
































What if the number your Sales team is reporting is different from the one your Revenue Ops team pulled from the exact same source? It happens more often than most companies admit.
Data systems grow faster than the rules for using them. Pipelines pile up, teams build their own logic, and at some point, nobody can agree on a single number without a two-week investigation.
Here’s what that costs you: according to the 2026 Gartner Study on Data and Analytics Foundations for AI, companies whose AI programs actually work invest up to four times more in their data foundation, things like data quality, governance, and the people who manage it, than companies whose programs stall. The foundation is what everything else runs on.
This guide breaks down what that foundation looks like, what a data engineering framework is, why it matters, and how to build one that holds up as your data grows.
What is a data engineering framework?
A data engineering framework is a structured system that controls how data is collected, processed, stored, and delivered across an organization. Think of it as the plumbing that sits between your raw source systems: CRMs, databases, event streams, third-party APIs, and the tools your teams actually use to make decisions.
It runs across six layers: ingestion, storage, processing, orchestration, serving, and governance, each with a specific role in moving data from source to decision.
Without this structure, teams build their own pipelines in isolation, definitions drift, and the same metric shows different numbers on different dashboards. A data engineering framework fixes that by giving everyone a shared, consistent foundation to work from.
Why a data engineering framework is important
Without a framework, every team builds its own data flows, pipelines get rebuilt from scratch for every new use case, and nobody can agree on a single number without a two-week investigation. The five outcomes below are what change when you put a proper framework in place.
Enables consistent data across systems
Marketing’s “active customer” is not the same as Finance’s. Sales pulls a pipeline number that doesn’t match what Revenue Ops reported. These aren’t data errors; they’re definition errors, and they happen when there’s no shared structure governing how metrics are calculated.
A framework standardizes how data is collected, how transformations are applied, and how shared metrics are defined. One canonical model. One number per metric, regardless of which tool or team is asking.
Improves reliability and trust in data
Pipelines built in isolation accumulate silent failure modes. A field changes upstream, nothing breaks visibly, and three weeks later, a leader makes a call based on wrong data.
A framework introduces validation, testing, and lineage tracking at every stage, so issues surface in the pipeline, not in the boardroom. According to the 2025 IBM Institute for Business Value Study on Data Quality, over a quarter of organizations lose more than $5 million a year to poor data quality, with 7% reporting losses above $25 million.
Supports scalability as data grows
Data volumes don’t scale evenly. Some sources double in a year, others stay flat, and a few explode overnight when the business ships a new product. A fragmented stack breaks when that happens. A layered framework doesn’t, because each layer scales, gets replaced, or gets upgraded independently.
The ingestion layer can move from batch to streaming without touching storage. The processing layer can adopt a new engine without disrupting consumption. Frameworks scale by being modular, not by being bigger.
Reduces manual effort and operational complexity
In fragmented data environments, engineering teams spend most of their time on pipeline maintenance, manual reconciliation, and one-off data requests. That’s the default when there’s no shared infrastructure to rely on.
A framework automates the repetitive work, ingestion scheduling, validation, dependency management, and failure recovery, and frees up engineering capacity for building new use cases instead of keeping existing ones alive.
Enables advanced analytics and real-time use cases
Most advanced analytics projects don’t fail because the model is wrong. They fail because the data feeding the model is inconsistent, ungoverned, or arriving too late.
Machine learning, real-time decisioning, and embedded analytics all need structured, low-latency, trustworthy data to function. A framework creates that foundation. Without it, every AI use case starts with a custom data engineering project, and most stall before they reach production.
Core components of a data engineering framework
A data engineering framework is built as a layered architecture where each layer has one job. Together, they move data from raw source systems to business-ready outputs in a way that is controlled, observable, and scalable.
