

































IT downtime rarely announces itself in advance, yet its impact is immediate, costly, and often chaotic. For enterprise teams juggling complex systems, even a few minutes of disruption can ripple across operations, customer experience, and revenue within the same window in which the incident began.
The cost of each hour of downtime shows up in both revenue loss and team overtime, customers notice faster than ever thanks to status pages and social channels, and the internal IT team absorbs the pressure of diagnosing, communicating, and fixing the issue while the clock keeps running.
Downtime is never entirely avoidable, though it is largely controllable. What separates enterprises that treat it as a cost of doing business from those that compound uptime gains year over year is a deliberate combination of process, technology, and people working toward a single resilience goal.
In this guide, we walk through what IT downtime actually is, why reducing it has become a core business priority, what typically causes it, a five-step framework for minimizing it, the tools that make the framework operational, the metrics that turn effort into evidence, and the recurring challenges enterprises hit on the way.
What Is IT Downtime?
IT downtime is any period during which systems, applications, or services are unavailable to the users who depend on them.
IT downtime comes in two main forms:
- Planned downtime
- Unplanned downtime
Planned downtime covers the windows enterprise’s schedule intentionally for maintenance, upgrades, patching, or migrations, usually communicated in advance and timed to minimize disruption.
Unplanned downtime covers the failures that arrive without warning, including hardware breakdowns, software crashes, cyberattacks, and cascading dependencies that take down services that should have been isolated.
The severity of planned and unplanned downtime varies significantly. A partial outage might affect a single feature, region, or user segment while leaving the broader platform functional, while a full system shutdown reaches every user and every workflow touching the environment.
Both count, and both carry business cost in the form of operational delays, direct revenue loss, and brand reputation damage when inconsistency becomes a pattern rather than an exception.
Why Reducing IT Downtime Is Critical for Enterprise Performance
Reducing downtime has moved from a narrow IT objective to a direct driver of business continuity, customer trust, and competitive positioning.
The business implications compound quickly when they accumulate. Revenue leaks during any minute a transactional system is offline, customer-facing outages drive churn as users route to whichever competitor is working, and the cost of each hour of downtime now regularly lands in six-figure territory for enterprises with significant digital operations.
Operational risks follow the same compounding pattern. Modern enterprise systems are deeply interconnected, so a single failure in a payment gateway, identity provider, or data pipeline can cascade across every application that depends on it.
Supply chain systems are particularly exposed because partner integrations, EDI feeds, and vendor portals all rely on availability that sits outside direct control.
Compliance and regulatory exposure add another layer. Regulators in financial services, healthcare, and public infrastructure increasingly expect documented uptime, recovery, and incident reporting.
Repeated outages trigger audit findings and, in some jurisdictions, financial penalties that make uptime a board-level concern rather than an operations-team metric.
Productivity is the quieter cost. When systems are unavailable, employees wait, decisions stall, and project timelines slip. The work does not disappear. It gets compressed into overtime or deferred to the next cycle at a higher blended cost than if the system had simply stayed up.
Digital transformation amplifies every one of these pressures. More systems mean more failure points, more integrations mean more cascading risk, and more real-time business processes mean downtime tolerance has dropped to near zero in the areas where the business most wants to compete.
High-performing enterprises now treat uptime as a core KPI with executive ownership, and organizations adopting integrated IT operations platforms that unify monitoring, incident response, and infrastructure management consistently see measurable uptime improvements compared to environments running fragmented tools.
According to Gartner’s 2026 forecast on worldwide IT spending, global IT spending is projected to reach USD 6.15 trillion in 2026, up 10.8% from 2025. A meaningful share of that increase is flowing into the resilience, observability, and automation layers that directly influence downtime outcomes.
Common Causes of IT Downtime in Modern IT Environments
Understanding root causes of IT downtime helps enterprises shift from reactive firefighting to proactive prevention.
