




















Big programs stall when planning drifts away from code reality. Dependency chains surprise you. Release windows shrink. People avoid touching brittle areas because they fear outages. You need a way to read the estate, sort the noise, and move in steps that bring visible wins without breaking core flows.
This post shows how to use AWS Transform for complex apps with a playbook that respects those constraints. We will focus on what the service is good at, how to map legacy complexity, how to combine it with the right tools and partners, and a set of success patterns you can apply right away. The goal is clarity you can put in a plan this week.
Understand AWS Transform in plain terms
AWS Transform is about creating a fact base at scale. It reads repos, build artifacts, and operational signals. Then it surfaces dependency graphs, effort ranges, and work items. It gives you a consistent way to talk about scope across teams that see the same code differently.
Think of it as a coordinator for early heavy lifting. Not another dashboard that repeats what you already know. With it, you can set a baseline before arguing about tactics. That baseline shapes a backlog your teams can actually close.
Core outcomes you should expect
- An inventory of applications that is tied to code, not stale spreadsheets
- Dependency views that make upstream and downstream effects explicit
- Hotspot markers for brittle areas, dead libraries, and risky integrations
- Estimated work items with clear boundaries, owners, and effort bands
- Artifacts you can version and review like any change to your product
Use AWS Transform for complex apps to get that shared language. It keeps arguments grounded in code and runtime facts rather than opinions.
Map legacy complexity with discipline
Tools help, but they do not make the hard calls for you. You still need a clear map. Build it with lenses that cut through politics and habit.
Five lenses that work
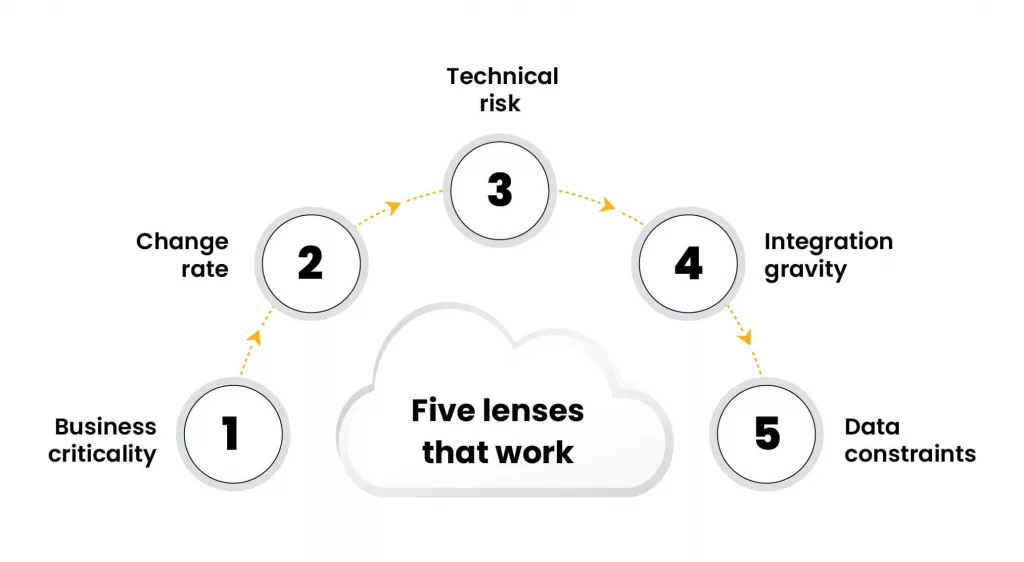
- Business criticality. What affects revenue or compliance if it fails
- Change rate. What ships often, what ships rarely, and why
- Technical risk. Unsupported runtimes, fragile dependencies, noisy incidents
- Integration gravity. Systems with many inbound and outbound calls
- Data constraints. Size, latency, lineage, and regulatory rules
Now segment the estate. Avoid all-or-nothing thinking. Use a portfolio view that mixes stability, standardization, and targeted change—guided by your cloud modernization strategy.
