
































Cloud budgets are growing, observability tooling has never been more mature, and engineering teams are larger than they were five years ago. Yet, most enterprise teams still default to vertical or horizontal resource additions the moment something slows down. More compute. Bigger nodes. Another replica. The bill goes up. The problem stays.
That instinct is expensive — and increasingly, it is wrong.
Cloud performance engineering is the discipline of treating performance as an engineering problem, supported by cloud engineering services, not a procurement one. It asks: why is this workload behaving the way it is, before asking how much more to throw at it. The distinction sounds minor. The outcomes are not.
This post works through the full arc of cloud performance engineering — from identifying where performance actually breaks, to the tuning techniques that matter, to building a monitoring practice that surfaces problems before users do.
The Performance Challenge Nobody Talks About Honestly
Here is something that rarely makes it into vendor decks: idle and over-provisioned resources typically account for 20–30% of cloud spend in most organizations. Optimization and automation, when applied thoughtfully, can reduce cloud costs by 20–35%. That is a budget line that could fund an entire engineering team.
The problem is not awareness. It is the absence of a structured approach to workload optimization in the cloud. Most organizations treat cloud performance reactively — they wait for an alert, add more resources, and close the ticket. The performance debt compounds.
Cloud environments today are not simple. Hybrid cloud is operational reality, not aspiration. A single application might span on-premises infrastructure, multiple cloud regions, and edge nodes simultaneously. The old mental model does not map to this world.
Add AI and ML workloads into the mix. These now account for 22% of cloud costs across enterprises, with resource consumption patterns that are non-linear. Standard capacity planning models were not built for this. You cannot look at historical utilization curves and reliably forecast GPU memory demand during a model inference burst — and that is precisely the kind of problem cloud performance engineering is built to address.
Identifying Cloud Performance Bottlenecks Before They Find You
A bottleneck is not always where it appears to be. That is the first and most important truth in cloud performance bottleneck analysis.
Slow API response times often get blamed on compute. The real culprit might be an unindexed database query that executes cleanly under light load and collapses under concurrent requests. Latency spikes in a microservices architecture frequently trace back to synchronous inter-service calls — a code design decision, not an infrastructure limitation.
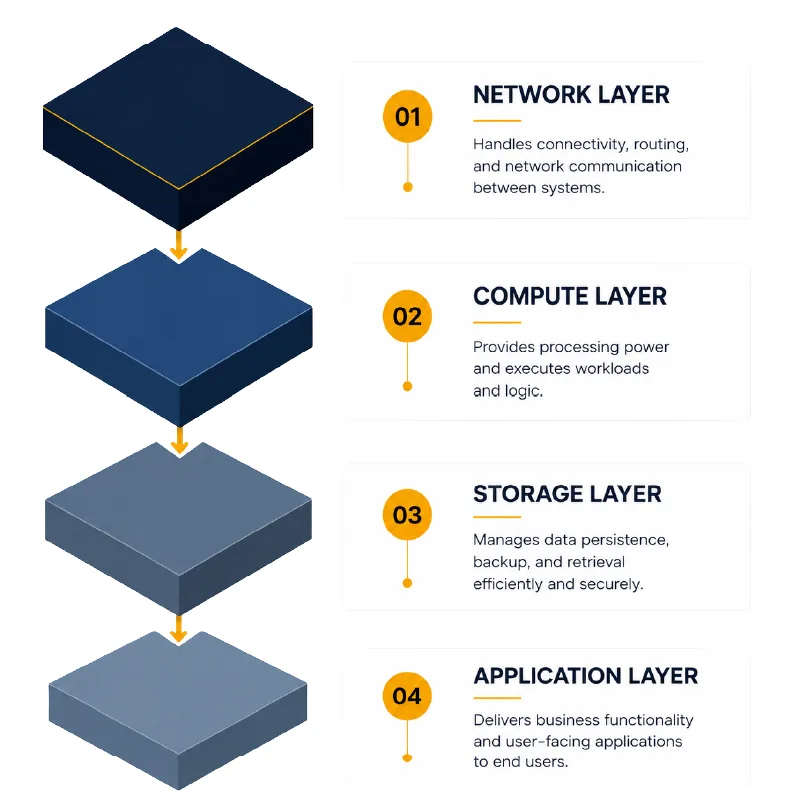
Cloud performance bottleneck analysis works across four layers, and each one requires a different diagnostic lens:
| Bottleneck Layer | Common Symptoms | Root Cause Examples |
| Network | High latency, packet loss, slow cross-region calls | Poor placement decisions, egress routing, over-reliance on single AZ |
| Compute | CPU throttling, long queue times | Over-committed nodes, noisy neighbor effects in shared tenancy |
| Storage/Database | Slow reads/writes, I/O wait | N+1 query patterns, missing indexes, wrong storage tier selection |
| Application Code | Memory leaks, thread contention, GC pauses | Inefficient algorithms, blocking calls in async contexts |
The challenge with cloud performance bottleneck analysis in distributed systems is that a symptom at layer 4 often has a cause at layer 2. A garbage collection pause in the application layer can look like a network timeout from the outside. A noisy neighbor at the compute layer can surface as database connection pool exhaustion.
