








Building systems powered by multiple AI agents often looks efficient on paper but turns complicated in practice. Teams face duplicated processes, idle compute cycles, and unclear handoffs between agents. The goal is simple: ensure that every agent performs its task, communicates results, and responds to context, without introducing extra cost or operational friction.
That’s the essence of AWS AI orchestration — ensuring agents interact smoothly and scale intelligently. When done correctly, it allows intelligent agents to interact smoothly, share context, and complete distributed workflows through structured orchestration. The advantage is not just performance. It’s about controlling complexity as you scale AI operations.
Defining Coordination Goals
Before bringing in any cloud service, you need clarity on what your coordination framework should achieve. In multi-agent coordination with AWS, these goals usually include:
- Task clarity – Each agent should know exactly what it is responsible for.
- Communication flow – Agents must share results and context in a predictable sequence.
- Parallel efficiency – Tasks that don’t depend on each other should run simultaneously.
- Failure isolation – When one agent fails, others continue working.
Example: A Reasoning-Driven Workflow
Think of a generative AI system that answers customer queries. One agent fetches data, another validates it, and a third writes the response. Coordination ensures that the data retrieval agent finishes before the validation agent starts, while the writing agent waits for both.
Without coordination, this same flow would double requests, increase costs, and risk inconsistent responses.
AWS as a Coordination Layer
AWS provides native building blocks that help orchestrate complex, agent-driven workflows without adding heavy middleware. The most effective setup combines three services — Step Functions, EventBridge, and AWS Bedrock — to build scalable coordination layers. Together, they deliver automation, synchronization, and reasoning at scale.
1. AWS Step Functions: Structured Workflow Orchestration
AWS Step Functions act as the backbone for multi-agent coordination with AWS, defining how each agent interacts within workflows. They define and manage how each agent interacts within a larger process.
Key functions:
- Represent workflows as state machines — each “state” can trigger a Lambda function or API call that runs an agent.
- Enable parallel branches so multiple agents can operate at the same time.
- Manage retries, error catching, and fallback logic.
- Maintain execution history for visibility and debugging.
In effect, Step Functions make agent management systematic. Instead of relying on agents to signal each other directly, the workflow handles it automatically.
Example structure:
State Machine:
├── RetrievalAgent → ValidationAgent → SummaryAgent
├── Parallel Branch: AnalyticsAgent + PolicyCheckAgent
└── End → Return to SupervisorThis type of orchestration ensures that tasks run in the right order and agents remain loosely coupled.
2. Amazon EventBridge: Event-Driven Communication
When systems grow, agents need to communicate asynchronously. AWS orchestration tools like EventBridge act as the event bus that routes messages between components.
With EventBridge:
- Agents can publish events (e.g., “retrieval_complete”) without knowing who consumes them.
- Other agents subscribe to relevant patterns and trigger automatically.
- Scheduled or conditional triggers can start or pause entire workflows.
This decouples your architecture and supports a resilient event-driven architecture, reducing inter-agent dependencies. It also means you can add or replace agents without editing existing code paths.
3. Amazon Bedrock: Intelligent Agent Implementation
Once orchestration is defined, Bedrock becomes the environment where individual agents live. It supports multiple foundation models and provides the foundation for reasoning, context sharing, and automation.
Bedrock enables developers to:
- Build and deploy domain-specific agents with defined instructions.
- Connect them to tools or data sources through API actions.
- Maintain shared memory so that agents remember previous outputs.
A common design pattern is to create a supervisory agent that coordinates sub-agents through reasoning. The supervisor decides when to trigger retrieval, when to summarize, and how to merge outcomes.
In this structure, multi-agent coordination with AWS isn’t manual — it’s codified logic connecting Bedrock’s reasoning with Step Functions’ orchestration and EventBridge’s signaling.
Designing for Low Overhead
Building a functional system is one thing; keeping it cost-efficient and simple is another. The challenge with multi-agent coordination using AWS is not just scaling, but doing so with cloud cost optimization in mind.
Here are three principles that help maintain balance.
1. Optimize Cost at Every Layer
- Use Express Workflows in Step Functions for high-volume, short-running tasks.
- Choose right-sized foundation models in Bedrock — not every task needs a large model.
- Cache intermediate results in S3 or DynamoDB to avoid repeated inference.
- Monitor execution logs to identify idle states and redundant transitions.
By aligning workflow structure to task duration, you reduce per-state costs while preserving response time.
2. Keep Context Lightweight
Passing massive payloads through orchestration can slow systems down. Instead:
- Store long-term state in DynamoDB or S3.
- Pass only identifiers or summaries between agents.
- Use shared memory features or vector stores for context retrieval instead of raw data passing.
This keeps workflows modular, faster to update, and easier to debug.
3. Simplify Agent Design
Complex agents that try to “do everything” create maintenance problems. Instead:
- Define one purpose per agent.
- Use smaller reasoning chains for focus and transparency.
- Combine results at the supervisor level, not within each agent.
This supports cleaner agent management and makes scaling linear — you can add more specialized agents instead of redesigning the entire system.