1. Infrastructure and Hardware Failures
Physical infrastructure fails with predictable regularity at scale. Servers age, disks degrade, network switches drop packets, and power or cooling incidents in a data center or co-location facility can take out entire racks at once.
Network issues are the most common contributor in this category, with misconfigured routing, DNS problems, and carrier outages accounting for a large share of incidents.
Cloud infrastructure reduces but does not eliminate this class of failure, since enterprises remain exposed to zone-level or region-level events in the hyperscaler’s environment.
2. Software Bugs and Misconfigurations
Software is the largest source of preventable downtime in most modern environments. Bugs that escape testing, regressions introduced by otherwise-safe changes, configuration drift between environments, and feature flags accidentally enabled in production account for a steady drumbeat of incidents.
Database schema changes and third-party library updates carry a particularly high blast radius when they go wrong, because the failure often surfaces hours after deployment once real traffic touches the affected code path.
3. Human Errors and Deployment Mistakes
Human errors remain one of the top causes of downtime, even in environments with strong automation. Incorrect deployments, manual changes made under pressure, accidentally dropped database tables, and mistakes during routine maintenance windows all show up in post-incident reports.
The root cause is rarely a single careless engineer. Most reviews trace the underlying issue to a process flaw that put a person in a position to make a consequential change without sufficient guardrails, testing, or review.
4. Cybersecurity Incidents
Ransomware, DDoS attacks, credential-based intrusions, and supply-chain compromises each have the potential to cause significant downtime, either directly by taking systems offline or indirectly by triggering forced isolation and rebuilds during the response.
Cybersecurity-driven downtime also tends to be longer than operational downtime because recovery must be paired with forensics, root-cause analysis, and validation that the environment is safe to restore before traffic returns.
According to the 2025 IBM Cost of a Data Breach Report, the global average cost of a data breach reached USD 4.44 million in 2025, with a significant share of that cost tied to extended downtime and business disruption rather than the breach event itself.
Cygnet.One’s Cybersecurity practice delivers continuous monitoring, threat detection, and incident response designed to shorten both the detection window and the downtime that follows a security incident.
5. Hybrid, Multi-Cloud, and Legacy Complexity
Modern IT environments rarely sit on a single platform. Most enterprises operate across multiple cloud providers, private data centers, SaaS applications, and legacy on-premise systems, each with its own availability characteristics, monitoring tooling, and failure modes.
Legacy dependencies are a particular risk because the applications or libraries involved may no longer be actively supported, and the engineers who knew how they worked may have moved on. Complexity of this kind makes root-cause analysis harder and extends mean-time-to-resolution on the incidents that do occur.
6. Monitoring and Operational Gaps
A recurring contributor is the absence of the monitoring, alerting, and incident-response maturity that would have surfaced an issue before it escalated.
Incidents that could have been caught at the early warning stage often reach full outage because the monitoring was incomplete, alerts were misconfigured or silenced, runbooks were missing or out of date, or on-call coverage had gaps during the window when the failure emerged.
Downtime is often the compounding effect of multiple small failures rather than a single catastrophic event, which is why enterprises running unified observability and integrated automation platforms consistently reduce these root causes instead of only responding faster when they trigger.
Framework for Minimizing IT Downtime in Enterprise Environments
A structured framework ensures that downtime reduction efforts are systematic, measurable, and continuously improving rather than project-based and reactive. The five steps below sequence the work from understanding the current state through building the operating model that sustains uptime over time.