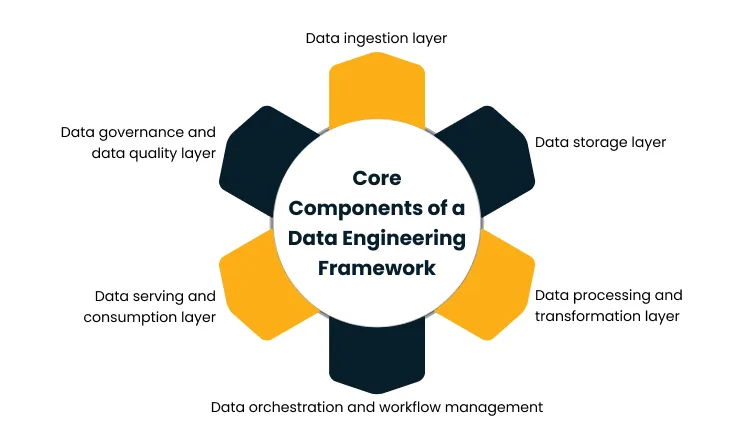
Data ingestion layer
This is where data enters the framework. The ingestion layer connects to source systems, databases, APIs, SaaS applications, and event streams and pulls data in either on a schedule or as it arrives in real time. A well-built ingestion layer also handles schema changes gracefully, so when an upstream system changes a field name or data type, the pipeline doesn’t break silently and corrupt everything downstream.
- Apache Kafka and Amazon Kinesis for high-throughput real-time event ingestion
- AWS Glue, Azure Data Factory, and GCP Dataflow for managed batch and streaming pipelines
- Debezium or Fivetran for replicating database changes without full reloads
Data storage layer
Once data is ingested, it needs a place to live before it reaches consumers. The storage layer keeps raw data in its original form for reproducibility and curated data in a cleaned, modeled form that teams can query directly. The right choice depends on three things: how structured your data is, how fast consumers need it, and what it costs to store and query at your volume.
- Data lakes on S3, ADLS, or GCS for raw and unstructured data at low cost
- Cloud warehouses like Snowflake, BigQuery, or Redshift for high-performance analytical queries
- Lakehouse architectures like Databricks Delta Lake or Apache Iceberg, when you need both flexibility and warehouse-class performance in the same system
Data processing and transformation layer
Raw data is rarely ready to use. This layer cleans records, standardizes formats, joins data across sources, applies business rules, and produces the aggregates that analytics and ML models consume. The two dominant approaches are batch transformation for large volumes processed on a schedule, and stream processing for use cases where data needs to be ready in seconds, not hours.
- Apache Spark and Databricks for large-scale batch and streaming workloads
- dbt (data build tools) for SQL-based transformation modeling directly inside the warehouse
- Apache Flink for low-latency stream processing where milliseconds matter
Data orchestration and workflow management
Pipelines don’t run themselves. This layer decides what runs, when, in what order, and what happens when something fails. It manages dependencies between pipelines, retries on transient failures, alerts on persistent ones, and keeps a run history that engineers can use to debug and improve over time. Without it, pipelines depend on cron jobs and manual coordination, which works until it doesn’t, and when it stops working, it usually fails without warning.
- Apache Airflow for code-first orchestration of complex pipeline dependencies
- Azure Data Factory and AWS Step Functions for managed cloud-native orchestration
- Dagster or Prefect for teams that want stronger observability and data-aware scheduling built in
Data serving and consumption layer
This is where curated data reaches the business. The serving layer delivers data through the right interface for each consumer, optimized queries for BI tools, low-latency APIs for product features, and feature stores for ML models running in production. A data scientist and a BI analyst need the same underlying data delivered in completely different ways, and this layer is what makes that possible.
- Semantic layers like dbt Metrics or Looker for consistent business definitions across BI tools
- REST and GraphQL APIs for application and product integration
- Online feature stores like Feast or Tecton for real-time ML serving
Data governance and data quality layer
Governance sits across every layer, not just at the end. It covers data quality validation, access control, cataloging, lineage tracking, and compliance with regulations like GDPR or HIPAA. A framework without governance can still move data, but the data it moves is hard to trust, hard to discover, and hard to defend when an auditor asks where a number came from.
