

































Both data lakes and data warehouses solve a storage problem, but for different workloads, different users, and different goals.
A data lake stores raw, unstructured, and semi-structured data at virtually unlimited scale, with no transformation required at ingestion. A data warehouse stores cleaned, structured data optimized for fast querying and business analytics.
According to the 2026 Gartner Predictions for Data and Analytics, IT spending on multi-structured data management will account for 40% of total data management spend by 2027. The systems used to store, govern, and serve that data sit at the center of that investment.
This blog walks through how each system works at the structural level, where each one fits, and how modern data architecture brings both together.
Data Lake vs Data Warehouse: What’s the Difference?
Data lake vs data warehouse is a core architectural question for any enterprise that depends on data for decisions. A data lake holds raw data in its native format, waiting for engineers or analysts to apply structure at query time. A data warehouse holds pre-processed, structured data that is immediately ready for fast analytics.
Understanding this starting difference makes every other architectural decision easier to reason through.
- Data lake: raw, flexible, schema-on-read, low-cost storage
- Data warehouse: structured, analytics-ready, schema-on-write, high-performance querying
What is a Data Lake?
A data lake is a centralized repository that stores data in its raw, native format at scale, with no transformation required at the point of ingestion. It applies structure only at query time, giving data engineers and data scientists the flexibility to work with any data type for any use case.
- Stores all data types: logs, images, video, JSON, sensor outputs, and relational records
- Low-cost cloud object storage (Amazon S3, Azure Data Lake Storage, Google Cloud Storage)
- Built for data engineers and data scientists running ML pipelines and exploratory analytics
- Requires external governance tooling (catalogs, quality checks, and access controls) to stay usable at scale
What is a Data Warehouse?
A data warehouse is a structured, analytics-optimized system that stores cleaned, transformed data from multiple operational sources. It enforces a defined schema before data enters, ensuring every query returns consistent, reliable results.
- Stores structured, relational data that has been cleaned and validated before ingestion
- Built for fast SQL query performance across dashboards, reports, and KPI tracking
- Primarily accessed by business analysts, operations teams, and executives via BI tools
- Native governance capabilities, including role-based access controls, audit trails, and schema enforcement
These definitions cover the basics, but it’s necessary to understand structural differences and their practical implications in detail.
Data Lake vs Data Warehouse: Key Differences Explained
Data lakes and data warehouses are different in purpose, structure, cost, and the users who access them. The side-by-side comparison below lays out where each system stands on the dimensions that matter most in production.
| Feature | Data Lake | Data Warehouse |
| Data Type | Structured, semi-structured, and unstructured | Structured data only |
| Schema Approach | Schema-on-read (applied during analysis) | Schema-on-write (applied before storage) |
| Data Processing | Raw data stored as-is | Data cleaned and transformed before storage |
| Storage Cost | Low-cost, scalable (often cloud-based) | Higher due to optimized storage and compute |
| Performance | Slower without optimization layers | Fast query performance for analytics |
| Primary Use Cases | Big data storage, ML, data exploration | BI, reporting, dashboards |
| Users | Data engineers, data scientists | Business analysts, decision-makers |
| Data Governance | Requires external tooling | Built-in governance and quality controls |
| Scalability | Highly scalable for large volumes | Scales with higher cost implications |
| Flexibility | Highly flexible, multiple data formats | Less flexible, structured for specific use cases |
This comparison captures what separates the two systems at a structural level. In practice, each distinction plays out differently depending on who is using the data and what they are trying to do with it.
1. Structured vs Unstructured Data Handling
Data lakes accept everything. Logs, JSON, images, video, IoT sensor outputs, and relational records all land in the same storage layer without transformation. This makes a data lake the right destination when data arrives in high volume from multiple sources, and the full use case is not yet defined at ingestion time.
Data warehouses work within a narrower scope. Only structured, tabular data passes through, and it must conform to a predefined schema before storage.
