




















If your business deals with data on a daily basis, you’ve likely hit challenges with scale, speed, or reliability.
In fact, making data usable takes more than just storing it, be it:
- Sales metrics,
- Product usage, or
- Customer behavior data
The question is: how do you make that data accessible, reliable, and useful at all times?
Here’s the answer: DATA ENGINEERING
So, what is data engineering? It’s the discipline focused on building systems that collect, move, store, and clean your data so your teams can access it when and how they need it. These systems help organizations work with data in real-time or in bulk across departments and tools.
Why Businesses Invest in Data Engineering
Most growing businesses collect data from many sources—applications, websites, CRMs, internal tools, third-party APIs, and more. However, the problem is, this data usually isn’t consistent, complete, or ready to use out of the box.
| Challenge | How Data Engineering Solves It |
| Disconnected and messy data from various sources | Standardizes data into consistent formats |
| Difficulty in accessing reliable, usable data | Organizes data into structured systems for easy access |
| Delays in analytics, reporting, or model outputs | Delivers structured data to analytics tools, BI dashboards, machine learning models, and reports |
| Slow or uncertain decision-making | Enables business leaders to make fast, confident, and data-backed decisions |
Core Components of a Strong Data Engineering Setup
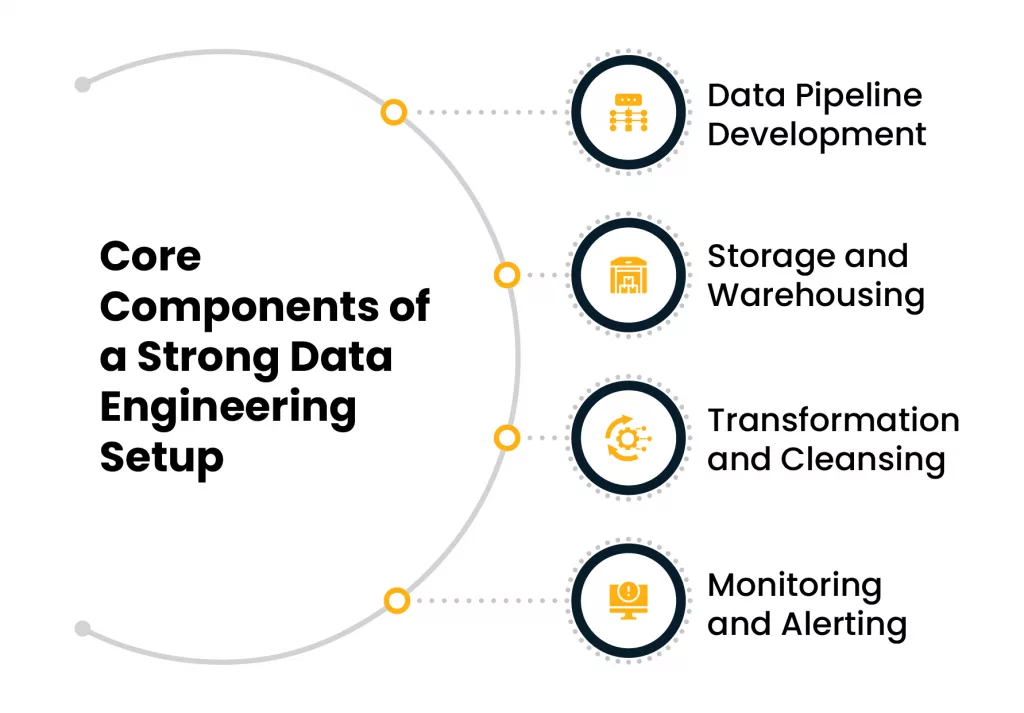
Data Ingestion
Collecting data from APIs, databases, files, and real-time sources.
Data Pipeline Development
Creating reliable, automated processes that transport and transform raw data into usable formats.
Storage and Warehousing
Organizing structured data in scalable systems like Snowflake, Redshift, or BigQuery.
Transformation and Cleansing
Filtering, joining, reshaping, or correcting bad data before it reaches your teams.
Monitoring and Alerting
Detecting pipeline failures, slow queries, or bad inputs before they affect operations. Each step plays a role in delivering timely, high-quality data to the people who depend on it.
Struggling with Data Chaos?
Let Cygnet One design and implement robust data pipelines and governance frameworks to turn your data into a strategic asset.
Contact Us
How Does This Translate to Business Value?
A well-implemented data engineering strategy helps reduce operational risks and creates clarity across the business.
- Sales teams get updated customer data
- Finance accesses clean financial reports
- Marketing pulls segmented audiences
- Product teams analyze user behavior trends
All without waiting days or writing manual scripts. Data pipeline development automates what many businesses try to do by hand.
When to Work with Data Engineering Consulting Firms?
For most businesses, hiring a full internal team of data engineers isn’t always practical—especially if your needs are project-based or involve a one-time buildout.
That’s where data engineering consulting firms come in. These firms offer access to senior experts without long-term overhead. Their teams typically support:
- System Architecture Design – Planning data systems from the ground up
- Data Pipeline Development – Implementing pipelines that move and transform data reliably
- Ongoing Optimization and Support – Fixing performance issues, updating systems, and providing maintenance
For businesses migrating to the cloud or moving from legacy systems, these firms can save months of trial and error.
What to Look for in a Data Engineering Partner?
Before choosing a firm, ask these questions:
- Do they understand our industry-specific needs?
- Can they build systems that work with our current tools?
