
Introduction
A disaster recovery plan sitting in a shared folder is not a recovery plan. It is a set of assumptions that have never been challenged.
When an actual outage hits, untested plans typically collapse at the first step — whether from a ransomware attack, hardware failure, or data corruption. A team member who was supposed to lead the failover has left the company. A critical server is missing from the inventory.
The backup meant to restore three hours of data turns out to be four days old.
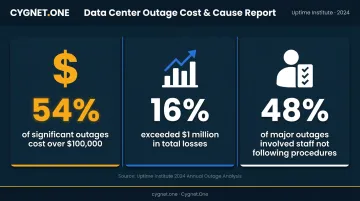
The stakes are real. Uptime Institute's 2024 outage analysis found that 54% of significant outages cost more than $100,000, and 16% exceeded $1 million. The same research found that 48% of major outages involved staff not following established procedures — the kind of failure that structured DR testing is designed to catch before it counts.
This guide covers what you need before testing, the five main DR test types and how to run each one, how to measure results against RTO and RPO, and the most common mistakes that go undetected in test outcomes.
Key Takeaways
- A DR test validates that your plan works before a real disaster — not during one
- Five test types exist (plan review, walkthrough, tabletop, parallel, cutover), each increasing in realism and risk
- Every test result must be measured against defined RTO and RPO benchmarks to determine pass or fail
- Retest annually at minimum, and after every major infrastructure change
- A failed test is valuable; an ignored failed test is a liability
What You Need Before Testing Your Disaster Recovery Plan
Running a DR test without adequate preparation produces misleading results. Teams that walk in underprepared often declare success when critical gaps still exist. Before the test starts, confirm you have the right people present, documentation ready, and a clearly defined scope.
Team and Stakeholder Readiness
DR testing is not an IT-only exercise. The people who must execute recovery steps in a real event need to be present during practice runs.
Who must be in the room:
- IT infrastructure leads — own the technical recovery steps
- Application owners — validate that systems are functioning post-recovery, not just online
- Department heads — confirm that business processes actually work in the restored environment
- A designated scribe — documents every action and timestamp in real time
- A designated timekeeper — tracks progress against RTO milestones
For organizations running compliance-critical operations (GST reconciliation, e-invoicing workflows, or financial reporting), finance and compliance team representatives are essential. A recovered system that cannot process a tax filing or submit to a government portal like the IRP has not actually recovered.
DR implementations in tax compliance environments typically require documented ownership across both technical and operational teams — not just infrastructure roles — with structured escalation paths defined before any test begins.
Documentation and Tools Required
Prepare these before the test begins — not during it:
- Current DR plan document (version-controlled and dated)
- System inventory covering servers, applications, and network dependencies
- Contact lists with backups for every key role
- Defined RTO and RPO targets per system tier
- Backup verification reports confirming the last successful restore
- Test scripts and scenario descriptions
For organizations subject to SOC 2 Type II, HIPAA, or financial sector requirements, the test scope should also include the relevant audit trail requirements. HIPAA requires DR documentation to be retained for six years; AICPA's SOC 2 Availability criterion A1.3 requires evidence that recovery plan procedures have been tested. Plan for this evidence before the test, not after.
Scoping and Environment Setup
Define scope in writing before the test starts. Specifically:
- Identify which systems and applications are in scope for this test cycle
- Confirm the test environment is isolated from production — no live data, no live government-connected endpoints
- Document any pre-approved exceptions (for example, not triggering live IRP submissions during an e-invoicing recovery test)
- Treat all unplanned deviations from the documented procedure as failures, not workarounds
For cloud-native environments, test isolation should be engineered into the infrastructure itself — for example, through separate availability zones, read replicas, and DNS-level failover configurations — rather than managed as a manual step on test day.
Types of DR Tests and How to Run Each
DR testing spans a spectrum — from a low-risk document review to a full production cutover. The right starting point depends on your team's maturity, how critical the systems involved are, and how recently major infrastructure changes occurred.

Plan Review and Walkthrough
What it is: Individual reviewers read and annotate the DR plan, then the team convenes to reconcile findings. No systems are activated.