- Collibra and Alation for enterprise data cataloging and governance
- Apache Atlas for open-source lineage tracking
- Great Expectations or dbt tests for automated data quality validation inside pipelines
Architectural patterns in modern data engineering frameworks
Architectural patterns in a data engineering framework are the structural decisions that define how data moves, transforms, and gets stored across your systems. Modern frameworks are built around three core patterns: batch vs real-time processing, transformation approach, and storage model- and getting them right early saves significant rework later.
Batch processing and real-time data flows.
Batch processing handles data at scheduled intervals, like hourly, daily, or in larger windows. It fits use cases where data doesn’t need to be fresh by the minute, like financial reporting, regulatory submissions, and historical analysis. It’s also significantly cheaper to run at scale because it uses compute only when needed.
Real-time data flows process events continuously as they arrive, with end-to-end latency measured in seconds or milliseconds. This fits use cases where decisions have to happen at the moment of interaction: fraud detection, live personalization, Internet of Things (IoT) monitoring, and operational alerts.
Most modern frameworks run both from a unified architecture, where the same source data feeds batch pipelines for historical analysis and streaming pipelines for real-time decisions simultaneously, without duplicating pipelines or storage.
Data transformation approaches in pipelines.
Extract, Transform, Load (ETL) transforms data before it enters the storage layer. This works well when target schemas are stable, but if a business definition changes, you often have to reload data from scratch.
Extract, Load, Transform (ELT) loads raw data into storage first and transforms it inside the warehouse or lakehouse. This gives teams the flexibility to change transformation logic without going back to the source, which matters in environments where business definitions evolve frequently.
Most modern frameworks favor ELT for analytical workloads, supplemented by streaming transformations for use cases where data needs to be shaped in motion, not after it lands.
Data storage models in modern architectures
Data warehouses store structured, pre-modeled data optimized for fast analytical queries, best suited for Business Intelligence (BI) reporting where consistency and query performance matter most.
Data lakes store raw, semi-structured, and unstructured data at low cost, built for exploration, Machine Learning (ML) training, and long-term retention where flexibility matters more than speed.
Lakehouse architectures combine both; raw data sits in open file formats on object storage with warehouse-class query engines on top, giving one storage layer that serves BI, ML, and operational analytics without moving data between systems.
How To Implement A Data Engineering Framework
Building a data engineering framework is not a one-time project. It is a sequence of decisions where each step creates the conditions that make the next one work. Skipping steps or doing them out of order is the most common reason implementations stall halfway through.
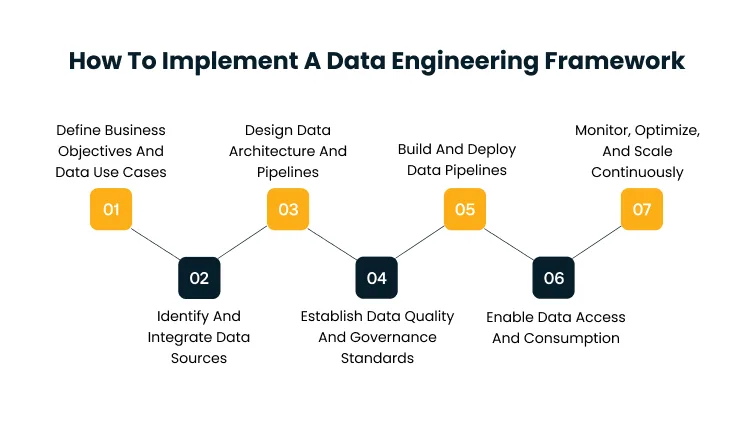
Define Business Objectives And Data Use Cases
Start with the decisions the framework needs to support, not the technology it will use. Which business outcomes depend on reliable data? Which AI initiatives are waiting on a data foundation to move forward?
