : audit first, pilot a single domain, then scale
- Measurable outcomes include faster decisions, lower infrastructure costs, and AI readiness
Why Conventional Data Stacks Are Holding Enterprises Back
The Architecture Problem
A conventional stack typically looks like this: on-premises relational databases, a monolithic data warehouse, scheduled batch ETL jobs running overnight, and separate data stores maintained by finance, operations, compliance, and customer teams. Each component was built for a world where data volumes were manageable, latency was tolerable, and analytics happened the next morning.
That model breaks under modern data conditions. As organisations accumulate structured transactional data, unstructured logs, API feeds, and IoT signals, legacy assumptions collapse fast:
- Hardware upgrades become frequent and expensive
- Query performance degrades under growing data volumes
- Reporting teams spend more time reconciling data than analysing it
Silos, Compliance Gaps, and the Cost of Both
According to McKinsey's 2024 master data management research, 80% of large organisations report divisions operating in silos with their own data management practices — and 62% lack a defined process for integrating new and existing data sources. The operational cost is real: 82% of those surveyed spent one or more days per week resolving master data quality issues manually.
For Indian enterprises, the compliance stakes are direct. Under GST regulations, invoices issued without an Invoice Reference Number (IRN) carry no legal standing. CBIC Circular No. 183 identifies ITC mismatch scenarios triggered by suppliers omitting supplies, filing incorrectly, or using the wrong recipient GSTIN.
When finance data sits across multiple ERP instances with no integration layer, reconciling GSTR-2B against vendor invoices becomes a manual, error-prone exercise — and audit trails become incomplete by design.
The AI Readiness Problem
AI and ML models require clean, unified, high-volume datasets with low-latency access. Batch systems with inconsistent formats cannot reliably feed ML pipelines. Gartner predicts that through 2026, organisations will abandon 60% of AI projects that lack AI-ready data. For most enterprises still running conventional stacks, advanced analytics remains within reach in theory — but consistently blocked in practice.
Key Components of a Modern Data Platform
A modern data platform isn't a single product. It's a layered architecture: each layer serves a distinct function, and all five work together as a cohesive system.
Layer 1: Cloud-Native Data Storage
Three storage paradigms form the foundation:
| Storage Type | Best For | Example Tools |
|---|---|---|
| Data Warehouse | Structured data, SQL analytics, enterprise reporting | Snowflake, Google BigQuery, Azure Synapse |
| Data Lake | Raw or semi-structured data at scale, lower cost | AWS S3, Azure Data Lake Storage |
| Data Lakehouse | Hybrid — warehouse performance with lake flexibility | Databricks, Apache Iceberg |

By 2024, Databricks reported that 74% of global CIOs already had a lakehouse in their estate — with nearly all remaining CIOs planning to adopt one within three years.
Layer 2: Data Ingestion and Pipeline Layer
This layer moves data from source systems into storage. Two approaches apply in different contexts:
- Batch ETL/ELT — scheduled, high-volume historical loads suited to overnight financial consolidation or weekly reporting cycles
- Streaming ingestion — real-time event processing via tools like Apache Kafka, suited to transaction monitoring, fraud detection, and compliance alerting
According to Confluent's 2024 Data Streaming Report, 86% of IT leaders prioritised investments in data streaming — reflecting how quickly real-time ingestion has moved from optional to expected.
Layer 3: Data Governance and Quality
Governance is not an add-on. Without it, even a well-architected platform produces unreliable outputs. This layer covers:
- Data cataloguing — knowing what data exists and where
- Lineage tracking — understanding where data came from and how it changed
- Access controls — role-based permissions at the dataset level
- Quality monitoring — automated profiling, validation, and anomaly detection
The cost of skipping this layer is measurable. Gartner estimates poor data quality costs organisations at least USD 12.9 million per year on average. Cygnet.One addresses this directly through a proprietary Metadata and Governance Toolkit covering data lineage tracking, quality frameworks, and compliance structures — embedded into client engagements rather than bolted on afterward.

