































A demo can impress in 10 minutes but production has to survive the next 10 months.
That gap is why many teams get stuck after a promising pilot. The model worked. The prompt looked good. People clapped. Then the real world arrived: messy data, changing policies, approvals, latency limits, audit questions, and a hundred small “who owns this?” decisions.
This blog is about crossing that gap with AWS Bedrock deployment done the way enterprise teams actually need it—supported by experienced AWS cloud consulting services—aligned with enterprise generative AI adoption frameworks. Not as a one-off chatbot, but as a repeatable operating model that turns experiments into dependable capabilities.
Why AI pilots stall after the first win?
Most pilots fail for reasons that have nothing to do with model quality.
They stall because the pilot is built like a prototype, but stakeholders judge it like a product.
Common stall points:
- No clear contract for success
The pilot shows “it can answer,” but not “it can answer within policy, cost, and time limits.”
- Data access is informal
Someone exports a file. Someone shares a link. Nobody documents lineage.
- Prompts live in notebooks
There is no versioning, review, or rollout control.
- No path for changes
A single prompt tweak changes outputs. Business users lose trust.
- Risk questions arrive late
Security and compliance teams see it only when someone wants to release it.
- Ownership is unclear
Is it a product feature, an IT tool, or a data platform asset?
Here’s the core issue: pilots optimize for “can we?” Production optimizes for “should we, consistently?”
That is why AWS Bedrock deployment needs to start with a production mindset even when you are still experimenting.
The PoC-to-production bridge: treat it like a “production contract”
A useful USP for operational AI is this: define a production contract early, and make every pilot artifact map to it.
Think of the contract as a short checklist that forces clarity.
The production contract (practical version)
- Purpose and boundary
- What task does the AI do?
- What does it refuse to do?
- Inputs
- Allowed sources
- Sensitive fields to block or mask
- Outputs
- Required format
- Citations required or not
- Disallowed content
- Quality
- Accuracy target for priority intents
- “Good enough” thresholds for long-tail queries
- Safety and policy
- Content filters
- Data handling rules
- Latency
- p95 response time target
- Cost
- Budget per request or per day
- Change control
- How prompts and retrieval configs get reviewed and released
- Monitoring
- What you log, what you alert on, what you never store
Once this contract exists, AWS Bedrock deployment becomes a structured journey: every iteration closes a contract gap.
A production-ready architecture pattern that teams can repeat
Operational AI needs two layers: a product layer users touch, and a reliability layer teams operate—mirroring cloud-native architecture design principles.
Here is a reference pattern you can adapt:
[User / App]
|
v
[API Gateway + Auth]
|
v
[Orchestrator Service]
| | |
| | +–> [Policy checks + PII redaction]
| |
| +–> [Retrieval layer: curated sources + indexing]
|
+–> [Bedrock Model Invocation]
|
v
[Post-processing]
(formatting, citations,
refusal rules)
|
v
[Response + Logs]
The orchestrator is the real product
Bedrock is the model layer. The orchestrator is where your real differentiation lives.
It controls:
- Routing between tasks (summarize, extract, draft, classify)
- Tool calls (search, CRM lookup, internal KB)
- Prompt templates and versioning
- Response formatting and guardrails
This is where enterprise AI workflows become consistent, testable, and maintainable—especially when designed using reliable multi-agent workflow patterns. And it is where most teams should invest engineering efforts.
Foundation model choice is a policy decision, not just a benchmark decision
Teams often pick a model based on a one-time evaluation. In production, model choice is tied to:
- Data sensitivity
- Prompt length and context needs
- Cost ceilings
- Response determinism needs
- Language coverage
Since foundation models differ across these dimensions, treat model selection like a controllable configuration. Do not hard code it into the application.
A healthy AWS Bedrock deployment makes model selection a governed setting with documented trade-offs.
Building enterprise AI workflows that do not break under real usage
The fastest path to production is not “bigger prompts.” It is a workflow design.
A useful mental model is: inputs → constraints → reasoning steps → output format.
Workflow patterns that work well in enterprises
1) Draft + verify loop
- Step A: draft answer
- Step B: verify against retrieved sources
- Step C: return answer with citations or refusal
This reduces hallucinations when paired with controlled retrieval and strict output formatting. It also fits regulated contexts.
2) Extract-then-generate
- Step A: extract facts from sources into a structured schema
- Step B: generate narrative from that schema
This pattern is excellent for reports, proposals, and case summaries. It also makes testing easier because extraction can be validated.
3) Classify-then-route
- Step A: classify intent and risk level
- Step B: route to the right prompt template and policy checks
This prevents one “do everything” prompt from becoming a fragile mess.
These patterns are the backbone of enterprise AI workflows that can be owned by teams long-term, not just by a single prompt expert.
Security and AI governance that does not block delivery
The goal of AI governance is not to slow teams down. It is to make decisions repeatable and auditable.
A practical governance loop looks like this:
[Policy] -> [Build controls] -> [Release] -> [Monitor] -> [Review] -> [Policy updates]
What to govern in an AWS Bedrock deployment?