In short:
- Use a data lake when the data type is unpredictable, varied, or unstructured
- Use a data warehouse when data is structured, and analytics requirements are stable
2. Schema Design: Schema-On-Read vs Schema-On-Write
Schema-on-write (data warehouse) requires a structure to be defined before data enters. Every column and data type is specified upfront. Ingestion fails if incoming data does not conform. This enforces consistency but makes schema changes expensive. New columns require migration planning and development coordination.
Schema-on-read (data lake) accepts data without constraints and applies structure at query time. The same dataset can be queried with different schemas for different purposes.
- Schema-on-write: consistent, auditable, and easier to govern
- Schema-on-read: flexible and fast to ingest, but harder to trust at scale without tooling
3. Storage, Cost, and Scalability
Data lakes run on cloud data platforms and object storage, which costs a fraction of a cent per gigabyte per month. Scaling from terabytes to petabytes requires no architectural changes. There is no query engine bundled with the storage layer, which keeps the cost low but requires separate compute provisioning for analysis.
Data warehouses bundle, or separately meter, storage and compute. The per-terabyte cost is higher because data has been indexed and optimized for query performance.
- Data lakes can be 10 to 20 times cheaper per terabyte for raw storage
- The total cost of ownership for a lake rises quickly once engineering, governance, and computing are factored in
4. Performance and Query Optimization
Data warehouses are built for speed. Columnar storage, partitioning, materialized views, and query caching mean that complex aggregations across hundreds of millions of rows return results quickly, without engineering involvement for each query.
Whereas data lakes require more setup to reach comparable performance. Compute engines like Apache Spark, Presto, or AWS Athena must process and structure data before returning results. Without proper file formats (Parquet, ORC) and partitioning strategies, lake queries can be slow and expensive.
Open table formats like Apache Iceberg and Delta Lake are narrowing this gap, adding ACID semantics and SQL support directly to lake storage.
5. Data Governance and Quality Control
Warehouses have governance built in with schema enforcement, role-based access controls, and audit trails as part of the architecture. This makes compliance reporting and lineage documentation straightforward.
Data lakes, however, require external tooling for the same coverage. Without a metadata management layer and data catalog, users cannot discover what data exists or trace its lineage. Without data contracts and quality checks at ingestion, bad data enters and compounds downstream.
According to 2024 Gartner predictions, 80% of data and analytics governance initiatives will fail by 2027 due to a lack of organizational urgency. Data lakes face the highest risk of becoming ungoverned data swamps when governance is treated as an afterthought.
- Data catalog and lineage tracking
- Role-based access controls and audit logging
- Quality validation at ingestion
6. Users and Access Patterns
Data lakes are built for data engineers running ingestion pipelines and data scientists running model training and exploratory workloads. The access pattern is high-volume and varied, with large datasets pulled and transformed programmatically.
Data warehouses serve business analysts, finance teams, and executives querying through BI tools like Tableau, Power BI, or Looker. The access pattern is structured and frequent, with dashboards, scheduled reports, and KPI queries demanding consistent, fast results.
According to the 2024 Gartner Survey: Data and Analytics Operating Models, 61% of organizations are evolving their data and analytics operating models because of AI, reshaping how both lakes and warehouses are accessed and managed, and accelerating a shift toward data product thinking across analytics teams.
The structural differences above point directly to where each system belongs in practice.
When to Use a Data Lake vs a Data Warehouse?
The right system depends on a clear read of your data types, your user base, and your analytics goals.
In most enterprise environments, the answer involves both systems, and a working understanding of where each one fits makes the architectural conversation far more productive. The workload, the data, and the team doing the work determine which storage system belongs where.
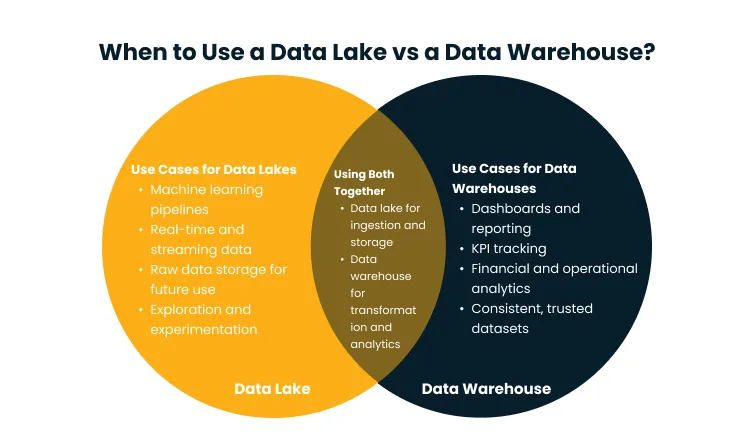
Use Cases for Data Lakes
Data lakes are the right call when the use case is not fully defined at ingestion time, and flexibility matters more than query speed.
