




















You know an agent is real when it handles the messy parts. It asks for missing inputs, negotiates with another system, retries on failure, and still ships the outcome your team expects. That is the bar when you roll out agents across finance, customer support, procurement, and IT. This guide shows the exact path to get there on AWS, using the broader AWS cloud ecosystem without hype, and with the rigor you need for production.
Before we dive in, a quick point of view. Agentic AI is not just another model integration. It is a system of goals, tools, memory, policies, and feedback. Success depends on the operating model around it: environments, security, observability—supported by a strong cloud strategy and design foundation, and a playbook the business trusts. If that sounds like enterprise AI deployment more than a pure data science project, you are on the right track.
Steps to deploy Agentic AI at scale
Here is a practical rollout that avoids dead ends and keeps you ready for audits and change.
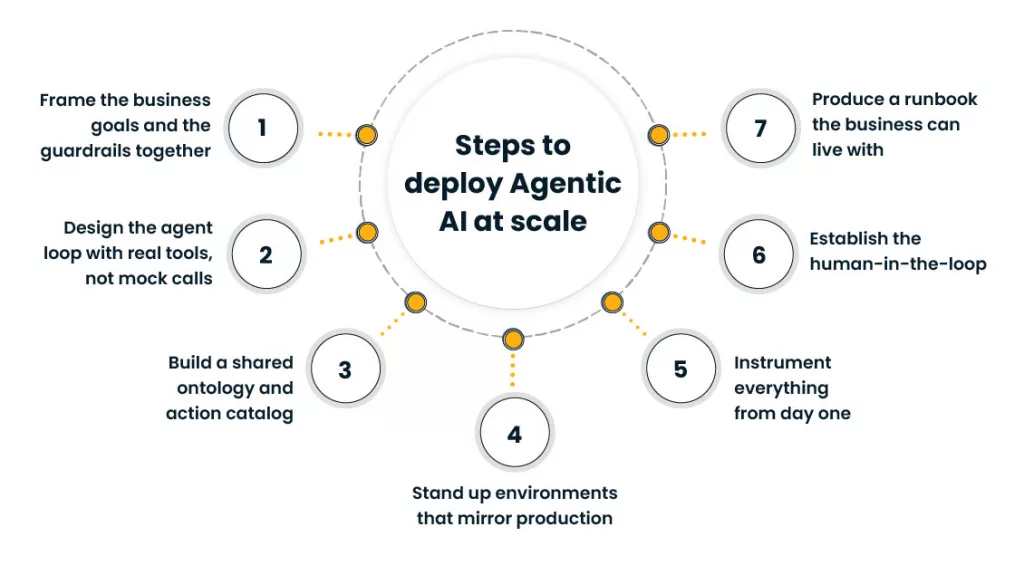
1) Frame the business goals and the guardrails together
- Pick two to three cross-functional use cases with measurable ROI: invoice reconciliation, RFP summarization with sourcing actions, multi-lingual customer reply drafts with policy checks.
- Define success and failure. Include false positive cost, human review time, SLA impact, and safety incidents.
- Write the non-negotiables. Examples: PII must never leave your VPC, agents cannot commit spend over a set limit, all actions tagged with origin, purpose, and requestor.
This is your first act of AI governance. Do it with Legal, Risk, and the data team in the room.
2) Design the agent loop with real tools, not mock calls
Agents that only chat hit walls. Give them tools.
- Tooling mix on AWS: API Gateway endpoints for internal services, Lambda functions for atomic tasks, Step Functions for long-running workflows, EventBridge for orchestration, DynamoDB for short-term memory, and a vector index for retrieval.
- Use Amazon Bedrock for model access with Bedrock Guardrails—part of the broader AWS AI services portfolio and safety filters. Use SageMaker for custom models and evaluators when you need stricter control.
- Wrap tools with idempotency keys, timeouts, retries, and quotas. Expose the same preconditions your human playbooks require.
Keep the loop simple: perceive context, plan, act, check, learn. Then add safety checks between plan and act.
3) Build a shared ontology and action catalog
Your company already speaks in actions: create ticket, approve invoice, schedule call, generate PO, open change request. Catalog these with input schemas, owners, and permissions.
- Store specs in a versioned repo. Generate tool wrappers from specs.
