
































In enterprises, data rarely sits still anymore within modern data engineering services environments. It moves across systems, gets reshaped multiple times, and eventually lands in places where decisions are made. Most teams are aware of this flow, yet fewer have clear visibility into how that flow behaves at every stage. That gap is exactly where data observability starts to matter.
In fact, there is a reason data observability keeps coming up in data conversations. Barr Moses, Co-founder of Monte Carlo, once said, “Data downtime is the new system downtime.” When data stops behaving the way, it should, the impact is not limited to engineers. It shows up in reports, in forecasts, and sometimes in decisions that need to be made quickly.
That change has raised expectations quietly. Pipelines built on modern data analytics services are no longer judged only by whether they run. They are judged by whether the data they produce can actually be trusted. Once that expectation sets in, teams begin to notice how little visibility they really have into pipeline health.
To see why this happens, it helps to step back and look at how pipelines have changed.
What challenges do modern data pipelines create for enterprises?
Pipelines used to be easier to reason for. They ran within a smaller set of systems, and the number of dependencies was limited. That is no longer the case. Today, a single pipeline may depend on several sources, each with its own behavior.
What makes this harder is that issues do not always appear where they begin. A delay in one system might only become visible much later, and by then the original cause can be difficult to trace. Teams often find themselves working backwards through layers just to understand what has changed.
Some patterns tend to show up repeatedly:
- Data arrives later than expected, even when jobs complete successfully
- Output looks slightly different, which raises doubts about accuracy
- Dependencies behave inconsistently across environments
None of these issues are dramatic on their own. What makes it difficult is how subtle they are. This is where teams handling data pipelines begin to feel the strain. They can see that something is off, yet they do not always have enough context to explain why.
That lack of clarity becomes more obvious as pipelines grow. At some point, teams start questioning whether monitoring alone is enough.
Why is traditional monitoring not enough for modern data systems?
Monitoring does its job well, yet it was never designed to answer every question. It tells you whether something ran, and it alerts you when something fails. For infrastructure, that is often enough.
Data introduces different kinds of problems. A pipeline can run without errors and still produce results that are incomplete or inconsistent. When that happens, monitoring tools stay quiet. From a system perspective, everything looks fine.
That disconnect is where the frustration begins.
| What Monitoring Shows | What Observability Reveals |
| Jobs completed successfully | Data arrived late or changed shape |
| Systems remained available | Data behavior shifted unexpectedly |
| No errors detected | Root causes become visible |
Teams responsible for monitoring data pipelines often reach this point during troubleshooting. They check logs, verify execution, and still cannot explain why the output does not look right. The problem is not that monitoring failed. It answered a different question.
This is usually where data observability enters the picture.
How does data observability improve pipeline health and reliability?
Observability changes the focus slightly, yet the impact is noticeable. Instead of asking whether a pipeline ran, it asks how the data behaved while it was running. That small shift opens up a different level of visibility.
Once observability is in place, patterns begin to surface. Data might arrive later than usual. Volumes might fluctuate without an obvious reason. Fields might change in subtle ways that would otherwise go unnoticed.
These signals do not always indicate failure. They often indicate drift, which can be just as important.
- A delay upstream becomes visible before it affects reporting
- A structural change appears during processing, not after
- A sudden variation stands out instead of blending in
This does not eliminate complexity, yet it makes it easier to navigate. Teams spend less time guessing and more time confirming what is actually happening. Over time, that clarity builds confidence.
When organizations adopt data observability, they begin to see their pipelines less as black boxes and more as systems they can understand.
That understanding starts to change how pipelines are managed day to day.
How are enterprises using observability to improve data pipeline monitoring?
The biggest shift is subtle. Teams stop waiting for something to break. Instead, they start paying attention to how things behave while they are still working.
This changes how data pipeline monitoring is approached. Alerts are no longer the only signal. Behavior itself becomes a signal.
| Before Observability | After Observability |
| Issues appear in reports first | Signals appear earlier in pipelines |
| Investigations start without context | Investigations start with direction |
| Resolution takes longer | Resolution becomes more focused |
Teams working on monitoring data pipelines often describe this as having a starting point. Instead of searching across systems, they already have a sense of where to look.
That does not remove the need for expertise. It simply makes that expertise more effective.
