































If your “daily batch” finishes at 9 a.m., your business has been living nine hours in the past.
Legacy data platforms were built around predictability. Files land at night, jobs run in order, reports refresh in the morning, and “yesterday” feels acceptable. Then fraud shifts in minutes, deliveries change by the hour, and customers expect instant status. Batch starts to look less like stability and more like delay.
This post is a practical guide to turning file-driven chains into event-driven flows on AWS using modern AWS migration and modernization patterns that reduce latency and operational risk. It is written for architects, data engineers, and platform owners who are tired of brittle nightly runs and want a safer path to continuously updated data.
You will see AWS real-time pipelines and streaming modernization called out directly, grounded in proven AWS migration success patterns used in production environments, but the focus stays on design choices that hold up in production.
A unique USP in this approach is the “two-lane” design:
- Lane 1: continuous events for fast decisions
- Lane 2: controlled backfill for corrections and late data
Most real-time attempts fail because they ignore lane 2. Reality always sends late records, replays, and fixes.
Data modernization fundamentals
Batch workloads hide three assumptions:
- data arrives in complete, ordered files
- compute can run for hours without affecting anyone
- reruns are fine when something breaks
Real-time breaks all three. Events arrive out of order. Compute behaves like a service. And reruns can produce double counts because downstream systems have already reacted.
A simple modernization map helps teams avoid arguing about tools:
+---------+ +-------------+ +------------------+ +------------------+
| Sources | --> | Event stream | --> | Continuous jobs | --> | Curated tables |
+---------+ +-------------+ +------------------+ +------------------+
| |
v v
Backfill store Consumers
Two rules keep this clean:
- treat the stream as the primary truth path
- treat backfill as a first-class feature, not a rescue plan
That is what turns AWS real-time pipelines into a dependable pattern, not a demo. It is also the practical heart of streaming modernization.
A migration path that does not break reporting
Trying to rewrite everything at once is the fastest way to stall. A safer path is three moves.
- Move 1: mirror the batch outputs in near real-time
Keep the same target tables and reports but refresh them continuously. Stakeholders get faster data without a dashboard rewrite.
- Move 2: change the contract from “replace” to “increment”
Batch pipelines rely on full table replacement, while real-time systems require append and upsert patterns. Consumers must adapt to working with incremental updates.
- Move 3: create new live views
Once incremental data flows are stable, unlock net-new outputs such as instant inventory visibility, fraud signals, or real-time “order stuck” alerts.
One practical guideline: do not judge success by the first live chart. Judge it by how calmly you can operate AWS real-time pipelines during incidents, and how consistently streaming modernization improves freshness without breaking trust.
A quick readiness test: can you pause the nightly chain for a day without chaos? If not, run hybrid for longer and keep both lanes.
Governance and access with Lake Formation
When data moves faster, mistakes spread faster too. Governance cannot be a later ticket. Lake Formation gives you a central place to manage permissions, apply fine-grained controls, and keep audit trails consistent across your data zones.
Keep the setup lightweight and useful:
- define zones: raw, curated, and analytics
- agree on dataset owners and approval flow
- tag sensitive fields early, especially identity and finance data
One tip that saves weeks: start with the highest-risk datasets first, then expand. Governance succeeds when it reduces confusion for engineers and auditors, not when it aims for a perfect catalog.
Designing continuous jobs that behave well
Real-time processing is not “batch, but faster.” It needs different failure handling. Three concepts matter most.
- Idempotency: If the same event is processed twice, results should not double. Use deterministic keys and merge logic where needed.
- Event-time thinking: Process based on when an event happened, not only when it arrived. Late events are normal, especially for mobile and partner systems.
- Quality checks as code: Define checks for schema, nullability, and allowed values inside the pipeline. Do not rely on manual review of dashboard anomalies.
A small diagram for late data policy:
Time axis ------------------------------------------------------------>
[fast window] [correction window] [frozen]
updates late arrivals stable facts
The “correction window” is where backfill and replay live. This is why the two-lane design matters.
Common batch-to-stream pitfalls and how to avoid them
Teams that come from batch often copy their old habits into a new runtime. Here are issues we see repeatedly, plus a fix that is easy to apply.
- Treating the stream like a file: If you read a stream and wait for “the end,” you will recreate batch delay. Instead, decide what “done” means per time window, then emit partial results and allow later corrections.
- Assuming ordering: Many systems deliver events out of order. Build using event time and keys, not arrival sequence. If a join depends on ordering, reconsider the join or store interim state explicitly.