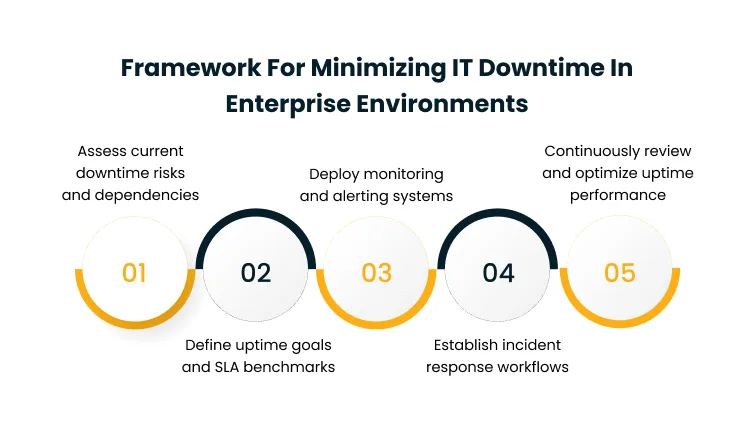
Step 1: Assess Current Downtime Risks and Dependencies
Enterprises need a clear inventory of critical systems, their dependencies, and the failure modes that would affect them. This includes mapping which applications depend on which infrastructure layers, which services share underlying databases, which integrations rely on third-party APIs, and which systems are load-bearing for specific business processes.
Dependency maps of this kind prevent cascading failures because teams understand ahead of time where a single component outage will ripple, and they form the foundation that every later step of the framework depends on.
Step 2: Define Uptime Goals and SLA Benchmarks
Without measurable targets, downtime reduction efforts drift. The second step is setting explicit service-level agreements and service-level objectives that reflect business priorities rather than generic engineering defaults.
Customer-facing revenue systems typically warrant tighter SLAs than internal tools, executive dashboards often deserve different thresholds than back-office reporting, and tier-one infrastructure carries availability expectations that support systems do not.
Clear benchmarks make accountability visible, enable meaningful incident retrospectives, and give the IT organization a shared definition of success that the business can review alongside other operating metrics.
Step 3: Deploy Monitoring and Alerting Systems
With goals defined, the third step is instrumenting the environment to detect deviations from those goals before users do.
Real-time monitoring across infrastructure, applications, networks, and user experience is the baseline, paired with alerting thresholds calibrated to signal genuine problems rather than noise.
Alert prioritization matters as much as coverage, because noise from non-critical alerts trains responders to ignore the channel entirely. Mature environments invest in alert grouping, correlation, and deduplication as core capabilities, not as afterthoughts.
Step 4: Establish Incident Response Workflows
Even the best monitoring is only useful if the response is fast and coordinated. The fourth step is defining the roles, responsibilities, escalation paths, and communication protocols that kick in when an incident is declared.
Severity levels clarify what counts as a page-worthy event versus a business-hours issue. Named incident commanders, communicators, and scribes prevent confusion during the response.
Scheduled communication checkpoints keep internal stakeholders and external customers informed without pulling responders away from the fix.
Step 5: Continuously Review and Optimize Uptime Performance
Uptime maturity comes from continuous improvement rather than one-off projects. The final step is institutionalizing post-incident reviews, tracking recurring failure patterns, and feeding the lessons back into prevention.
Reviews should identify which incidents could have been caught earlier, which runbooks were missing, and which architectural weaknesses need prioritized remediation.
Enterprises running integrated IT service and analytics platforms often streamline this continuous improvement loop by correlating incident data with infrastructure and application telemetry in a single view, which shortens the cycle from detection to architectural change.
Cygnet.One’s Managed IT Services practice runs this full uptime operating model end-to-end for enterprise clients, covering assessment, SLA management, monitoring, incident response, and continuous improvement as one integrated service rather than a set of fragmented tools and teams.
Tools and Technologies That Help Reduce IT Downtime
The right combination of tools enables enterprises to operationalize their downtime reduction strategies at scale. Tools alone do not produce uptime, though the right ones make the operating model faster, more consistent, and easier to sustain.
The four categories below cover the core capability areas that every mature uptime program depends on:

1. System Monitoring and Observability Tools
Monitoring and observability tools provide the telemetry layer that makes uptime measurable.
Infrastructure monitoring tracks the health of servers, networks, storage, and cloud resources, while application performance monitoring tracks latency, error rates, and transaction volumes at the application layer.
Modern observability platforms unify these views and add distributed tracing, log aggregation, and real-user monitoring, which together allow teams to diagnose issues spanning multiple systems without manually correlating data across separate tools.