Layer 4: Analytics, AI, and ML Integration
Validated lineage and quality-controlled data from Layer 3 is what makes analytics investments pay off. When the underlying platform is properly structured, every tool plugs into the same clean, unified dataset. This is where business outcomes are delivered:
- BI reporting — Power BI and Tableau dashboards running on consistent, trusted data
- Predictive models — ML platforms trained on complete, governed datasets
- Generative AI applications — LLM integrations grounded in structured, validated enterprise data
- Real-time compliance intelligence — automated alerts and audit trails from live data streams
Layer 5: Self-Service Data Access
Self-service transforms a technical platform into an organisational capability. Without it, data sits behind engineering bottlenecks — available in theory, inaccessible in practice.
This layer includes:
- Role-based dashboards — tailored views for finance, compliance, and operations teams
- Data marketplaces — curated, discoverable datasets available on demand
- No-code query interfaces — direct data access without SQL or engineering support
This is the layer that determines whether modernisation actually changes day-to-day decision-making.
The Migration Path: From Legacy Stack to Modern Platform
Phase 1 — Assessment and Inventory
Before any architecture decisions, map the current state:
- Identify all data sources and understand how data flows between systems
- Assess data quality across key domains
- Classify data by sensitivity and business criticality
- Define the specific objective the modernisation must serve — faster reporting, AI enablement, compliance automation, or cost reduction
This phase prevents expensive surprises mid-migration. Cygnet.One's ORBIT framework begins here with an "Observe" phase: auditing applications, infrastructure, dependencies, and data flows before any workload moves.
Phase 2 — Architecture Selection
Different contexts call for different architectures:
- Large enterprise with complex analytics needs → data lakehouse (Databricks, Apache Iceberg)
- Mid-market company with primarily structured transactional data → cloud data warehouse (Snowflake, BigQuery)
- Large enterprise with distributed teams and domain-specific data ownership → data mesh
Data mesh, originally articulated by Zhamak Dehghani, rests on four pillars: domain-oriented data ownership, data as a product, self-serve data infrastructure, and federated computational governance. It is an organisational and architectural approach, not a packaged technology. It suits enterprises where multiple business units need independent data autonomy within a governed framework.
Phase 3 — Phased Migration, Not Big Bang
Attempting to migrate everything at once is the leading cause of cost overruns and failed projects. The recommended approach:
- Select one high-priority data domain — financial reporting or GST reconciliation makes a strong pilot
- Migrate it to the new platform
- Validate data integrity and performance against the legacy baseline
- Document learnings and apply them to the next domain
- Scale incrementally across remaining domains
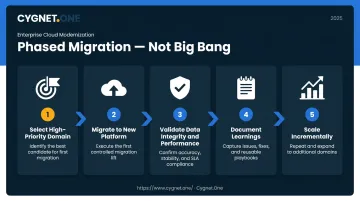
The ORBIT framework reflects this principle: migration occurs in controlled waves with parallel-run testing and rollback procedures at every stage.
Phase 4 — Governance and Change Management in Parallel
Governance and change management cannot be retrofitted after migration completes. Both must run alongside it from day one. Key workstreams to execute in parallel:
- Implement governance policies, access control frameworks, and metadata management as each domain migrates
- Train business teams on the new platform and establish clear data ownership per domain
- Secure and sustain leadership alignment to carry the programme beyond the initial pilot
Common Challenges in Data Platform Modernisation
Legacy Dependencies and Technical Debt
Older ERP systems, mainframe databases, and siloed departmental tools often lack native integration capabilities. Assuming clean source data from day one is a planning failure. Organisations should expect to implement API-based integrations or change data capture (CDC) techniques.
Real-world example: In pharmaceutical logistics migrations, Cygnet.One deployed CDC alongside Amazon Redshift with time-travel tracking — maintaining version control and historical accuracy across ERP, CRM, app telemetry, and logistics data simultaneously.
Data Quality Gaps Discovered Mid-Migration
Legacy systems regularly surface duplicate records, inconsistent formats, and missing values that weren't visible before migration began. McKinsey found 66% of organisations still rely on manual review to manage master data quality — which means quality problems are systematically underdetected before migration starts.