Without this anchoring, frameworks get over-engineered for hypothetical use cases and under-engineered for real ones. Define a short list of priority use cases, each with a measurable outcome, a named owner, and a timeline. Everything built after this point serves those use cases first.
Identify And Integrate Data Sources
Map every source system that feeds the priority use cases, operational applications, transactional databases, third-party APIs, event streams, and external data providers. For each source, document the volume, format, update frequency, ownership, and access restrictions.
Most organizations discover at this step that critical sources are undocumented, inaccessible, or owned by teams that have never been asked for data access before. Resolve those gaps here, before they surface mid-build.
Design Data Architecture And Pipelines
With sources mapped and use cases prioritized, design the layered architecture that moves data from source to consumption. Cover ingestion patterns, storage choices, transformation logic, orchestration topology, and how data reaches consumers.
Each layer should be replaceable independently, so upgrading the processing engine doesn’t require rebuilding storage, and adding a new source doesn’t break existing pipelines.
Establish Data Quality And Governance Standards
Quality and governance need to be built into the framework from the start, not added after the first audit. This step covers:
- Validation rules at ingestion so that bad data is caught before it moves downstream
- Quality Service Level Agreements (SLAs) per dataset, so consumers know what freshness and accuracy to expect
- Access control policies defining who can read, write, and modify each dataset
- Lineage tracking so every number can be traced back to its source
- Sensitive data classification to meet compliance requirements like General Data Protection Regulation (GDPR) or Health Insurance Portability and Accountability Act (HIPAA)
Build And Deploy Data Pipelines
Pipeline development is where the architecture becomes a working system. The discipline at this step is to build pipelines that are observable, recoverable, and testable from day one rather than retrofitting those properties later. Modern data engineering treats pipelines as software, with version control, code review, automated testing, and CI/CD deployment.
Cygnet.One’s Data Migration and Modernization practice supports this stage with a structured framework covering legacy assessment, secure data extraction, cleansing and staging, cloud migration with redundant backups and checksum validation, and pre-built accelerators including an ETL Automation Framework and Metadata and Governance Toolkit, so pipelines launch with the operational maturity that production environments require.
Enable Data Access And Consumption
Curated data has to reach consumers through the right interface for each use case. Business Intelligence (BI) users need optimized query performance. Application developers need APIs with predictable latency. Data scientists need notebook access and feature stores.
Design each access pattern deliberately rather than leaving it to whoever requests it first. Document which datasets are available, through which interfaces, at what SLAs, and how consumers can access data without filing an engineering ticket every time.
Monitor, Optimize, And Scale Continuously
A framework is a living system, not a one-time delivery. Track pipeline health, monitor data quality KPIs, optimize cost as workloads shift, and scale capacity before growth causes failures rather than after.
Teams that get this right treat the framework as a product with a roadmap. Regular reviews of pipeline performance, cost, and consumer usage drive decisions about what to refactor, deprecate, or expand, based on actual data, not assumptions.
Common challenges in data engineering frameworks
Even well-planned frameworks run into predictable problems during implementation. According to a 2025 Gartner Press Release on AI-Ready Data, through 2026, organizations will abandon 60% of AI projects due to poor data quality, a direct consequence of the challenges below being underestimated at design time.
Data Integration Complexity
Source systems were built at different times, by different teams, with different schemas and data models. Combining them into a unified model requires semantic alignment and a process for resolving conflicts when the same customer, product, or transaction appears differently across systems.
The cost only becomes visible after the first integration is complete and the second one starts revealing the inconsistencies.
- Define a canonical data model for shared entities before writing pipelines
- Build conflict resolution rules into governance before integrations go live
- Start with a data inventory so nothing critical gets missed during source mapping
Data Quality And Consistency Issues
Poor source data does not improve as it moves through a pipeline. Inconsistent labels, missing values, and duplicate records surface as quality defects in the curated layer — often weeks after the underlying issue occurred upstream.