- “Just replay everything” as a recovery plan: Replays can flood downstream systems, and they can change results in ways business users cannot explain. Keep replays controlled, with a clear start time, clear reason, and a way to validate deltas before publishing them widely.
- Mixing business logic with plumbing: When every pipeline has its own rules, fixing a bug becomes a hunt. Pull shared logic into libraries or services, and keep the pipeline code focused on flow control, validation, and writing.
- No observability beyond job status: A green job can still be wrong. Track freshness, late-event rate, duplicate rate, and error types by source. When a number moves, you should know where to look first.
These patterns are not theoretical. They are the difference between a system that runs quietly and one that wakes people up at night.
Building EMR pipelines for streaming workloads
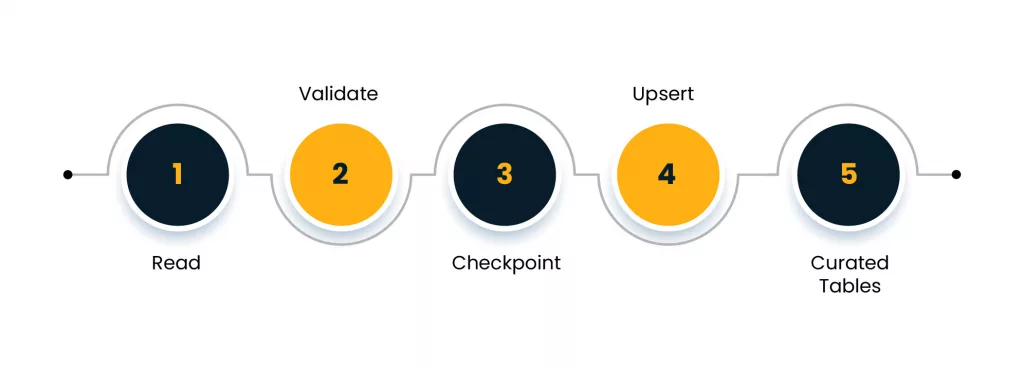
EMR is often used for Spark batch jobs, but it can also run streaming patterns when you design with checkpoints and state control. The intent is simple: keep the job restartable, keep state bounded, and write outputs that consumers can trust.
A practical job blueprint:
- read from the stream
- validate and enrich
- checkpoint progress
- write to curated tables using upserts for key entities
Common pitfalls and fixes:
- duplicates: use a unique event id, then dedupe on write
- late data: set a watermark policy that matches business reality
- enrichment joins: cache slow lookups or move them to a small reference table
Used this way, teams keep familiar with Spark logic while switching to continuous triggers.
Storage contracts for a data lakehouse
A data lakehouse layout works well for continuous data because it supports both frequent writes and analytic reads with clear contracts. Keep your zones explicit and predictable.
Suggested layout:
- Raw: immutable, “as received,” partitioned by arrival date
- Curated: standardized, keyed by business ids, supports merges
- Analytics: aggregates and serving tables for BI and apps
Two practices prevent pain:
- separate facts from derived signals
- treat schema changes like API changes, with reviews and tests
ETL modernization without the rewrite tax
Most organizations have years of logic baked into ETL jobs. Throwing it away is risky and rarely necessary. ETL modernization should focus on changing execution patterns and operational controls, while preserving business rules.
A simple classification helps:
- simple cleans and mappings: good candidates for continuous processing
- heavy joins: stream into curated tables, then enrich on a short schedule
- complex rules: extract shared logic so both lanes can reuse it
A short checklist:
- define how state will be stored
- define replay and backfill steps, including “how far back”
- define what “correct” means for each output, not just “complete”
How to cut over without losing trust?
During the parallel run, compare more than total. Compare the shape of the data over time. Look for gaps by hour, spikes in late arrivals, and unexpected duplicates. Keep a small “truth set” of hand-verified records and replay them through both paths after every change.
A simple cutover checklist:
- validate counts and key metrics by time window
- validate joins by sampling known entity ids end to end
- validate access rules for each consumer group
- rehearse one backfill and one replay before go-live
When these checks are routine, AWS real-time pipelines stop feeling risky. That confidence is what makes streaming modernization stick after the first release.
A six-week start plan
Week 1: pick one workload with clear value from fresher data
Week 2: define event schema and curated output contract
Week 3: build the continuous job with checkpoints and quality checks
Week 4: wire in access controls and auditing
Week 5: run in parallel with batch and compare results
Week 6: cut over one consumer, then add more
Closing thought
Batch jobs were built for a world where waiting until morning was fine. Your users are not waiting anymore. With a two-lane design, clear contracts, and disciplined operations, you can move from nightly chains to continuously updated data.
That is the point of AWS real-time pipelines. That is what streaming modernization should deliver.
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.