Coordinated AI Workflow on AWS
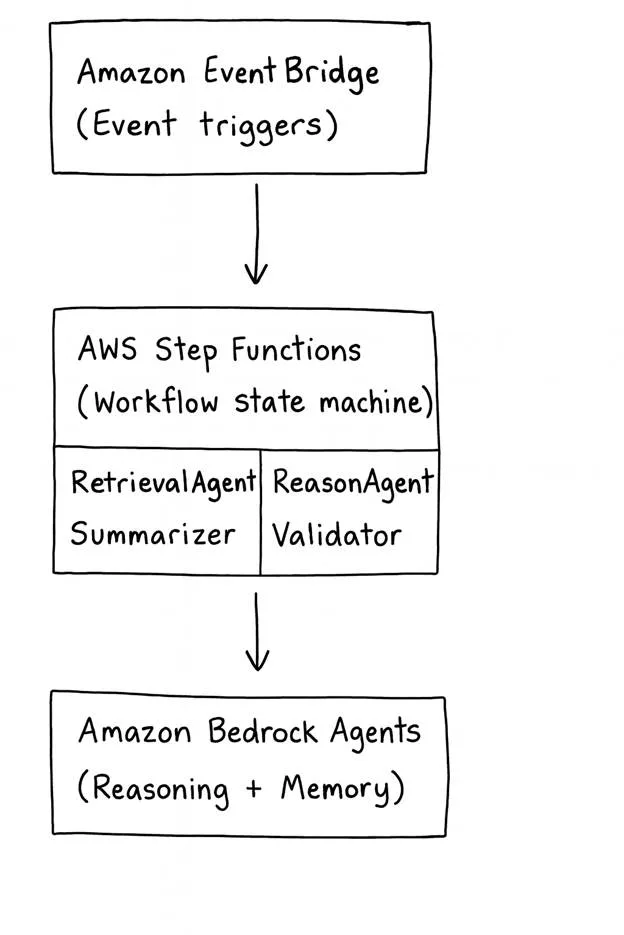
This model illustrates how AWS services combine for event-driven, managed coordination while staying modular and cost-conscious.
Handling Scaling and Reliability
AI Scaling Strategy
As you increase traffic or add new agents, orchestration should adapt automatically. AWS enables this through:
- Parallel states in Step Functions for concurrent execution.
- Lambda concurrency controls to avoid throttling.
- EventBridge rules to queue or delay events under load.
This ensures AI scaling is controlled, not chaotic. Your agents grow in number and scope, but the supervision layer stays stable.
Reliability and Fault Isolation
Every orchestration plan should assume that an agent will fail at some point. To protect the system:
- Use Step Functions’ retry logic with exponential backoff.
- Include fallback states that call simpler backup agents.
- Use EventBridge’s dead-letter queues for unprocessed events.
A coordinated recovery path maintains service continuity while isolating faulty agents.
Putting It All Together
Here’s how these principles come together in a real scenario.
- Trigger – A customer submits a request. EventBridge captures it and triggers a Step Function.
- Workflow Initialization – The Step Function starts the supervisor agent.
- Task Delegation –
- Agent A retrieves data.
- Agent B validates compliance.
- Agent C synthesizes the final response.
- Parallel Execution – Agents A and B run simultaneously. When done, their outputs feed into C.
- Aggregation and Output – The supervisor merges all results and stores them in S3.
The system stays reactive, cost-optimized, and transparent. Each agent performs a single, defined task.
Measuring Effectiveness
How do you know if your coordination design is working? Monitor these metrics:
- Workflow completion time – Shorter runtimes show efficient orchestration.
- Agent utilization – Track which agents remain idle too long or run too frequently.
- Error retry counts – Frequent retries signal dependency or logic issues.
- Cost per execution – Benchmark per 1,000 workflow runs to detect overhead growth.
These metrics align with multi-agent coordination with AWS best practices — visibility, traceability, and performance feedback loops.
Frequently Asked Questions
1. How does this approach differ from traditional orchestration?
Traditional pipelines run in a fixed sequence. Multi-agent workflows are adaptive — agents can run based on conditions or reasoning outcomes. The orchestration doesn’t just call functions; it manages intelligence flow.
2. How can I keep costs predictable as I scale?
Group related agents into workflow segments and run them using AWS orchestration tools that support express executions. Combine small model calls where possible, and monitor Bedrock usage for spikes.
3. What’s the easiest way to start?
Prototype with three agents: one retrieval, one reasoning, and one generation. Use Step Functions for flow control and EventBridge for event routing. Once stable, add more specialized agents.
Key Takeaways
- Multi-agent coordination with AWS is about structured communication, not just automation.
- Step Functions, EventBridge, and Bedrock together create a clear coordination backbone.
- Keep payloads light, agents focused, and workflows modular for smoother agent management.
- Prioritize cost control and transparency while planning for AI scaling.
- Build for fault tolerance — assume agents will fail and design graceful recovery.
Conclusion
Enterprises building AI ecosystems face a consistent problem: coordination overhead. As agents multiply, so do dependencies and costs. The solution lies in clear orchestration, event-driven logic, and modular design. By combining AWS orchestration tools with Bedrock’s reasoning capabilities, you can achieve multi-agent coordination with AWS that is structured, scalable, and sustainable. It keeps agents focused, operations predictable, and growth affordable — without adding layers of complexity that slow innovation.
Author


Abhishek Nandan
AVP, Marketing
Abhishek Nandan is the AVP of Services Marketing at Cygnet.One, where he drives global marketing strategy and execution. With nearly a decade of experience across growth hacking, digital, and performance marketing, he has built high-impact teams, delivered measurable pipeline growth, and strengthened partner ecosystems. Abhishek is known for his data-driven approach, deep expertise in marketing automation, and passion for mentoring the next generation of marketers.