How to run it:
- Distribute the current DR plan to all stakeholders at least 48 hours before the session
- Each reviewer annotates gaps — outdated contacts, unclear handoffs, missing systems, ambiguous steps
- Convene the team to reconcile all annotations, assign owners to each gap, and set deadlines for updates
Best for: First-time testing, newly written plans, or verifying a plan after significant edits.
Limitation: Confirms the plan is readable. Does not confirm it works.
Tabletop Exercise
What it is: A facilitated discussion where the full team walks through a realistic disaster scenario — ransomware attack, ISP failure, primary data center outage, or cloud region failure — decision by decision, without activating any systems.
How to run it:
- Facilitator presents a scenario relevant to your actual risk profile (not a generic template)
- Each team member talks through their role, the decisions they would make, and the steps they would execute in sequence
- Facilitator records gaps, delays, role confusion, and steps the team cannot complete — all findings go into the after-action report
Best for: Identifying communication breakdowns, role ambiguity, and missing escalation paths. FEMA's Exercise Starter Kits provide structured facilitator guides and evaluation templates for running these sessions.
Limitation: Tests knowledge and process, not actual system recovery capability.
Full Simulation, Parallel, and Cutover Tests
What it is: The recovery environment is actually activated. In a parallel test, it runs alongside production. In a cutover test, production is disconnected and the DR environment carries the full workload.
How to run it:
- Notify relevant teams, schedule a maintenance window, and execute recovery using documented procedures only — no assistance from subject matter experts who would not be available in a real event
- Validate that critical applications are running, data integrity is intact, and business transactions can be processed; record exact timestamps for each recovery milestone
- For cutover tests: disconnect production entirely, confirm the DR environment handles full load, then restore and compare all timings against RTO and RPO targets
Best for: Proving end-to-end recovery capability. Uncovers integration failures, data sync gaps, and staffing issues that tabletop exercises cannot detect.
Limitation: Highest operational risk of the three test types; requires careful scheduling and rollback planning. DRJ's 2023 Business Continuity Preparedness study found 56% of respondents never perform a full simulation — meaning most organizations only discover recovery gaps during an actual outage. Cygnet.One runs quarterly failover simulations and rollback drills for its tax compliance infrastructure, validating an RTO of 1 hour and RPO under 30 minutes for Tier-1 services.

How to Interpret DR Test Results
Declaring a pass without examining deviations is how DR programs quietly fail. Every test result needs to be evaluated against three benchmarks: RTO/RPO targets, documented exceptions, and completeness of execution.
What a Passing Test Looks Like
A test passes when all of the following are true:
- All critical systems restored within the defined RTO
- Data loss falls within the RPO window
- Every step was executed by the assigned team member without improvisation
- All contact points reached the right people without ad hoc workarounds
Document the exact recovery time. This becomes your baseline for tracking across future tests.
Minor Gaps vs. Outright Failure
Not every imperfection is a failure — but nothing should be left unaddressed.
Minor gaps — a 10% timing overrun, one unreachable contact, a single step requiring a workaround — should be flagged as findings and corrected before the next cycle. They do not invalidate the test, but they cannot be left open.
Automatic failures include:
- A critical system not recovered within the RTO
- Data loss exceeding the RPO window
- Team members accessing production during the test to retrieve missing files
- Undocumented steps required to complete recovery
For each failure point: assign a remediation owner, set a deadline, and schedule a targeted retest within 30–60 days. A failed test in a controlled environment is far more valuable than a falsely passed one.
Common Mistakes in DR Testing
Testing Under Artificially Favorable Conditions
Most DR tests are scheduled months in advance, participants are thoroughly briefed, and exercises run during convenient business hours. None of this reflects a real disaster.
The FFIEC explicitly states that test scenarios should simulate realistic disruptions, not convenient ones. As your team's DR maturity grows, introduce partially unannounced elements — for example, the test starts without the lead engineer knowing it is happening — to close the gap between drill conditions and actual crisis conditions.
Skipping Ransomware and Data Recovery Scenarios
Standard DR tests focus on infrastructure failover. They do not test recovery from a ransomware event, where the most recent backup may itself be compromised.