You cannot fix what you cannot correctly locate.
Infrastructure Tuning vs. Application-Level Performance: Where Teams Get It Wrong
This is the debate that costs organizations the most time and money. Application vs. infrastructure performance in the cloud is not an either/or question, but many teams treat it that way.
Infrastructure teams tune the platform. Application teams tune the code. Neither fully owns the intersection — and that intersection is usually where the actual problem lives.
Infrastructure-level cloud performance tuning addresses:
- Instance family selection aligned to workload type
- Storage tier alignment — SSD-backed volumes for transaction-heavy databases, not object storage
- Network topology — placing tightly coupled services in the same availability zone to reduce cross-zone latency
- Container resource limits in Kubernetes — appropriate CPU and memory requests/limits to avoid throttling
- Reserved and spot instance strategies for predictable vs. interruptible workloads
Application-level cloud performance tuning, however, is where the highest ROI often hides:
- Query optimization and indexing strategies matched to access patterns
- Caching layer design — deciding what to cache, when to invalidate, and how long to retain
- Asynchronous processing for workloads that do not require synchronous completion
- Connection pooling configuration — a misconfigured pool size causes cascading failures that no amount of added compute resolves
- Payload compression and serialization format choices for high-throughput APIs
Optimizing cloud workloads for enterprise environments means treating the application and its infrastructure as a single system with shared performance characteristics, not separate concerns with separate owners.
Workload Optimization in the Cloud: Techniques That Actually Move the Needle
Workload optimization in the cloud is not a one-time project. It is an ongoing engineering practice. Effective workload optimization requires choosing the right resource for the right job, then tuning each layer against actual usage patterns. Here are the approaches that consistently deliver results:
Workload-Aware Instance Selection
Not all compute is equal. Running a memory-intensive Java application on a compute-optimized instance because it was cheaper per vCPU is a false economy — the JVM garbage collector will spend more time fighting for memory headroom than doing useful work. Matching instance families to workload characteristics — memory-optimized for in-memory databases, compute-optimized for CPU-bound processing, GPU instances for inference tasks — is foundational cloud performance tuning.
Right-Sizing Over Guessing
Teams over-provision out of caution. Industry data consistently shows that 30% or more of cloud instances in a typical enterprise environment are running at a fraction of their allocated capacity. The approach to fixing this is analytical: use P95 and P99 utilization over 30 days, not averages. Average conceals variance. Headroom decisions should be driven by peak patterns. Native tools like AWS Cost Explorer and Azure Cost Management surface these patterns — and acting on them is straightforward cloud performance tuning that requires discipline, not complexity.
Intelligent Caching Architecture
Caching is a hierarchy — CDN for static assets, application-level caching for frequently read data, database query result caching for expensive aggregations. Teams that implement caching as a single Redis cluster without thinking through invalidation strategy often serve stale data while paying for both the cache and the database hits. Smart workload optimization in the cloud accounts for caching strategy at design time.
Asynchronous Processing Pipelines
Synchronous request-response belongs where immediate feedback is expected — user-facing interactions, payment confirmations, login flows. For everything else — sending emails, generating reports, processing images, updating analytics — asynchronous queues reduce caller latency, distribute load more evenly, and absorb traffic spikes. This is application-level workload optimization in the cloud that pays dividends immediately.
Horizontal Pod Autoscaling with Custom Metrics
Standard Kubernetes HPA reacts to CPU and memory. But the real load signal for many workloads is queue depth, request rate, or a business metric. Scaling a payment processing service on transaction queue length — not CPU — means the system responds to actual demand. This level of cloud performance tuning requires understanding a workload’s semantics, not just its resource consumption.