Data profiling and cleansing should be scoped as a dedicated pre-migration phase. Teams that skip this step typically spend more time fixing data mid-flight than the profiling work would have taken upfront.
Skills and Resource Gaps
Data quality issues rarely exist in isolation — they surface faster when teams lack the expertise to catch them early. Modern data platforms require cloud engineering expertise, data pipeline development skills, and governance tooling knowledge that most enterprises don't have in sufficient depth internally. Three options exist:
- Upskill internal teams (slower, but builds lasting capability)
- Hire specialists (faster, but competitive market)
- Engage a technology partner for technical execution while retaining governance ownership internally
The hybrid model is often the most practical path: a technology partner handles the technical migration while internal teams retain governance decisions and data ownership. This keeps institutional knowledge in-house while closing the delivery gap with specialist support.
Business Outcomes Enterprises Can Expect
Faster Decisions and Reduced Infrastructure Costs
Modern platforms collapse the gap between data generation and data availability. Overnight batch cycles that once produced morning reports can be replaced with near real-time dashboards that surface exceptions as they occur.
On infrastructure costs, a Microsoft-commissioned Forrester TEI study reported 379% ROI, USD 11.6M NPV, and payback in under six months for Microsoft Fabric deployments — and a 90% reduction in time data engineers spent searching, integrating, and debugging data.
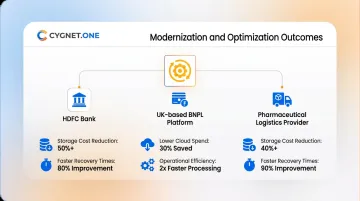
Cygnet.One's client engagements reflect comparable outcomes:
- HDFC Bank: 50% reduction in long-term storage costs and 75% faster recovery time following cloud modernisation on AWS
- UK-based BNPL platform: 30% lower AWS spend and 40% faster feature delivery through microservices modernisation
- Pharmaceutical logistics provider: 25% reduction in operational costs and 20% boost in operational efficiency through centralised data warehouse implementation on Amazon Redshift with CDC
AI Readiness for Regulated Industries
Cost and speed gains open a second opportunity: layering AI and ML on the clean, governed foundation that modernisation creates. For enterprises in BFSI and tax-heavy sectors, this shifts AI from pilot projects to production workloads.
Cygnet.One's finance transformation platform demonstrates what that foundation can support at scale:
- Processes 55 million transactions per month
- Handles 15–19% of India's e-invoice volumes
- Delivered 95% reduction in report processing time for an Indian NBFC
- Achieved 90% faster process cycles through direct tax compliance automation
These outcomes are only reachable when the data layer is purpose-built for high-stakes financial and compliance workloads — not patched onto legacy infrastructure.
Frequently Asked Questions
What is data platform modernisation?
Data platform modernization is the process of replacing or upgrading legacy infrastructure — databases, pipelines, and storage systems — with scalable, cloud-native architectures. The goal is faster analytics, stronger governance, and better compliance readiness across the enterprise.
What are the five layers of a data platform?
The five layers are: cloud-native data storage, data ingestion and pipeline layer, data governance and quality controls, analytics and AI/ML integration, and self-service data access. Each layer is interdependent — gaps in one affect the reliability of the whole system.
What are the four pillars of data mesh?
The four pillars are domain-oriented data ownership, data as a product, self-serve data infrastructure, and federated computational governance. This organizational model suits large enterprises where business domains need independent data autonomy within a shared governance structure.
What is the difference between a data lake and a data warehouse?
A data warehouse stores structured, processed data optimised for query performance and reporting. A data lake stores raw data in any format — structured or unstructured — at lower cost. Modern data lakehouses combine both capabilities, delivering warehouse performance on lake-scale storage.
How long does migration typically take?
Timelines vary based on data complexity, number of source systems, and migration strategy. Simple migrations may take a few months; large-scale enterprise transformations involving cloud adoption, governance frameworks, and phased domain migrations commonly span one to two years.
What are the biggest migration challenges?
Legacy system dependencies, data quality issues uncovered mid-migration, and skills gaps in cloud engineering and governance are the most common blockers. Phased planning, early data profiling, and experienced implementation partners reduce all three risks considerably.