Where they fit:
- Machine learning and AI model training: Raw, diverse datasets drive ML models. Lakes let you store everything without committing to a schema before model requirements are known.
- Real-time and streaming data: IoT sensors, clickstreams, and event feeds need a landing zone that absorbs velocity without transformation overhead.
- Raw data archiving: Storing historical data in its original format for compliance or future use is far more cost-effective in a lake than in a warehouse.
- Exploratory analytics: Data scientists can apply different schemas to the same raw data for different hypotheses, without restructuring the underlying dataset.
- Multi-format environments: When your data includes text, images, audio, or video alongside relational records, a lake handles it without structural enforcement.
Data lakes work best when strong engineering resources are in place for pipeline management and governance tooling.
Use Cases for Data Warehouses
Data warehouses are the right call when the analytics use case is well-defined, the data is structured, and consistency cannot be compromised.
Where they fit:
- Business intelligence and dashboards: Analysts and executives need fast, reliable results against clean data. Warehouses are purpose-built for this workload.
- Financial and operational reporting: Revenue, cost, and KPI data require auditability and consistency that schema-on-write enforces by design.
- KPI tracking at scale: High-frequency queries across large datasets, including daily sales and weekly operational trends, run efficiently against a warehouse built for those patterns.
- Shared governed datasets: When multiple teams query the same data, schema enforcement prevents quality drift that erodes trust in analytics.
- Regulatory compliance: Banking, healthcare, and insurance require lineage, access controls, and retention policies that warehouses support natively.
Data warehouses are clearly best suited for teams with stable analytics requirements and a mature data pipeline.
Hybrid Approach: Using Both Together
Most enterprise data teams use both, and the architectural question is really about how to connect them.
The standard pattern is layered. A data lake handles ingestion and raw storage while the data warehouse sits downstream, receiving cleaned and transformed data through an ETL or ELT pipeline.
This means that data engineers own the lake, and analysts own the warehouse. The boundary between them requires deliberate design, and it is where most of the engineering investment goes.
This layered model lets organizations:
- Preserve raw data in the lake for use cases not yet defined
- Serve clean, structured data from the warehouse for immediate analytics
- Iterate on transformation logic without losing original source data
- Scale storage and compute independently across both layers
The data lakehouse architecture takes this a step further. Open table formats like Apache Iceberg and Delta Lake bring SQL performance and ACID transactions directly to lake storage, reducing the need to maintain two entirely separate systems.
How does Modern Data Architecture Combine Data Lakes and Warehouses?
Modern data architecture treats the data lake and data warehouse not as competing systems but as complementary layers in a unified data ecosystem. The goal is not to pick one over the other but to define clear roles for each within an end-to-end data flow.
Here is how the layers typically fit together:
- Ingestion layer (data lake): All raw data from source systems, APIs, event streams, and third-party platforms lands in the lake. No transformation happens here. Data is preserved in its original format for full downstream flexibility.
- Transformation layer (ETL/ELT pipelines): Data engineering tooling (Apache Spark, dbt, AWS Glue) applies cleansing, validation, and business logic transformations. Output feeds the warehouse and analytics layers.
- Analytics layer (data warehouse): Curated, structured data is loaded into the warehouse for BI consumption, serving analysts and reporting tools that need fast, consistent query performance.
- Metadata, governance, and lineage layer: A data catalog and governance tool sits across both systems, tracking what data exists, where it came from, who can access it, and what transformations it has undergone.
- Data lakehouse layer: Open table formats like Apache Iceberg and Delta Lake are increasingly applied at the lake layer, enabling SQL queries and ACID semantics directly against lake data and blurring the traditional boundary between the two systems.