2. Incident Management Platforms
Incident management platforms operationalize the response side. Ticketing, on-call rotation, automated escalation, status page integration, and post-incident documentation all live here.
The strongest platforms integrate with monitoring to open incidents automatically when thresholds are breached, and with communication tools to update stakeholders without manual coordination.
The payoff is faster response, fewer dropped hand-offs, and a reliable system of record for the reviews that follow each incident.
3. Backup and Disaster Recovery Solutions
Backup and disaster recovery solutions form the resilience layer for the scenarios that monitoring and response cannot prevent.
Regular backups protect data integrity, disaster recovery plans define the failover procedures for catastrophic events, cloud backups provide geographic redundancy, and failover systems allow traffic to shift to secondary environments when the primary fails.
Recovery time and recovery point objectives should be set against business tolerance rather than technology defaults, so that the resilience investment matches the actual cost of downtime in each workload.
4. Infrastructure Automation Tools
Infrastructure automation reduces the manual-intervention risk that remains one of the largest causes of downtime.
Deployment automation ensures changes move through environments in a predictable, repeatable way. Configuration management enforces a consistent state and detects drift before it causes issues.
Infrastructure-as-code lets teams reproduce environments reliably, roll back cleanly, and apply changes with peer review and testing built in.
Cygnet.One’s Infrastructure Management practice brings monitoring, automation, and configuration management together for enterprise clients, and our Application Managed Services practice extends the same operating model to the application layer, where most user-visible downtime originates.
Integrated enterprise platforms that combine automation, monitoring, and service management continue to outperform fragmented tool stacks on uptime outcomes at scale.
Key Metrics to Track and Improve Uptime
Tracking the right metrics moves uptime decisions from assumption to evidence. The metrics below are the ones that consistently translate into actionable improvement.
Measuring them accurately requires the monitoring and incident management layers from the earlier sections to be in place, which is why metrics are the output of the operating model rather than the starting point.
1. Mean Time to Detect (MTTD)
MTTD measures how quickly an incident is identified once it begins. Low MTTD means monitoring and alerting are working, and the clock on customer impact started ticking before users started reporting.
High MTTD typically points to coverage gaps in monitoring, alert fatigue that is causing responders to miss signals, or runbooks that are not triggering the right on-call rotations in time.
2. Mean Time to Resolve (MTTR)
MTTR measures how quickly an incident is resolved once it is detected. MTTR captures the full response path, including diagnosis, coordination, fix, verification, and communication.
Improvements here usually come from better runbooks, faster escalation, automation of common fix actions, and reducing the coordination overhead that often consumes more time than the technical fix itself.
3. System Availability Percentage
Availability is the share of a reporting period during which a system was operational. Five-nines availability (99.999%) allows less than five and a half minutes of downtime per year, which is achievable only with deliberate architecture and operating investment.
Most enterprise systems target three to four nines, depending on criticality, and tracking availability against that target keeps investment decisions grounded in measured outcomes instead of aspirational ones.
4. Incident Frequency and Downtime Duration
Availability summarizes the outcome, while frequency and duration expose the shape of the downtime underneath it.
Incident frequency shows how often failures occur, duration shows how severe each one is, and trend analysis exposes patterns such as peak outage times or recurring root causes that broader availability numbers can mask.
Sustained improvement depends on reducing both frequency and duration rather than improving only one dimension.
Common Challenges in Reducing IT Downtime (and How to Overcome Them)
Many enterprises struggle with persistent downtime despite investment, and the challenges below show up consistently as the structural blockers.
1. Legacy Systems and Technical Debt
Aging infrastructure, unsupported operating systems, and applications built on frameworks that are no longer actively maintained create disproportionate downtime risk.
Legacy systems fail in ways that are hard to diagnose, they resist modern monitoring and automation, and the engineers who understand them are increasingly scarce.
The path forward is a structured modernization program that replatforms or refactors the highest-risk legacy systems onto modern architectures, often using cloud migration as the forcing function that resets the infrastructure assumptions across the portfolio at once.