- Map actions to roles. Tie roles to IAM and identity provider groups.
- Add cost tags to each action so finance sees agent spend by function.
This is the difference between a demo and operationalizing Agentic AI in a way that scales.
4) Stand up environments that mirror production
- Separate dev, staging, and prod accounts with AWS Organizations and SCPs.
- Use CI for agent prompts, tools, and policies. Yes, prompts belong in CI with tests.
- Keep models behind a controlled endpoint. Control egress with VPC endpoints, KMS encryption, and data classification at ingress.
5) Instrument everything from day one
Agents without traces are black boxes. Instrument the loop.
- Structured traces per task: prompt, plan, tools called, inputs, outputs, policy results, cost, latency, and final decision.
- Use CloudWatch for metrics and logs, feeding into structured cloud operations and optimization workflows, plus a lightweight evaluator service that scores outcomes with rubric prompts and rule-based checks.
- Send anomalies and safety events to a Security Lake or SIEM.
6) Establish the human-in-the-loop
Start with a graded autonomy scale:
- Level 0: Suggest only
- Level 1: Suggest plus auto-fill forms
- Level 2: Auto-execute under dollar/time caps
- Level 3: Auto-execute with post-hoc review
Make the promotion path explicit. Tie every level to quality gates and incident thresholds. This keeps scalability aligned with risk.
7) Produce a runbook the business can live with
Your runbook should include:
- When agents escalate and to whom
- Rollback steps for each action type
- How to pause a tool across all agents
- What to log for audits and forensics
- How to rotate prompts, keys, and secrets
Treat the runbook like any other production SRE document. It sits at the core of enterprise AI deployment.
Ensure interoperability and security
Agents touch many systems. They must speak a common language, respect permissions, and handle data well.
A reference architecture on AWS
[Identity Provider]
|
[AWS IAM]------------------------+
| |
[Bedrock + Guardrails] [SageMaker Endpoints]
| |
[Agent Service on ECS/EKS or Lambda] |
| |
[Retriever: OpenSearch/Kendra + S3 + DynamoDB]
|
[Action Catalog: API GW + Lambda + Step Functions]
|
[Business Apps: ERP, CRM, ITSM, Procurement, Billing]
|
[EventBridge Bus for cross-domain events]
|
[CloudWatch + Tracing + Security Lake]Interoperability
- Standardize on JSON schemas for action inputs and outputs. Add semantic labels for PII, PCI, and critical fields.
- Publish SDKs for tool usage in Python and TypeScript. Include schema validation and policy checks in the client.
- Use a canonical event format on EventBridge so agents can consume signals across functions without custom glue each time.
Security
- Principle of least privilege with IAM roles per agent persona and per tool. Scope temp credentials using STS with tight session durations.
- Encrypt data at rest with KMS and in transit with TLS. Keep model prompts that contain sensitive context inside your VPC when possible.
- Add static and dynamic checks. Static: pre-execution policy evaluation. Dynamic: runtime content filters, allowlists for external domains, and anomaly scoring.
- Record consent and purpose for each processing step. This supports audits and aligns with AI governance practices.
Data hygiene
- Redact PII before it hits model inputs when not needed. Keep an allowlist of fields that can pass through.
- Use dataset snapshots for evaluation. Stamp each snapshot with lineage and retention rules.
- Create data contracts with upstream systems. Contracts define latency targets, shape of records, and failure handling.
Reliability and cost
- Provision concurrency and backoff for tool calls. Right-size compute for planned volume. This protects scalability under peak load.
- Track model and tool spend per request. Report cost per business outcome, not just tokens or seconds.
Cross-functional alignment and training
Agent programs fail when they live only in one department. You need a shared way of working.
The Agentic COE model
Create a center of excellence with three lanes and clear owners.
- Delivery lane: Owns build, test, and release. Ships use cases to production with shared components and quality gates.
- Safety lane: Defines policies, runs red teaming, and approves autonomy levels. Keeps incident response ready.
- Value lane: Sets KPIs, handles change management, and documents ROI. Reports to the executive sponsor.
This structure is how you sustain operationalizing Agentic AI beyond the first few use cases.
Skills and training plan
- Product managers learn to write task specs and acceptance criteria for agents.
- Analysts learn prompt patterns, retrieval tuning, and evaluator rubrics.
- Engineers learn tool wrappers, Step Functions, and trace debugging.