Engineering quality validation into ingestion from the start is significantly cheaper than finding and fixing defects after they reach a dashboard.
- Validate data at ingestion before it enters the storage layer
- Set quality thresholds per dataset and alert when data falls below them
- Assign a named owner to each data domain accountable for source quality
Pipeline Reliability And Maintenance
Pipelines that worked at launch do not stay working without active maintenance. Source schemas change, data volumes shift, and undocumented dependencies accumulate until a silent failure corrupts downstream data, often without anyone noticing until a leader questions a number in a meeting.
Reliability requires investment in observability and automated recovery from day one, not after the first production incident.
- Instrument every pipeline with monitoring and alerting from the start
- Document dependencies explicitly so upstream schema changes don’t cause silent failures
- Build automated recovery for transient failures so engineers aren’t pulled in for issues that the system can fix itself
Scalability And Cost Management
In cloud environments, consumption scales without procurement gates. Inefficient queries, oversized clusters, and unmanaged storage growth produce bills that catch finance teams off guard, especially when data volumes spike unexpectedly after a product launch or a new data source comes online.
Managing cost requires treating it as a tracked Key Performance Indicator (KPI) from day one, not a year-end discovery.
- Use columnar formats like Parquet to reduce storage and query costs
- Partition datasets by date or key attributes to avoid full table scans
- Review compute, and storage spend monthly, not quarterly
Alignment Between Technical And Business Teams
The most expensive failure mode is curated datasets sitting unused while teams build shadow pipelines to answer the questions they actually have. It happens when engineering builds what seems technically correct without enough input from the people who will actually use the data.
The fix is structural; business priorities need to drive the engineering backlog, not the other way around.
- Assign a business owner to every data domain, not just a technical one
- Run quarterly reviews of dataset usage to identify what is being used and what is not
- Include business stakeholders in pipeline prioritization, not just requirements gathering
Conclusion
A data engineering framework is the foundation that makes everything above it work — Business Intelligence (BI), advanced analytics, machine learning, and real-time decisioning. Enterprises that invest in it deliberately, sequence the components correctly, and engineer governance in from the start are the ones that get consistent returns from their analytics and AI investments.
The next phase of enterprise data work will be defined by how well organizations connect their frameworks to the AI use cases growing above them. A framework built for batch reporting will not support real-time personalization. A framework built for tabular analytics will not support generative AI.
The decision worth making now is what your framework needs to support in three years. Book a demo with our team to walk through how we design and deliver enterprise data foundations from architecture through production.
FAQs
A data engineering framework is a structured system that defines how data is collected, processed, stored, and delivered across an organization. It connects ingestion, storage, processing, orchestration, serving, and governance into a unified architecture that moves data from raw source systems to business-ready outputs reliably and at scale.
A data engineering framework is built on six layers: ingestion for collecting data from sources, storage for retaining raw and curated data, processing and transformation for converting raw data into business-ready forms, orchestration for managing pipeline dependencies and schedules, serving for delivering data to consumers, and governance for enforcing quality and access standards across the stack.
Extract, Transform, Load (ETL) transforms data before it enters storage, which works well for stable schemas. Extract, Load, Transform (ELT) loads raw data first and transforms it inside the warehouse, giving teams flexibility to change business logic without reloading source data. Modern frameworks favor ELT for analytical workloads.
Generative AI models require clean, governed, and consistently structured data to produce reliable outputs. A data engineering framework ensures data is ingested, validated, and delivered in a format AI models can consume, making it the foundational layer that determines whether generative AI initiatives reach production or stall.
A company should invest in a data engineering framework when different teams report conflicting numbers, when engineers spend more time fixing pipelines than building new capabilities, or when AI and analytics initiatives are stalling because the underlying data is unreliable, ungoverned, or inconsistent across systems.
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.