2. Skill Gaps in Uptime-Critical Domains
The specialist skills needed for modern uptime work, including site reliability engineering, observability, cloud architecture, and security operations, are scarce and expensive.
Internal teams frequently struggle to build and retain the depth required for complex environments, and the gap widens every year as tooling and practices evolve.
According to Gartner’s 2026 CFO survey on AI and digital talent, acquiring and developing AI and digital talent is the top near-term challenge cited by CFOs, and the shortage shows up directly in the uptime work where modern skills are in the highest demand.
Targeted training, intuitive automation tooling, and managed services together usually outperform any single-lever approach.
3. Tool Fragmentation
Most enterprises run more monitoring, logging, and alerting tools than they need, accumulated through team-level purchases and legacy deployments.
Fragmentation slows diagnosis because data is scattered across systems, drives up licensing costs, and leaves coverage gaps where no tool clearly owns a category.
Consolidating around a smaller set of integrated platforms usually produces better uptime outcomes than layering in another specialized tool, and the consolidation itself often surfaces monitoring blind spots that were hidden by tool redundancy.
4. Reactive Operational Culture
Teams stuck in firefighting mode rarely have the bandwidth to invest in the preventive work that would reduce firefighting over time.
Breaking the cycle requires executive commitment to proactive capacity, including protected engineering time for reliability improvements, blameless post-incident reviews, and explicit measurement of preventive work alongside incident response.
Organizations adopting unified, scalable enterprise solutions often accelerate this shift because consolidated tooling and managed support free internal capacity for the architectural and process work that actually moves the uptime number.
Conclusion
Reducing IT downtime is an ongoing commitment to resilience, efficiency, and continuous improvement rather than a one-time initiative. Each cycle of investment pays back in revenue protected, customers retained, and team capacity freed for strategic work that a firefighting culture never gets to.
The takeaways that hold up consistently across the enterprise environments we work in are:
- Proactive strategies outperform reactive ones in every measurable dimension, from cost to incident frequency to customer satisfaction.
- Tools, processes, and people all matter, and investing in only one of the three produces uneven results.
The path forward starts with an honest assessment of the current state, builds a structured framework that sequences the work, and is enabled by technology choices fitting the specific environment rather than generic recommendations.
Small improvements compound into significant uptime gains over time, which is why the enterprises that pull ahead treat the work as continuous rather than project-based.
Enterprises exploring integrated digital transformation and IT operations solutions, such as those offered by Cygnet.One, often finds a more cohesive path to minimizing downtime while scaling efficiently across cloud, data, security, and infrastructure.
If your team is working through persistent downtime issues and would benefit from a structured view against your specific environment, book a demo to discuss how Cygnet can support your uptime roadmap across infrastructure, applications, and managed operations.
FAQs
AI and machine learning analyze historical system data to identify patterns and anomalies that precede failures. By using predictive analytics, enterprises can detect risks early, automate preventive actions, and reduce unexpected outages without relying solely on manual monitoring.
Cloud architecture improves resilience through distributed infrastructure, auto-scaling, and built-in redundancy. It allows workloads to shift across regions during failures, ensuring continuity. Properly designed cloud environments can significantly reduce downtime compared to traditional on-premise setups.
Enterprises should test disaster recovery plans at least twice a year, with additional tests after major infrastructure or application changes. Regular testing ensures systems, teams, and processes are prepared, reducing recovery time and minimizing risks during real incidents.
High availability focuses on minimizing downtime through redundancy and quick recovery, while fault tolerance ensures systems continue operating without interruption even when components fail. Both approaches are important, though fault tolerance typically requires more advanced infrastructure design.
Third-party vendors can introduce risks through service outages, integration failures, or security vulnerabilities. Enterprises should assess vendor reliability, establish clear SLAs, and implement monitoring for external dependencies to reduce the impact of vendor-related disruptions.
Clear and timely communication is essential during downtime. Provide real-time updates, explain the issue without technical jargon, and share expected resolution timelines. Transparency builds trust and helps manage customer expectations, even during prolonged service disruptions
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.