- Business users learn when to trust, when to review, and how to give feedback.
Run hands-on labs. Use your own data. Practice incident drills that include Legal and Security. This is the human side of AI governance done right.
Change management that sticks
- Start with a small but visible problem that cuts across teams. Example: vendor onboarding where Legal, Security, and Procurement must act together.
- Publish weekly metrics and call out manual work removed and errors avoided.
- Celebrate the first time an agent closes a case end to end under policy. That moment makes the value visible.
A simple USP you can adopt now: the Agent Trace Contract
Most teams track prompts and outputs. Few define a contract for every agent action. Do this and your audits get easier, your debugging gets faster, and your teams trust the system.
Agent Trace Contract includes
- Who requested the action and on whose behalf
- Inputs with redaction map
- Tools selected and why
- Policy checks passed or failed
- Evidence of self-check or evaluator score
- Final outcome and any human approvals
- Cost, latency, and tokens where applicable
- Links to logs and artifacts
Store the contract as a JSON document in S3 with lifecycle rules. Index key fields in DynamoDB for quick lookups. Surface it in a small review UI so business users can inspect what happened without asking engineering. This is the backbone for operationalizing Agentic AI in regulated settings.
Quality gates that keep you honest
Add gates before you raise autonomy or scale volume.
- Coverage gate: representative tasks across languages, amounts, and exceptions
- Safety gate: red team pass on prompt injection, data exfiltration, and risky actions
- Regression gate: stable win rate over a baseline and a defined rollback plan
- Performance gate: p95 latency, timeout handling, and idempotency verified
- Cost gate: cost per successful outcome within target
Make the gates automatic in CI. Tie them to a promotion checklist.
Metrics that matter
Pick a short list and keep it stable.
- Business outcomes per week and the percent handled without human correction
- Average time saved per case and total hours saved
- Incident rate and mean time to recover
- Quality score from human reviews and evaluator rubrics
- Cost per outcome and cost avoidance
- Time to onboard a new tool into the action catalog
Publish these in a shared dashboard. Use them to guide cuts or new investments.
Example cross-functional playbook
Customer support
- Triage intents, fetch order and billing context, draft reply, schedule follow-up
- Tools: CRM API, billing API, email service, calendar
Finance
- Match invoice and PO, flag anomalies, request missing docs, post to ERP
- Tools: OCR, ERP API, spend policy service
IT and Security
- Enrich alerts, open ticket with runbook steps, attempt automated fix, document RCA
- Tools: SIEM API, CMDB, ticketing, runbook executor
Procurement
- Summarize vendor RFPs, compare terms, run risk checks, recommend shortlist
- Tools: Document parser, risk scoring, contract repository
Each domain uses the same loop, the same trace contract, and the same evaluation framework. That is how operationalizing Agentic AI stays consistent at company scale.
Common pitfalls and how to avoid them?
Treating prompts like source of truth
Prompts drift. Encode core logic in tools and policies. Keep prompts small and role specific.
Skipping schema validation
Invalid inputs break chains in subtle ways. Validate at every hop and fail fast with helpful errors.
Ignoring cold-start data
Agents need history. Seed memory with known resolutions, templates, and examples. Keep memory size bounded.
Rolling out without a pause switch
You need the ability to stop a tool globally. Build a feature flag and an allowlist for critical actions.
Overfitting to a single model
Abstract model providers. Keep routing logic and evals in your control. This supports future model changes and keeps you nimble on cost.
A short checklist you can copy
- Use cases with ROI, safety limits, and clear stop conditions
- Agent loop with tool wrappers, retries, and policy checks
- Action catalog with schemas, owners, and IAM roles
- Dev, stage, prod with CI on prompts, tools, and policies
- Traces, metrics, and an evaluator service in place
- Human-in-the-loop plan with autonomy levels
- Runbook with rollback, pause, and incident steps
- Agent Trace Contract stored for every action
- Cost per outcome tracked and reported
- Weekly review across Delivery, Safety, and Value lanes
Closing thoughts
If you remember one thing, make it this. The hard part is not the model. It is the system around it. When you focus on contracts, policies, and shared tooling, operationalizing Agentic AI becomes a repeatable motion rather than a series of one-off wins. Do that, and your program grows with confidence, not just speed. That is real scalability your leaders will recognize.
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.