Data handling
- Which sources are approved for retrieval
- Redaction rules for sensitive data
- Retention rules for logs and traces
Prompt and workflow change control
- Version prompts like code
- Require review for high-risk changes
- Use staged rollouts and canaries
Model use policy
- Approved foundation models per risk tier
- Allowed tasks per tier
- Rules for tool use and external calls
Output safety
- Refusal templates for restricted requests
- Controlled tone for customer-facing use
- Content filtering tuned for your domain
Audit readiness
- Traceability from response to sources
- Evidence of tests run before release
- Clear ownership and escalation paths
A common mistake is treating AI governance as paperwork. A better approach is governance-as-controls: enforce policy through systems, not meetings.
When controls are part of the architecture, AWS Bedrock deployment moves faster because approvals stop being mysterious.
Testing and monitoring: what most teams miss
Traditional software tests assume deterministic outputs. Generative AI is probabilistic. That does not mean it is untestable.
It means you test different things.
What to test?
- Retrieval quality
Are the right documents being pulled for the right queries?
- Format compliance
Does the output match required structure every time?
- Refusal behavior
Does it refuse restricted requests reliably?
- Regression suites for top intents
Does a prompt change break key business tasks?
- Cost and latency budgets
Do you stay within spend and response targets?
Monitoring that actually helps operators
Track signals that map to user trust and operational risk:
- Citation coverage rate (if citations are required)
- Refusal rate by intent and user group
- Retrieval “empty result” rate
- p95 latency by workflow type
- Cost per request by route and model
- User feedback tags tied to prompt versions
This is how enterprise AI workflows become maintainable systems. It is also how AI governance becomes measurable instead of abstract.
Adoption roadmap that avoids the common traps
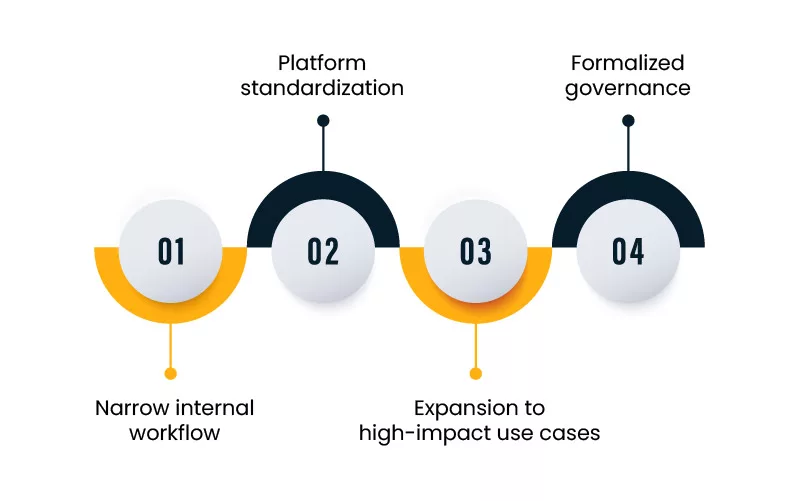
Here is a pragmatic roadmap that works for enterprise teams.
Phase 1: Pick one workflow with a narrow boundary
Choose something like:
- Support summarization for agents
- Policy Q&A with approved documents
- RFP response drafting from a curated corpus
Write the production contract. Build the controls. Ship to a small internal group.
This first AWS Bedrock deployment is about proving operational readiness, much like enterprise cloud transformation initiatives, not feature breadth.
Phase 2: Standardize the platform pieces
Create shared components:
- Orchestrator template
- Prompt registry with versioning
- Retrieval service patterns
- Logging and monitoring standards
- Approval workflow for prompt and model changes
This is where enterprise AI workflows stop being one-off projects.
Phase 3: Expand to higher-impact use cases
Now take on:
- Multi-step workflows
- Cross-system tool calls
- Customer-facing experiences with stricter policies
At this point, you can introduce multiple foundation models by tier, with clear rules about when each is used.
Phase 4: Formalize governance without adding friction
By now, you have operational evidence. Use it to formalize:
- Risk tiers
- Required tests per tier
- Release gates
- Audit packs generated from logs and change records
This is mature AI governance that supports delivery.
A simple way to explain the journey to stakeholders
If you need one slide worth of clarity, use this:
Experiment: “Does it work?”
Production: “Does it work within rules, cost, and time targets?”
Operations: “Can we run it, change it, and prove it?”
That is the real bridge. It is less about bigger models and more about disciplined system design.
When you treat AWS Bedrock deployment as an operating capability, not a demo, you get repeatable delivery. You also earn trust across security, data, and business teams.
And that is how experiments become something people rely on.
Author


Yogita Jain
Content Lead
Yogita Jain leads with storytelling and Insightful content that connects with the audiences. She’s the voice behind the brand’s digital presence, translating complex tech like cloud modernization and enterprise AI into narratives that spark interest and drive action. With a diverse of experience across IT and digital transformation, Yogita blends strategic thinking with editorial craft, shaping content that’s sharp, relevant, and grounded in real business outcomes. At Cygnet, she’s not just building content pipelines; she’s building conversations that matter to clients, partners, and decision-makers alike.