- Do they have experience handling data volumes like ours?
- Will they provide documentation and training?
- Can they offer flexible support models after launch?
Top-tier data engineering consulting firms provide not just technical solutions but long-term reliability. That matters when data is a core part of how your business operates.
Data Engineering Case Study: Shopify Solves Enterprise-Scale Data Discovery
Shopify, one of the world’s leading eCommerce platforms, experienced rapid data growth across its ecosystem. Then, this growth created complex challenges around data discoverability, governance, and accessibility.
So, with data assets growing exponentially and scattered across multiple systems and teams, Shopify needed a scalable data engineering solution.
The Challenge
Shopify’s teams were facing major obstacles around:
- Discovering existing data assets (datasets, reports, dashboards, etc.)
- Understanding the ownership and downstream impact of data changes
- Surfacing accurate and reliable metadata for reporting and analysis
- Reducing repetitive work caused by duplicated data efforts
Before the solution, 80% of Shopify’s data team reported that their ability to deliver was blocked by inefficient data discovery processes.
The Solution: Building “Artifact”
To address these problems, Shopify built Artifact, a metadata-driven data discovery and management tool. The solution was built entirely in-house by their data engineering and platform teams.
Artifact enabled teams to:
- Search and browse all data assets (including dashboards, models, jobs, and tables) across the organization
- Access ownership details, schema documentation, and lineage for each data asset
- Understand transformation logic, usage patterns, and dependencies
- Standardize metadata ingestion pipelines across internal tools and systems
- View upstream/downstream lineage using a graph database integrated with Elasticsearch and GraphQL
Business Impact
Since launching Artifact in early 2020, Shopify has:
- Reduced dependency on the central Data team by empowering teams to self-serve data
- Improved productivity, with over 30% of the Data team using the tool weekly
- Increased metadata visibility, cutting down duplication and manual requests
- Achieved a monthly retention rate of over 50% among internal users
- Elevated governance and change management awareness across departments
The Growing Role of Real-Time Data
More businesses are moving away from batch reports and toward real-time analytics. This requires data infrastructure that can handle constant input without breaking.
Modern data engineering focuses on:
- Stream processing
- Event-driven pipelines
- Automation to deliver real-time insights
This is especially beneficial in industries like eCommerce, fintech, healthcare, and logistics.
Even small delays in data can lead to missed opportunities or poor decisions. That’s why many companies now prioritize data engineering as a core IT function—not just a backend process.
What is Data Engineering in the Context of Cloud and Scale?
With more companies migrating to the cloud, data engineering strategies now need to support scale, multi-cloud environments, and compliance. The rise of data lake houses, warehouse-lake integrations, and zero-copy data sharing adds more layers of complexity.
If your team is dealing with siloed data, storage limits, or performance bottlenecks, it’s time to revisit your architecture.
Modern cloud-native data engineering approaches help reduce cost, increase uptime, and give your team direct access to the information they need—without manual workarounds.
Ready to Scale Your Data Infrastructure?
Talk to Cygnet One’s data engineering experts to plan and scale your data systems for cloud-native and multi-cloud environments.
Book a consultation NowGetting Started with Data Engineering the Right Way
If you’re unsure where to begin, start with a data audit. Identify where your data lives, who uses it, and what problems they face. From there:
- Map key data sources and define what “clean” means for your business
- Identify where current pipelines are breaking or missing
- Estimate the cost of outages or delays caused by poor data flow
- Talk to data engineering consulting firms to assess your architecture
However, if you want to skip all these steps, you can hire a professional firm.
How Cygnet.One Enhanced Expense Prediction Workflow for a B2B Finance Solution Provider?
Client: A US-based B2B finance solution provider
Challenge: The client faced challenges in accurately predicting expenses due to fragmented data sources and lack of a centralized system, leading to inefficiencies in their financial forecasting processes.
Solution: Cygnet.One implemented a centralized, revenue-centric data management system. This involved:
- Combining disparate data sources into a unified platform
- Implementing robust data pipelines for real-time data processing
- Utilizing advanced analytics to enhance expense prediction accuracy
Outcome: The centralized system streamlined the client’s expense prediction workflow, resulting in improved forecasting accuracy and operational efficiency.
Start Your Data Engineering Journey with Cygnet.One!
Getting data engineering right is critical to building a smarter, more scalable business.
As your business becomes more data-driven, understanding what data engineering is—and how it fits into your operations—is the first step. Clean, accessible, and real-time data isn’t just helpful anymore; it’s expected.
At Cygnet.One, we work with businesses like yours to turn complex data environments into scalable, secure, and intelligent ecosystems.
How do we help?
- Technical Due Diligence: Assess your current digital maturity and define a clear roadmap for transformation
- Product Engineering: Build and evolve future-ready digital products aligned with your business goals
- Application Modernization: Upgrade legacy systems into agile, scalable, and secure platforms
- Hyperautomation Solutions: Streamline operations by automating complex workflows and integrating intelligent systems
Let’s help you move forward—strategically, securely, and on a scale.
Author


Yogita Jain
Content Lead
Yogita Jain leads with storytelling and Insightful content that connects with the audiences. She’s the voice behind the brand’s digital presence, translating complex tech like cloud modernization and enterprise AI into narratives that spark interest and drive action. With a diverse of experience across IT and digital transformation, Yogita blends strategic thinking with editorial craft, shaping content that’s sharp, relevant, and grounded in real business outcomes. At Cygnet, she’s not just building content pipelines; she’s building conversations that matter to clients, partners, and decision-makers alike.