Sophos' 2024 analysis found that attackers attempted to compromise backups in 94% of ransomware attacks, and 57% of those attempts succeeded. Recovering from ransomware means identifying the last clean restore point. That process differs from standard failover and must be tested separately.
CISA's guidance is clear: test backup availability and integrity as part of your DR scenario, not as a separate exercise bolted on later.
Not Updating the DR Plan After Infrastructure Changes
Every new application, cloud migration, server upgrade, or third-party integration changes the recovery dependency map. Testing a DR plan that no longer reflects your actual environment measures nothing useful.
DRJ's 2023 study found 51% of organizations update their DR plans only once per year. Any of the following should trigger an out-of-cycle review and retest:
- New ERP or third-party integration
- Cloud migration or infrastructure upgrade
- Major application deployment or decommission
Waiting for the annual scheduled date after a significant change means your next test is measuring a plan that no longer matches your environment.
DR Testing Frequency and Best Practices
Testing cadence should be driven by RTO requirements and the pace of infrastructure change, not a fixed annual calendar.
Use these thresholds to set your baseline cadence:
- Longer RTOs (24+ hours): Annual testing is typically adequate for low-criticality systems
- Sub-24-hour RTOs: Quarterly testing is appropriate for systems where downtime directly impacts revenue or compliance
- After major changes: Any significant infrastructure event — cloud migration, ERP upgrade, new application — should trigger an out-of-cycle test regardless of the scheduled cadence

Frequency alone isn't enough. How you run and document each test determines whether the results hold up under audit or incident pressure. Follow these operational practices every cycle:
- Always designate a timekeeper and a scribe; never rely on memory for timing or decisions
- Archive all test results, audit logs, and remediation evidence. HIPAA requires documentation retention for six years; SOC 2 Type II audits require evidence spanning the full audit period
- Treat every documented exception as a debt that must be resolved before the next test cycle
- Progress test rigor over time — from plan review to tabletop to full simulation — as team DR maturity develops
Conclusion
An untested DR plan tells you nothing about whether your organization can actually recover. The only way to find out is to simulate recovery under realistic conditions, measure the results honestly, and close the gaps that surface.
If testing hasn't started yet, a straightforward path forward looks like this:
- This week: Conduct a plan review with key stakeholders
- This quarter: Schedule a tabletop exercise to surface procedural gaps
- This year: Progress toward simulation or cutover testing as team readiness grows
Document every result, every gap, and every remediation action. That record is what gives leadership confidence in recovery timelines — and gives your team a concrete baseline to improve against each cycle.
Frequently Asked Questions
How do you test a disaster recovery plan?
Start by defining your RTO and RPO benchmarks, then choose a test type — plan review, tabletop, simulation, or cutover — based on system criticality and team readiness. Run the test with the full stakeholder group, measure every recovery milestone against your benchmarks, and document all gaps for remediation before the next cycle.
What is RPO and RTO with examples?
RPO (Recovery Point Objective) defines the maximum acceptable data loss in time — for example, a 4-hour RPO requires backups at least every 4 hours. RTO (Recovery Time Objective) defines the maximum acceptable downtime; a 2-hour RTO means systems must be restored within 2 hours of a declared disaster.
How often should you test your disaster recovery plan?
At minimum, annually. Organizations with sub-24-hour RTOs or compliance obligations should test quarterly. Any major infrastructure change — cloud migration, new ERP deployment, or significant application upgrade — warrants an additional out-of-cycle test.
What is the difference between a tabletop exercise and a simulation test?
A tabletop exercise is a discussion-based walkthrough of a disaster scenario with no systems activated — it tests knowledge and process. A simulation test actually deploys recovery systems and measures real recovery times, proving whether the technology and plan work end-to-end.
What happens if a DR test fails?
Treat it as diagnostic data, not a setback. Document each failure point, assign a remediation owner and deadline, update the DR plan, and schedule a targeted retest within 30–60 days. A controlled failure is far more valuable than discovering the same issue during an actual disaster.
Who should be involved in disaster recovery testing?
Testing should include IT infrastructure leads, application owners, department heads with process dependencies, a designated timekeeper, and a scribe. Regulated industries should also include compliance or audit representatives — limiting testing to the IT team routinely leaves operational gaps undetected.