A pragmatic segmentation
- Stabilize and move. Shift as-is to reduce noise and stop the bleeding
- Containerize. Standardize builds and releases for fast, consistent rollouts
- Targeted application refactoring where reliability or cost cannot meet goals
- Retire and archive when usage and value no longer justify upkeep
Feed the outputs from AWS Transform for complex apps into this map. The data helps you size slices, order work, and call out hidden coupling before it bites you during cutover.
Use tools and partners where they actually help
No single product moves a complex estate. Success comes from a small set of tools that your teams know how to run well. Pair that with partners who anchor governance, delivery, and change management.
Tool-by-task pairing
- Lift and stabilize first. Use replication and minimal-change moves to a steady baseline. This quiets the noisy hosts so you can see real signals.
- Containerize existing apps. Capture running processes and produce images plus deployment templates. This gives you consistent CI, predictable rollouts, and fewer snowflake servers.
- Incremental services. Use a routing layer so new services can run alongside existing endpoints. This reduces risk while you carve out logic over time.
- Data moves. Plan for schema conversion, change data capture, and rehearsal windows. Do not treat data as an afterthought.
Keep the catalog thin. Teams lose time when they jump between overlapping products. A focused set of AWS migration tools used well beats a wide shelf of tools used rarely.
Where partners fit
Partners help stitch process with platform. They codify account baselines, identity, and network rules. They harden CI and artifact flows. They coach teams through the first waves so your playbook becomes repeatable. Set a clear RACI and hold it.
Governance that keeps speed
- Standard account patterns and guardrails
- Pipelines that produce signed, traceable artifacts
- Cost controls that alert early without drowning engineers
- Observability with one pane for logs, metrics, and traces
- Risk reviews aligned to release cadences, not separate from them
Use AWS Transform for complex apps as your single source of truth for scope and progress. Pair it with a short list of AWS migration tools that mirror how your teams already ship. Add cloud modernization for the shared services that unblock everyone, such as identity, observability, and eventing.
Success stories and tips you can apply now
Patterns below are drawn from real programs. Names change. The friction and the fixes are consistent.
Pattern A. Stabilize first, then standardize
Context
A noisy virtualized estate. Hundreds of VMs. Release processes vary by team. Incident rates erode trust.
Approach
- Inventory with AWS Transform for complex apps to surface hotspots and coupling
- Move low-risk tiers to a steady baseline with minimal change
- Containerize high-churn services to reduce drift and speed rollouts
- Consolidate logs and metrics before deeper changes
- Set error budgets per domain to guide pace
What changed
- Incidents dropped in the first two waves
- Release frequency increased after standard CI landed
- Teams stopped chasing configuration drift and focused on backlog
Tips
- Rehearse cutovers until they feel routine
- Use the same runbooks for every wave
- Publish a heat map so everyone understands priorities
Pattern B. Carve out features without a risky big bang
Context
A monolith runs a customer portal. It bundles identity, billing, and content. Any change risks breaking something important.
Approach
- Front the stack with one stable entry point
- Carve a read-heavy feature into a new service
- Route a small slice of traffic to the new service
- Watch error budgets and raise traffic only when steady
- Repeat for the next feature slice
What changed
- New services shipped without long freezes
- Teams measured steady gains rather than debating dates
- The public endpoint stayed stable for customers
Tips
- Tie every routing change to SLOs, not hope
- Keep rollback simple and fast
- Announce traffic ramps during business hours with clear owners
Pattern C. Mainframe or batch heavy estates without drama
Context
Batch windows and COBOL live at the core. Few engineers want to touch it. Risk tolerance is low.