Cloud Performance Monitoring Tools: Choosing What You Actually Need
The cloud performance monitoring tools market is crowded, and the choice matters. The three dominant platforms — Datadog, Dynatrace, and New Relic — each represent a different philosophy.
| Tool | Strength | Best Fit | Pricing Model |
| Datadog | Broad integrations (500+), multi-cloud visibility, strong dashboarding | Agile teams with diverse tech stacks, cloud-native environments | Modular, per-component — costs can escalate |
| Dynatrace | Automated root cause analysis, full-stack auto-discovery, AI-driven anomaly detection | Large enterprises with complex systems needing automation | Per-host pricing, higher upfront cost |
| New Relic | Application-centric monitoring, developer-friendly UX, NRQL querying | Dev teams prioritizing application performance and custom analytics | Consumption-based (per user + per GB ingested) |
The wrong question is “which tool is best?” The right question is “what visibility gap is costing us the most right now?”
A Kubernetes-first SaaS organization reduced mean time to resolution by 30–50% after centralizing APM in Datadog with synthetic checks and sampled tracing. A global enterprise deployed Dynatrace OneAgent across thousands of hosts and achieved near-instant detection of a misbehaving middleware process — what would have been hundreds of individual alerts collapsed into a single, correctly identified root cause. These are not product success stories; they are illustrations of what structured cloud performance engineering produces when monitoring is treated as signal, not decoration.
Open-source alternatives like the Prometheus + Grafana stack with OpenTelemetry instrumentation offer cost advantages and avoid vendor lock-in, at the cost of more engineering overhead. For teams with strong platform engineering capability, that trade-off is often worthwhile.
The principle across all cloud performance monitoring tools is the same: you need three signal types working together.
- Metrics — CPU, memory, request rate, error rate, latency percentiles
- Logs — structured, searchable, correlated with trace IDs
- Traces — distributed tracing across service boundaries to follow a request end-to-end
Observability without all three is guesswork with a dashboard on top.
Optimizing Cloud Workloads for Enterprise: The Continuous Improvement Model
Optimizing cloud workloads in enterprise environments is not a project with a start and end date. It is a system. Peak traffic this quarter looks different from next quarter. New features change access patterns. AI workload adoption changes compute profiles entirely.
The organizations doing this well operate on a continuous loop:
- Baseline — Establish performance baselines under normal conditions. This is where cloud performance tuning begins — not at the point of failure, but well before it.
- Profile — During load testing and in production, use profiling tools to find which functions, queries, and calls consume the most time and resource. Fix the top offenders first.
- Change — Implement targeted changes, one variable at a time. Each change is an act of deliberate workload optimization in the cloud, not reactive firefighting.
- Measure — Validate that the change produced the expected improvement. Optimization in one layer can create a new bottleneck in another.
- Repeat — This is part of the sprint cadence. Cloud performance tuning embedded in the delivery cycle compounds — small, consistent improvements outperform periodic heroics.
Cloud performance engineering done well also embeds performance criteria into the software development lifecycle — not as a gate at deployment, but as a design consideration. The application vs. infrastructure performance divide in the cloud becomes irrelevant when both layers are designed with the same performance intent. A choice to use synchronous HTTP between two services creates a latency dependency. Storing session data in a relational database instead of an in-memory cache creates a read bottleneck under load. These are deliberate decisions, not discovered problems.
The maturity inflection point for most enterprise engineering organizations is when they stop treating performance issues as incidents and start treating them as cloud engineering design signals.
What This Means in Practice
Cloud performance engineering is a discipline that requires three things most organizations underinvest in: cross-functional ownership between application and infrastructure teams, observability that spans both layers, and a process for acting on what monitoring surfaces.
The tools exist. The techniques are well understood. The gap is usually organizational — who owns the problem when it sits at the boundary between application code and cloud infrastructure. Teams that treat workload optimization as a shared engineering responsibility, not a departmental one, are the ones that extract more performance from the same spend.
Author


Yogita Jain
Content Lead
Yogita Jain leads with storytelling and Insightful content that connects with the audiences. She’s the voice behind the brand’s digital presence, translating complex tech like cloud modernization and enterprise AI into narratives that spark interest and drive action. With a diverse of experience across IT and digital transformation, Yogita blends strategic thinking with editorial craft, shaping content that’s sharp, relevant, and grounded in real business outcomes. At Cygnet, she’s not just building content pipelines; she’s building conversations that matter to clients, partners, and decision-makers alike.