As this approach becomes more common, organizations begin to rely on tools that support it.
What role do data reliability tools play in modern data platforms?
As pipelines grow, manual visibility becomes harder to maintain without strong data engineering practices. This is where data reliability tools begin to play a role. They add a layer to existing systems that focuses on how data behaves across them.
Teams often bring in specialized platforms to support this visibility. Some commonly used tools include:
- Monte Carlo
- Databand
- Bigeye
- Acceldata
These tools help track lineage, which shows how data moves through each stage. They also highlight changes that might otherwise go unnoticed. Over time, this creates a clearer picture of how pipelines are connected.
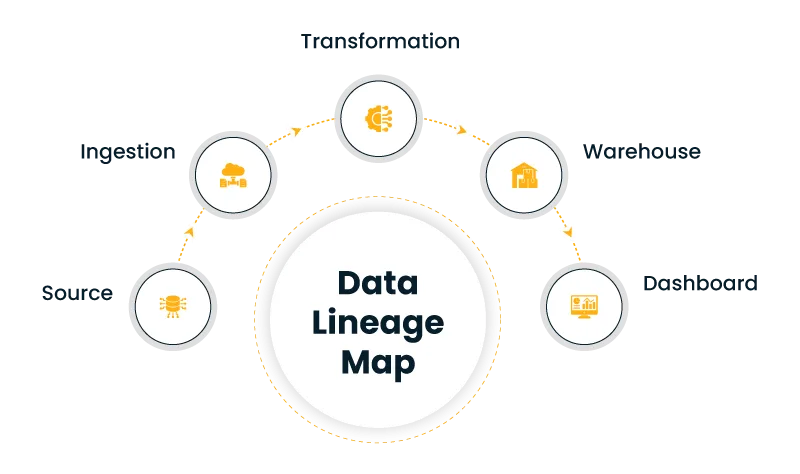
This is what enables observability in data platforms to extend beyond individual tools. Instead of looking at isolated pieces, teams can follow the full journey of data.
That shared visibility tends to reduce confusion during incidents. It also makes collaboration easier, since everyone is looking at the same context.
Once this becomes part of daily work, the way teams operate begins to shift.
How does data observability change the way data teams operate?
The change is gradual, yet noticeable. Troubleshooting does not disappear, yet it becomes less chaotic. Teams start with better context, which shortens the path to resolution.
At the same time, conversations become clearer. When something goes wrong, teams can explain what changed instead of describing symptoms. This reduces back and forth, especially between technical and business teams.
Some outcomes tend to emerge naturally:
- Less time is spent searching for causes
- Data outputs feel more consistent and reliable
- Decisions are made with fewer doubts about accuracy
These changes build over time. As confidence grows, data observability becomes part of how systems are designed from the beginning. It is no longer an add-on. It becomes part of the foundation.
That foundation matters even more when looking ahead.
What does the future of data observability look like for enterprises?
Data systems are not getting simpler. They are expanding, and with that expansion comes more complexity. Visibility will need to keep up.
Future developments are likely to focus on recognizing patterns earlier. Signals that indicate change will become easier to detect. Some of that detection will happen automatically, which reduces the need for constant manual oversight.
At the same time, observability will move closer to business use. Reliable data will directly support planning and forecasting. This will make data observability relevant beyond engineering teams.
Organizations that invest in visibility now are building something more than technical capability. They are building confidence in the data they depend on.
FAQs
What is data observability in simple terms?
It is the ability to understand how data behaves as it moves through pipelines.
How is it different from monitoring?
Monitoring shows execution, while observability explains behavior.
Why is data pipeline monitoring important?
It ensures that data reaches its destination correctly and supports reliable decisions.
What tools support data observability?
Tools provide lineage tracking, anomaly detection, and visibility into data flow.
How does observability improve reliability?
It helps identify issues early and explains their causes, which reduces disruption.
Author


Yogita Jain
Content Lead
Yogita Jain leads with storytelling and Insightful content that connects with the audiences. She’s the voice behind the brand’s digital presence, translating complex tech like cloud modernization and enterprise AI into narratives that spark interest and drive action. With a diverse of experience across IT and digital transformation, Yogita blends strategic thinking with editorial craft, shaping content that’s sharp, relevant, and grounded in real business outcomes. At Cygnet, she’s not just building content pipelines; she’s building conversations that matter to clients, partners, and decision-makers alike.