Data flows from ingestion to consumption through defined, governed pipelines, and both the lake and the warehouse play specific, non-interchangeable roles at their respective stages. The key design principle in modern data architecture is integration over replacement.
Designing this kind of integrated architecture requires deep familiarity with the trade-offs at each layer.
Data Engineering and Management services focused on pipeline development, maturity assessments, and strategic roadmap design help organizations build systems that combine governance, lineage tracking, and operational reliability across both storage environments.
Best Practices for Choosing the Right Data Storage Solution
Getting the storage architecture right is a strategic decision that belongs inside a broader data strategy. Here are the principles that consistent performers tend to follow:
- Evaluate your data types first: Map what you are storing before choosing a system. Unstructured or high-variety data points toward a lake. Structured, transactional data points toward a warehouse.
- Align the system to the use case: BI and reporting belong in a warehouse. ML training and exploratory analytics belong in a lake. Forcing one system to handle both creates performance and governance problems.
- Calculate total cost of ownership: Object storage is cheap, but lake operations add up. Factor in engineering time, governance tooling, and compute provisioning alongside the storage bill.
- Set up governance before you scale: Access controls, data catalogs, and quality checks are harder to retrofit than to design upfront. Treat them as architecture decisions from day one.
- Design the full data flow: Think end-to-end, from source to consumption. The transformation layer between the lake and the warehouse is where most of the value is created, and most of the mistakes are made.
- Decision framework:
- What types of data are you handling, and at what volume?
- Who are the primary users, and what tools do they use?
- Is your primary use case BI reporting, ML training, or both?
- What governance and compliance requirements apply?
- What engineering resources do you have to operate the system?
Most organizations find that the lake-versus-warehouse question resolves quickly once these questions are answered honestly. The architecture follows the workload, and the workload follows the team.
Getting the decision right at the outset is far less expensive than refactoring a storage layer after production traffic has arrived.
Conclusion
The gap between how data is stored and how it is actually used is where infrastructure costs balloon, governance breaks down, and analytics teams lose trust in their own numbers.
The next step is to map your workloads, identify where that gap exists today, and decide whether your current storage layer is built for where your data strategy is heading, rather than where it was two years ago.
If you work with Cygnet.One, here’s what that looks like in practice. The team starts with a data architecture assessment to examine your existing pipelines, storage layers, and governance gaps. From there, a custom roadmap is built to fit your workloads, whether that means building out lake ingestion, optimising your warehouse layer, or moving toward a unified lakehouse architecture.
Every engagement is scoped around your team’s actual use cases, not a generic blueprint.If your storage architecture is overdue for a second look, book a demo, walk through what the right architecture looks like for your data today.
A data lakehouse combines flexible lake storage with the performance and governance of a data warehouse. Open table formats like Apache Iceberg and Delta Lake enable SQL queries, ACID transactions, and schema enforcement directly on lake storage, making it possible to serve both data scientists and business analysts from a single system.
No. Data lakes store raw data efficiently and support ML workloads, but they lack the query speed, built-in governance, and consistency that business analysts need for BI and reporting. Most organizations run both in a complementary architecture, using the lake for ingestion and the warehouse for curated analytics.
ETL transforms data before loading it into the warehouse. ELT loads raw data first and transforms it inside the warehouse. Modern cloud warehouses favor ELT because cloud compute is elastic and in-warehouse transformation is faster and more flexible than external preprocessing.
Implement a data catalog to make data discoverable, apply access controls at the object-storage level, enforce quality checks before data lands in governed zones, and maintain lineage tracking from day one. Governance built into the ingestion layer prevents swamp conditions far better than retroactive cleanup.
Data lakes store raw data at much lower per-terabyte costs than warehouses. Total cost of ownership rises when you factor in engineering resources, governance tooling, and compute. Comparing only storage costs understates the full investment required for either system.
A data lake stores raw, unprocessed data in any format. A data warehouse stores cleaned, structured data optimized for analytics. A data mart is a subject-specific subset of a warehouse, focused on a single function like finance or sales, built for faster querying by a specific team.
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.