Approach
- Use AWS Transform for complex apps to expose code structure and dependencies
- Treat each batch as a product with clear SLOs and playbooks
- Stage data changes with conversion and CDC rehearsals
- Add synthetic checks around cutovers
- Document every exception to policy
What changed
- Leadership saw a plan tied to evidence, not slogans
- Risk grew smaller with every window
- Knowledge spread beyond the small group of specialists
Tips
- Write down every manual step and automate later
- Pair experienced engineers with newcomers so knowledge spreads
- Keep change windows small and frequent
Checklists you can reuse
Discovery and planning
- One inventory source tied to code
- Risk labels on every item
- Effort bands with a range and an owner
- Clear “done” criteria per wave
- A weekly program review that stays focused on outcomes
Platform and operations
- Golden images and base templates
- IaC for accounts, clusters, and pipelines
- Signed artifacts with traceability
- Central observability with standard dashboards
- Simple budget alerts that trigger action, not noise
Team habits
- Short retros that update heuristics
- A debt ledger with a weekly paydown cap
- Ratio of build time to meeting time that favors makers
- One source of truth for status updates
- A playbook that anyone can follow
A few diagrams to keep the model clear
From discovery to delivery
[Portfolio Intake] --> [Code and Signal Scan] --> [Backlog Items]
| |
v v
[Risk and Effort Bands] --> [Wave Plan]
|
v
[Execute] -> [Cutover]
|
v
[SLO Watch and Retro]
Routing while you carve features
[Clients]
|
[Stable Entry]
| \
| \--->[New Service]
v
[Existing App] Wave loop
Plan -> Rehearse -> Execute -> Verify -> Learn -> RepeatKeep these visuals visible in rooms where decisions happen. They ground debates in a shared model.
FAQ style guidance for common pushbacks
“Why not redesign everything and do it right once?”
Because long freezes kill momentum. Slices create steady wins. They also surface surprises early while the blast radius is small.
“Do we really need to containerize now?”
Not always. Use it when release friction slows teams or when configuration drift keeps creating incidents. If a service is stable and low risk, move it as-is and revisit later.
“Can we skip data planning until the end?”
Do not. Data changes bite late and hard. Treat schema conversion and CDC as first-class work with rehearsals and rollbacks.
“How many tools are too many?”
If you cannot explain who owns each tool and when it runs in the wave, you have too many. A focused kit wins. Tie it to how you already ship.
“How do we keep leadership aligned?”
Publish a weekly one-page update. Show slice goals, risk retired, incidents, and spend. Keep it boring and predictable.
Bringing it together
You win by turning discovery into steady delivery. Use AWS Transform for complex apps to anchor scope and expose coupling early. Let the data shape a backlog that moves in two-to-four-week slices. Pair the plan with a small set of tools you know how to run well. Bring partners in to harden guardrails and delivery flow. Add cloud modernization for shared services that unblock every team. Reserve time for targeted application refactoring where straight moves cannot meet your goals.
When this loop runs, engineers stop firefighting and start shipping. Risk drops without long freezes. Audits get easier because artifacts tell the story.
Two final points to keep teams honest
- Keep slice size constant. Big slices slip. Tiny slices feel busy but change little. Aim for a size that fits inside a normal sprint cadence and still retires a visible risk.
- Protect focus time. The best plan fails if your makers drown in status meetings. Let the backlog and dashboards speak for themselves.
Summary for decision makers
- Use AWS Transform for complex apps as the single source of truth for scope and progress
- Segment the estate with clear lenses that reflect risk and value
- Run a small kit of AWS migration tools that your teams already know
- Add cloud modernization for shared services that unblock everyone
- Plan for targeted application refactoring where needed and protect that time
Done this way, the program feels steady. People can see progress every two weeks. Incidents drop. Releases speed up. Costs become predictable. That is what modern work should look like.
Author


Yogita Jain
Content Lead
Yogita Jain leads with storytelling and Insightful content that connects with the audiences. She’s the voice behind the brand’s digital presence, translating complex tech like cloud modernization and enterprise AI into narratives that spark interest and drive action. With a diverse of experience across IT and digital transformation, Yogita blends strategic thinking with editorial craft, shaping content that’s sharp, relevant, and grounded in real business outcomes. At Cygnet, she’s not just building content pipelines; she’s building conversations that matter to clients, partners, and decision-makers alike.